 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
LlamaTouch: A Faithful and Scalable Testbed for Mobile UI Automation Task Evaluation
Apr 12, 2024



The emergent large language/multimodal models facilitate the evolution of mobile agents, especially in the task of mobile UI automation. However, existing evaluation approaches, which rely on human validation or established datasets to compare agent-predicted actions with predefined ones, are unscalable and unfaithful. To overcome these limitations, this paper presents LlamaTouch, a testbed for on-device agent execution and faithful, scalable agent evaluation. By observing that the task execution process only transfers UI states, LlamaTouch employs a novel evaluation approach that only assesses whether an agent traverses all manually annotated, essential application/system states. LlamaTouch comprises three key techniques: (1) On-device task execution that enables mobile agents to interact with real mobile environments for task completion. (2) Fine-grained UI component annotation that merges pixel-level screenshots and textual screen hierarchies to explicitly identify and precisely annotate essential UI components with a rich set of designed annotation primitives. (3) A multi-level state matching algorithm that utilizes exact and fuzzy matching to accurately detect critical information in each screen with unpredictable UI layout/content dynamics. LlamaTouch currently incorporates four mobile agents and 495 UI automation tasks, encompassing both tasks in the widely-used datasets and our self-constructed ones for more diverse mobile applications. Evaluation results demonstrate the LlamaTouch's high faithfulness of evaluation in real environments and its better scalability than human validation. LlamaTouch also enables easy task annotation and integration of new mobile agents. Code and dataset are publicly available at https://github.com/LlamaTouch/LlamaTouch.
FairSIN: Achieving Fairness in Graph Neural Networks through Sensitive Information Neutralization
Mar 19, 2024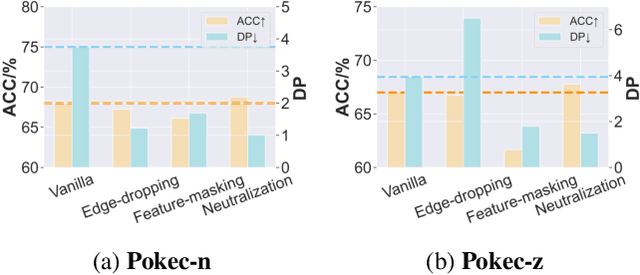
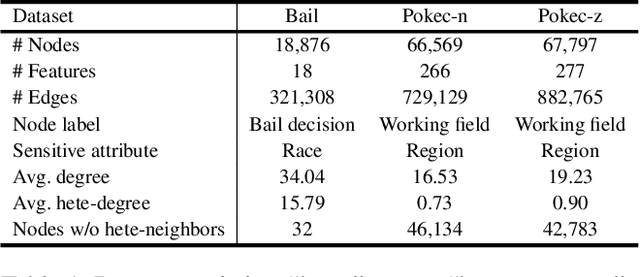
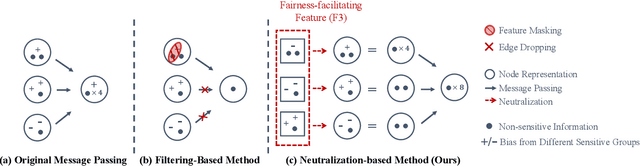
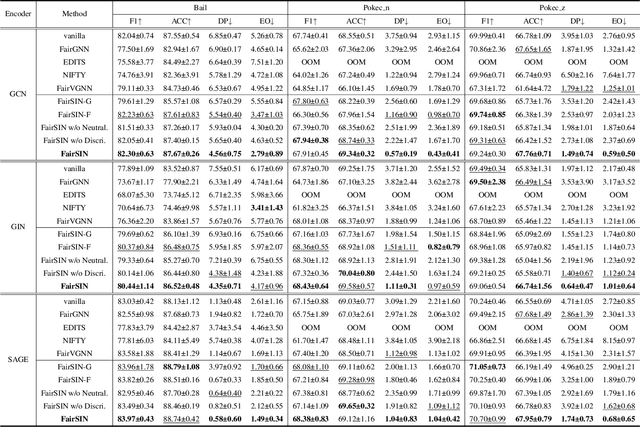
Despite the remarkable success of graph neural networks (GNNs) in modeling graph-structured data, like other machine learning models, GNNs are also susceptible to making biased predictions based on sensitive attributes, such as race and gender. For fairness consideration, recent state-of-the-art (SOTA) methods propose to filter out sensitive information from inputs or representations, e.g., edge dropping or feature masking. However, we argue that such filtering-based strategies may also filter out some non-sensitive feature information, leading to a sub-optimal trade-off between predictive performance and fairness. To address this issue, we unveil an innovative neutralization-based paradigm, where additional Fairness-facilitating Features (F3) are incorporated into node features or representations before message passing. The F3 are expected to statistically neutralize the sensitive bias in node representations and provide additional nonsensitive information. We also provide theoretical explanations for our rationale, concluding that F3 can be realized by emphasizing the features of each node's heterogeneous neighbors (neighbors with different sensitive attributes). We name our method as FairSIN, and present three implementation variants from both data-centric and model-centric perspectives. Experimental results on five benchmark datasets with three different GNN backbones show that FairSIN significantly improves fairness metrics while maintaining high prediction accuracies.