 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegistration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023


Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
A Dataset-free Self-supervised Disentangled Learning Method for Adaptive Infrared and Visible Images Super-resolution Fusion
Dec 06, 2021
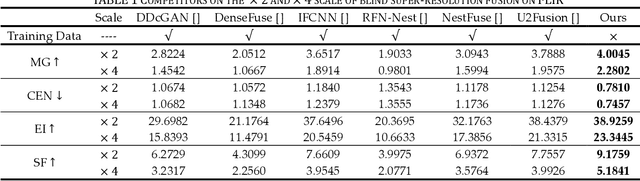
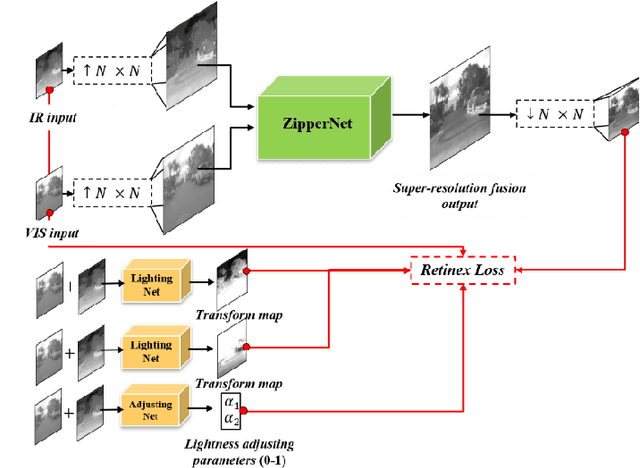
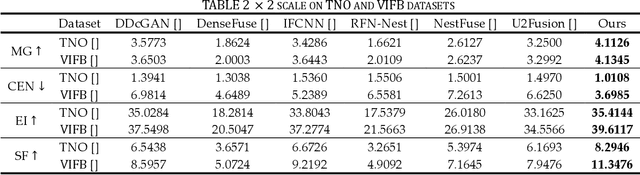
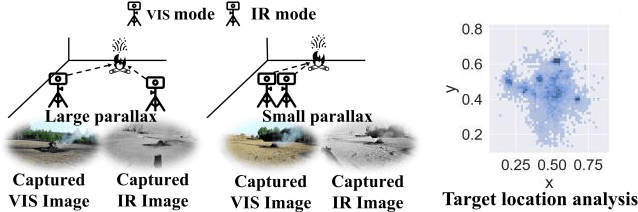
This study proposes a novel general dataset-free self-supervised learning framework based-on physical model named self-supervised disentangled learning (SDL), and proposes a novel method named Deep Retinex fusion (DRF) which applies SDL framework with generative networks and Retinex theory in infrared and visible images super-resolution fusion. Meanwhile, a generative dual-path fusion network ZipperNet and adaptive fusion loss function Retinex loss are designed for effectively high-quality fusion. The core idea of DRF (based-on SDL) consists of two parts: one is generating components which are disentangled from physical model using generative networks; the other is loss functions which are designed based-on physical relation, and generated components are combined by loss functions in training phase. Furthermore, in order to verify the effectiveness of our proposed DRF, qualitative and quantitative comparisons compared with six state-of-the-art methods are performed on three different infrared and visible datasets. Our code will be open source available soon at https://github.com/GuYuanjie/Deep-Retinex-fusion.
Deep Fusion Prior for Multi-Focus Image Super Resolution Fusion
Oct 12, 2021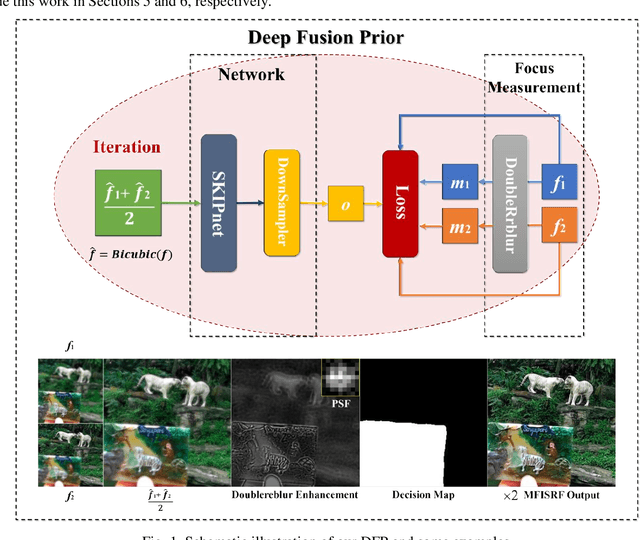
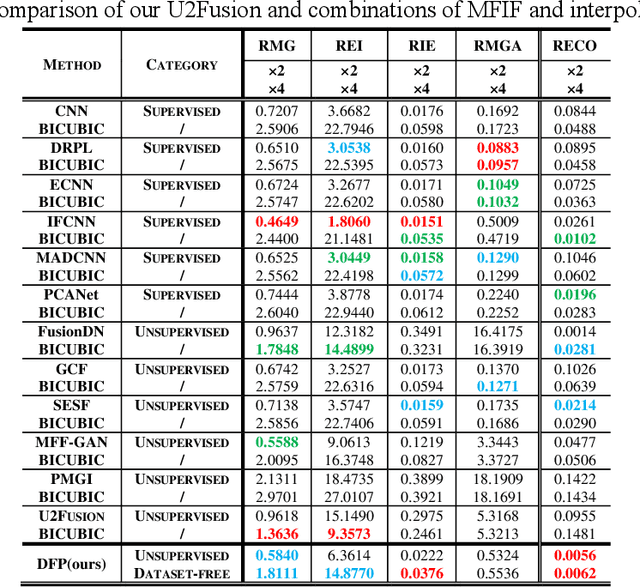
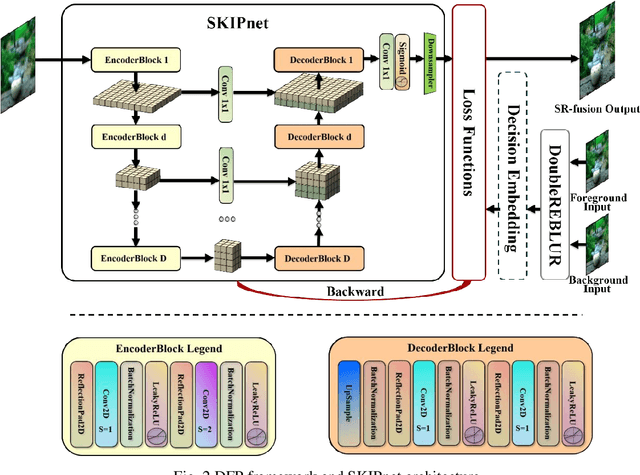

This paper unifies the multi-focus images fusion (MFIF) and blind super resolution (SR) problems as the multi-focus image super resolution fusion (MFISRF) task, and proposes a novel unified dataset-free unsupervised framework named deep fusion prior (DFP) to address such MFISRF task. DFP consists of SKIPnet network, DoubleReblur focus measurement tactic, decision embedding module and loss functions. In particular, DFP can obtain MFISRF only from two low-resolution inputs without any extent dataset; SKIPnet implementing unsupervised learning via deep image prior is an end-to-end generated network acting as the engine of DFP; DoubleReblur is used to determine the primary decision map without learning but based on estimated PSF and Gaussian kernels convolution; decision embedding module optimizes the decision map via learning; and DFP losses composed of content loss, joint gradient loss and gradient limit loss can obtain high-quality MFISRF results robustly. Experiments have proved that our proposed DFP approaches and even outperforms those state-of-art MFIF and SR method combinations. Additionally, DFP is a general framework, thus its networks and focus measurement tactics can be continuously updated to further improve the MFISRF performance. DFP codes are open source and will be available soon at http://github.com/GuYuanjie/DeepFusionPrior.
Object Detection in Specific Traffic Scenes using YOLOv2
May 12, 2019



object detection framework plays crucial role in autonomous driving. In this paper, we introduce the real-time object detection framework called You Only Look Once (YOLOv1) and the related improvements of YOLOv2. We further explore the capability of YOLOv2 by implementing its pre-trained model to do the object detecting tasks in some specific traffic scenes. The four artificially designed traffic scenes include single-car, single-person, frontperson-rearcar and frontcar-rearperson.