 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairSIN: Achieving Fairness in Graph Neural Networks through Sensitive Information Neutralization
Mar 19, 2024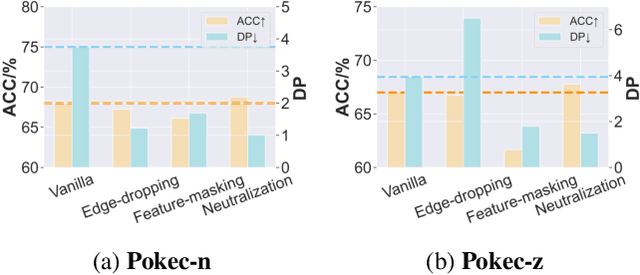
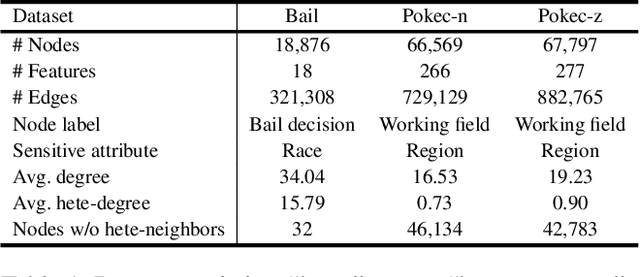
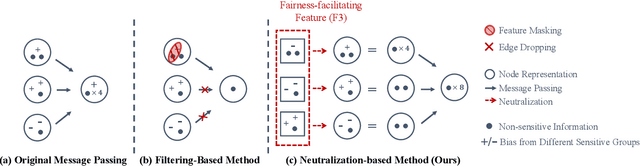
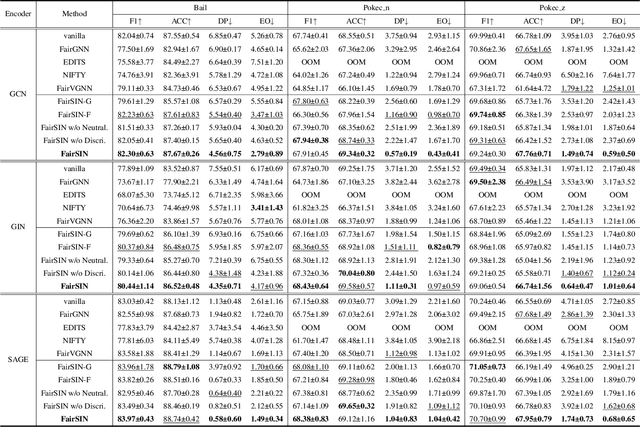
Despite the remarkable success of graph neural networks (GNNs) in modeling graph-structured data, like other machine learning models, GNNs are also susceptible to making biased predictions based on sensitive attributes, such as race and gender. For fairness consideration, recent state-of-the-art (SOTA) methods propose to filter out sensitive information from inputs or representations, e.g., edge dropping or feature masking. However, we argue that such filtering-based strategies may also filter out some non-sensitive feature information, leading to a sub-optimal trade-off between predictive performance and fairness. To address this issue, we unveil an innovative neutralization-based paradigm, where additional Fairness-facilitating Features (F3) are incorporated into node features or representations before message passing. The F3 are expected to statistically neutralize the sensitive bias in node representations and provide additional nonsensitive information. We also provide theoretical explanations for our rationale, concluding that F3 can be realized by emphasizing the features of each node's heterogeneous neighbors (neighbors with different sensitive attributes). We name our method as FairSIN, and present three implementation variants from both data-centric and model-centric perspectives. Experimental results on five benchmark datasets with three different GNN backbones show that FairSIN significantly improves fairness metrics while maintaining high prediction accuracies.
Data-centric Graph Learning: A Survey
Oct 08, 2023


The history of artificial intelligence (AI) has witnessed the significant impact of high-quality data on various deep learning models, such as ImageNet for AlexNet and ResNet. Recently, instead of designing more complex neural architectures as model-centric approaches, the attention of AI community has shifted to data-centric ones, which focuses on better processing data to strengthen the ability of neural models. Graph learning, which operates on ubiquitous topological data, also plays an important role in the era of deep learning. In this survey, we comprehensively review graph learning approaches from the data-centric perspective, and aim to answer two crucial questions: (1) when to modify graph data and (2) how to modify graph data to unlock the potential of various graph models. Accordingly, we propose a novel taxonomy based on the stages in the graph learning pipeline, and highlight the processing methods for different data structures in the graph data, i.e., topology, feature and label. Furthermore, we analyze some potential problems embedded in graph data and discuss how to solve them in a data-centric manner. Finally, we provide some promising future directions for data-centric graph learning.