 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegistration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Paper and Code



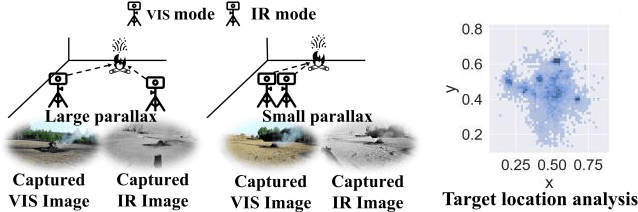
Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.