 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildSVG: Towards Reliable SVG Generation Under Real-Word Conditions
Feb 24, 2026We introduce the task of SVG extraction, which consists in translating specific visual inputs from an image into scalable vector graphics. Existing multimodal models achieve strong results when generating SVGs from clean renderings or textual descriptions, but they fall short in real-world scenarios where natural images introduce noise, clutter, and domain shifts. A central challenge in this direction is the lack of suitable benchmarks. To address this need, we introduce the WildSVG Benchmark, formed by two complementary datasets: Natural WildSVG, built from real images containing company logos paired with their SVG annotations, and Synthetic WildSVG, which blends complex SVG renderings into real scenes to simulate difficult conditions. Together, these resources provide the first foundation for systematic benchmarking SVG extraction. We benchmark state-of-the-art multimodal models and find that current approaches perform well below what is needed for reliable SVG extraction in real scenarios. Nonetheless, iterative refinement methods point to a promising path forward, and model capabilities are steadily improving
Applications of Large Models in Medicine
Feb 24, 2025



This paper explores the advancements and applications of large-scale models in the medical field, with a particular focus on Medical Large Models (MedLMs). These models, encompassing Large Language Models (LLMs), Vision Models, 3D Large Models, and Multimodal Models, are revolutionizing healthcare by enhancing disease prediction, diagnostic assistance, personalized treatment planning, and drug discovery. The integration of graph neural networks in medical knowledge graphs and drug discovery highlights the potential of Large Graph Models (LGMs) in understanding complex biomedical relationships. The study also emphasizes the transformative role of Vision-Language Models (VLMs) and 3D Large Models in medical image analysis, anatomical modeling, and prosthetic design. Despite the challenges, these technologies are setting new benchmarks in medical innovation, improving diagnostic accuracy, and paving the way for personalized healthcare solutions. This paper aims to provide a comprehensive overview of the current state and future directions of large models in medicine, underscoring their significance in advancing global health.
Data-centric Graph Learning: A Survey
Oct 08, 2023


The history of artificial intelligence (AI) has witnessed the significant impact of high-quality data on various deep learning models, such as ImageNet for AlexNet and ResNet. Recently, instead of designing more complex neural architectures as model-centric approaches, the attention of AI community has shifted to data-centric ones, which focuses on better processing data to strengthen the ability of neural models. Graph learning, which operates on ubiquitous topological data, also plays an important role in the era of deep learning. In this survey, we comprehensively review graph learning approaches from the data-centric perspective, and aim to answer two crucial questions: (1) when to modify graph data and (2) how to modify graph data to unlock the potential of various graph models. Accordingly, we propose a novel taxonomy based on the stages in the graph learning pipeline, and highlight the processing methods for different data structures in the graph data, i.e., topology, feature and label. Furthermore, we analyze some potential problems embedded in graph data and discuss how to solve them in a data-centric manner. Finally, we provide some promising future directions for data-centric graph learning.
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023


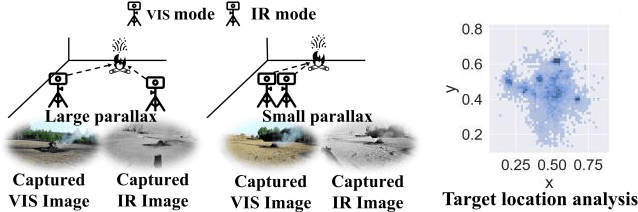
Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
voxel2vec: A Natural Language Processing Approach to Learning Distributed Representations for Scientific Data
Jul 11, 2022

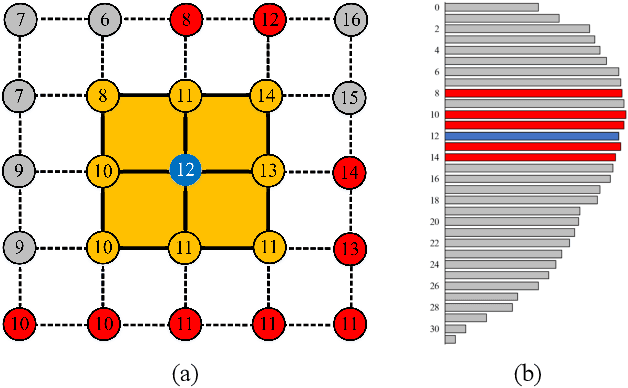

Relationships in scientific data, such as the numerical and spatial distribution relations of features in univariate data, the scalar-value combinations' relations in multivariate data, and the association of volumes in time-varying and ensemble data, are intricate and complex. This paper presents voxel2vec, a novel unsupervised representation learning model, which is used to learn distributed representations of scalar values/scalar-value combinations in a low-dimensional vector space. Its basic assumption is that if two scalar values/scalar-value combinations have similar contexts, they usually have high similarity in terms of features. By representing scalar values/scalar-value combinations as symbols, voxel2vec learns the similarity between them in the context of spatial distribution and then allows us to explore the overall association between volumes by transfer prediction. We demonstrate the usefulness and effectiveness of voxel2vec by comparing it with the isosurface similarity map of univariate data and applying the learned distributed representations to feature classification for multivariate data and to association analysis for time-varying and ensemble data.