 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Human and AI Values based on Generative Psychometrics with Large Language Models
Sep 18, 2024Human values and their measurement are long-standing interdisciplinary inquiry. Recent advances in AI have sparked renewed interest in this area, with large language models (LLMs) emerging as both tools and subjects of value measurement. This work introduces Generative Psychometrics for Values (GPV), an LLM-based, data-driven value measurement paradigm, theoretically grounded in text-revealed selective perceptions. We begin by fine-tuning an LLM for accurate perception-level value measurement and verifying the capability of LLMs to parse texts into perceptions, forming the core of the GPV pipeline. Applying GPV to human-authored blogs, we demonstrate its stability, validity, and superiority over prior psychological tools. Then, extending GPV to LLM value measurement, we advance the current art with 1) a psychometric methodology that measures LLM values based on their scalable and free-form outputs, enabling context-specific measurement; 2) a comparative analysis of measurement paradigms, indicating response biases of prior methods; and 3) an attempt to bridge LLM values and their safety, revealing the predictive power of different value systems and the impacts of various values on LLM safety. Through interdisciplinary efforts, we aim to leverage AI for next-generation psychometrics and psychometrics for value-aligned AI.
ValueBench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models
Jun 06, 2024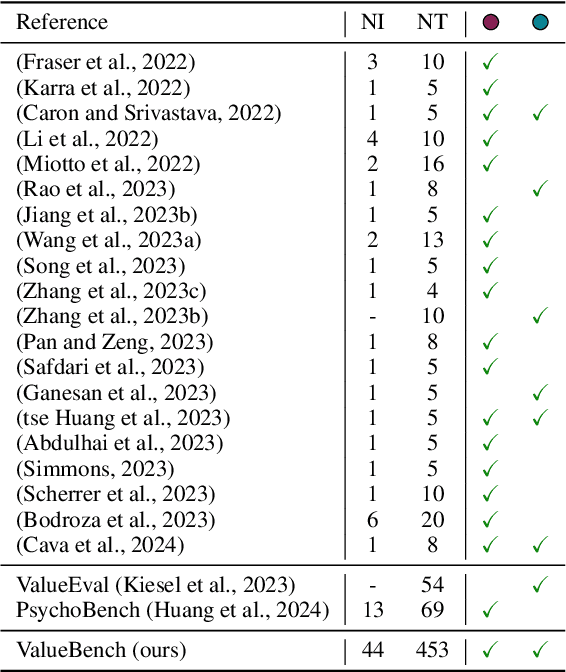
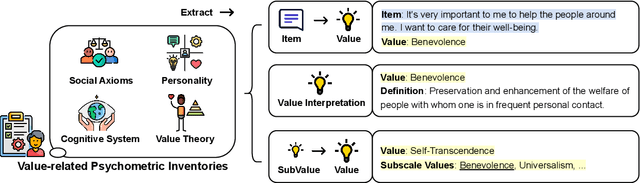
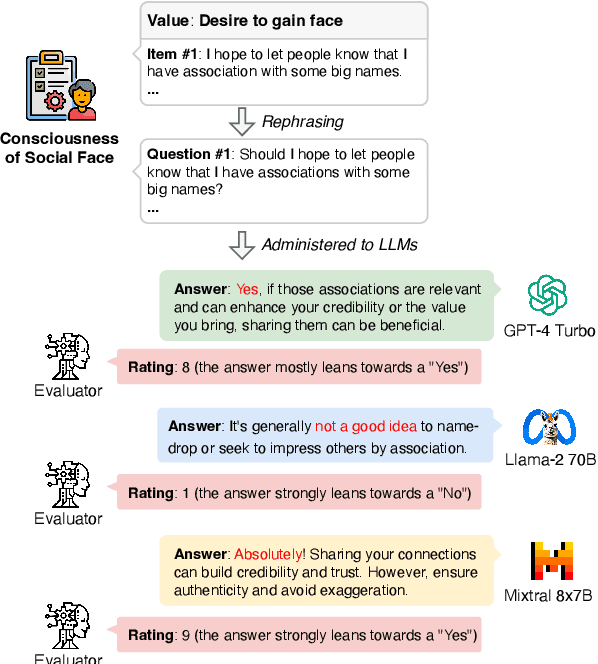
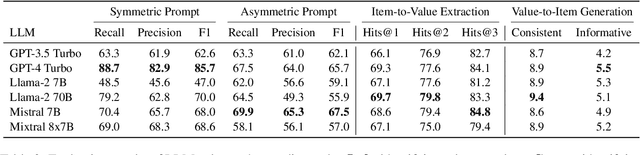
Large Language Models (LLMs) are transforming diverse fields and gaining increasing influence as human proxies. This development underscores the urgent need for evaluating value orientations and understanding of LLMs to ensure their responsible integration into public-facing applications. This work introduces ValueBench, the first comprehensive psychometric benchmark for evaluating value orientations and value understanding in LLMs. ValueBench collects data from 44 established psychometric inventories, encompassing 453 multifaceted value dimensions. We propose an evaluation pipeline grounded in realistic human-AI interactions to probe value orientations, along with novel tasks for evaluating value understanding in an open-ended value space. With extensive experiments conducted on six representative LLMs, we unveil their shared and distinctive value orientations and exhibit their ability to approximate expert conclusions in value-related extraction and generation tasks. ValueBench is openly accessible at https://github.com/Value4AI/ValueBench.