 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMAGINE: An 8-to-1b 22nm FD-SOI Compute-In-Memory CNN Accelerator With an End-to-End Analog Charge-Based 0.15-8POPS/W Macro Featuring Distribution-Aware Data Reshaping
Dec 27, 2024

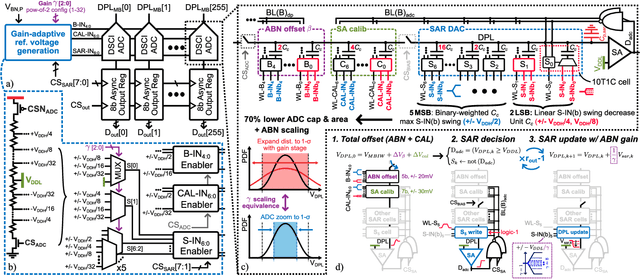
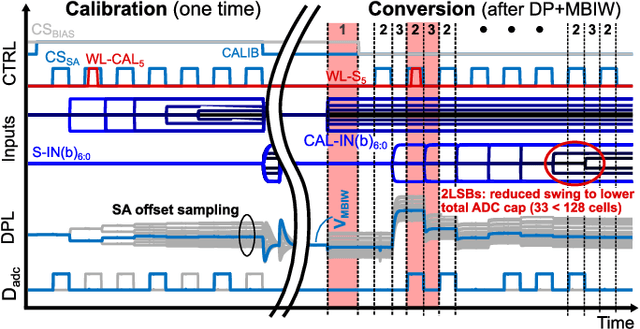
Charge-domain compute-in-memory (CIM) SRAMs have recently become an enticing compromise between computing efficiency and accuracy to process sub-8b convolutional neural networks (CNNs) at the edge. Yet, they commonly make use of a fixed dot-product (DP) voltage swing, which leads to a loss in effective ADC bits due to data-dependent clipping or truncation effects that waste precious conversion energy and computing accuracy. To overcome this, we present IMAGINE, a workload-adaptive 1-to-8b CIM-CNN accelerator in 22nm FD-SOI. It introduces a 1152x256 end-to-end charge-based macro with a multi-bit DP based on an input-serial, weight-parallel accumulation that avoids power-hungry DACs. An adaptive swing is achieved by combining a channel-wise DP array split with a linear in-ADC implementation of analog batch-normalization (ABN), obtaining a distribution-aware data reshaping. Critical design constraints are relaxed by including the post-silicon equivalent noise within a CIM-aware CNN training framework. Measurement results showcase an 8b system-level energy efficiency of 40TOPS/W at 0.3/0.6V, with competitive accuracies on MNIST and CIFAR-10. Moreover, the peak energy and area efficiencies of the 187kB/mm2 macro respectively reach up to 0.15-8POPS/W and 2.6-154TOPS/mm2, scaling with the 8-to-1b computing precision. These results exceed previous charge-based designs by 3-to-5x while being the first work to provide linear in-memory rescaling.
An Event-Based Digital Compute-In-Memory Accelerator with Flexible Operand Resolution and Layer-Wise Weight/Output Stationarity
Oct 30, 2024Compute-in-memory (CIM) accelerators for spiking neural networks (SNNs) are promising solutions to enable $\mu$s-level inference latency and ultra-low energy in edge vision applications. Yet, their current lack of flexibility at both the circuit and system levels prevents their deployment in a wide range of real-life scenarios. In this work, we propose a novel digital CIM macro that supports arbitrary operand resolution and shape, with a unified CIM storage for weights and membrane potentials. These circuit-level techniques enable a hybrid weight- and output-stationary dataflow at the system level to maximize operand reuse, thereby minimizing costly on- and off-chip data movements during the SNN execution. Measurement results of a fabricated FlexSpIM prototype in 40-nm CMOS demonstrate a 2$\times$ increase in bit-normalized energy efficiency compared to prior fixed-precision digital CIM-SNNs, while providing resolution reconfiguration with bitwise granularity. Our approach can save up to 90% energy in large-scale systems, while reaching a state-of-the-art classification accuracy of 95.8% on the IBM DVS gesture dataset.
EvGNN: An Event-driven Graph Neural Network Accelerator for Edge Vision
Apr 30, 2024



Edge vision systems combining sensing and embedded processing promise low-latency, decentralized, and energy-efficient solutions that forgo reliance on the cloud. As opposed to conventional frame-based vision sensors, event-based cameras deliver a microsecond-scale temporal resolution with sparse information encoding, thereby outlining new opportunities for edge vision systems. However, mainstream algorithms for frame-based vision, which mostly rely on convolutional neural networks (CNNs), can hardly exploit the advantages of event-based vision as they are typically optimized for dense matrix-vector multiplications. While event-driven graph neural networks (GNNs) have recently emerged as a promising solution for sparse event-based vision, their irregular structure is a challenge that currently hinders the design of efficient hardware accelerators. In this paper, we propose EvGNN, the first event-driven GNN accelerator for low-footprint, ultra-low-latency, and high-accuracy edge vision with event-based cameras. It relies on three central ideas: (i) directed dynamic graphs exploiting single-hop nodes with edge-free storage, (ii) event queues for the efficient identification of local neighbors within a spatiotemporally decoupled search range, and (iii) a novel layer-parallel processing scheme enabling the low-latency execution of multi-layer GNNs. We deployed EvGNN on a Xilinx KV260 Ultrascale+ MPSoC platform and benchmarked it on the N-CARS dataset for car recognition, demonstrating a classification accuracy of 87.8% and an average latency per event of 16$\mu$s, thereby enabling real-time, microsecond-resolution event-based vision at the edge.