 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Predictive Coding Networks via Direct Kolen-Pollack Feedback Alignment
Feb 17, 2026Predictive coding (PC) is a biologically inspired algorithm for training neural networks that relies only on local updates, allowing parallel learning across layers. However, practical implementations face two key limitations: error signals must still propagate from the output to early layers through multiple inference-phase steps, and feedback decays exponentially during this process, leading to vanishing updates in early layers. We propose direct Kolen-Pollack predictive coding (DKP-PC), which simultaneously addresses both feedback delay and exponential decay, yielding a more efficient and scalable variant of PC while preserving update locality. Leveraging direct feedback alignment and direct Kolen-Pollack algorithms, DKP-PC introduces learnable feedback connections from the output layer to all hidden layers, establishing a direct pathway for error transmission. This yields an algorithm that reduces the theoretical error propagation time complexity from O(L), with L being the network depth, to O(1), removing depth-dependent delay in error signals. Moreover, empirical results demonstrate that DKP-PC achieves performance at least comparable to, and often exceeding, that of standard PC, while offering improved latency and computational performance, supporting its potential for custom hardware-efficient implementations.
IMAGINE: An 8-to-1b 22nm FD-SOI Compute-In-Memory CNN Accelerator With an End-to-End Analog Charge-Based 0.15-8POPS/W Macro Featuring Distribution-Aware Data Reshaping
Dec 27, 2024

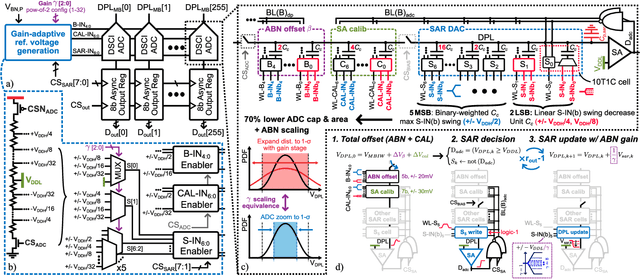
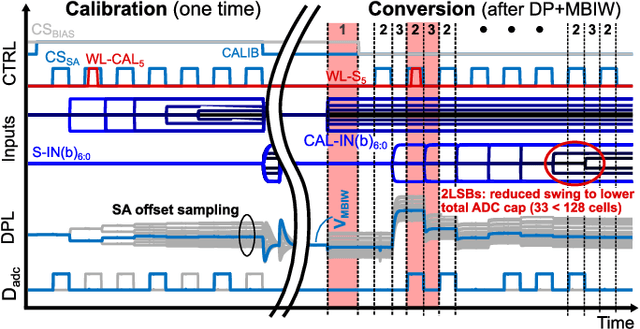
Charge-domain compute-in-memory (CIM) SRAMs have recently become an enticing compromise between computing efficiency and accuracy to process sub-8b convolutional neural networks (CNNs) at the edge. Yet, they commonly make use of a fixed dot-product (DP) voltage swing, which leads to a loss in effective ADC bits due to data-dependent clipping or truncation effects that waste precious conversion energy and computing accuracy. To overcome this, we present IMAGINE, a workload-adaptive 1-to-8b CIM-CNN accelerator in 22nm FD-SOI. It introduces a 1152x256 end-to-end charge-based macro with a multi-bit DP based on an input-serial, weight-parallel accumulation that avoids power-hungry DACs. An adaptive swing is achieved by combining a channel-wise DP array split with a linear in-ADC implementation of analog batch-normalization (ABN), obtaining a distribution-aware data reshaping. Critical design constraints are relaxed by including the post-silicon equivalent noise within a CIM-aware CNN training framework. Measurement results showcase an 8b system-level energy efficiency of 40TOPS/W at 0.3/0.6V, with competitive accuracies on MNIST and CIFAR-10. Moreover, the peak energy and area efficiencies of the 187kB/mm2 macro respectively reach up to 0.15-8POPS/W and 2.6-154TOPS/mm2, scaling with the 8-to-1b computing precision. These results exceed previous charge-based designs by 3-to-5x while being the first work to provide linear in-memory rescaling.
Learning without feedback: Direct random target projection as a feedback-alignment algorithm with layerwise feedforward training
Sep 03, 2019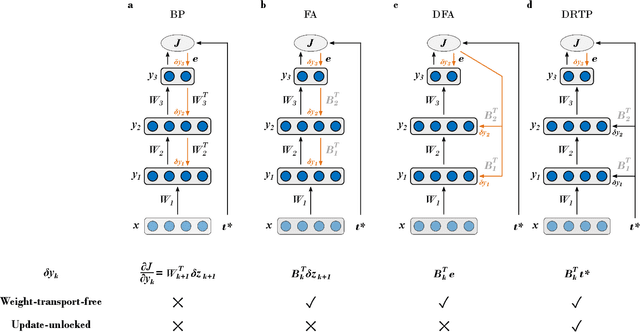
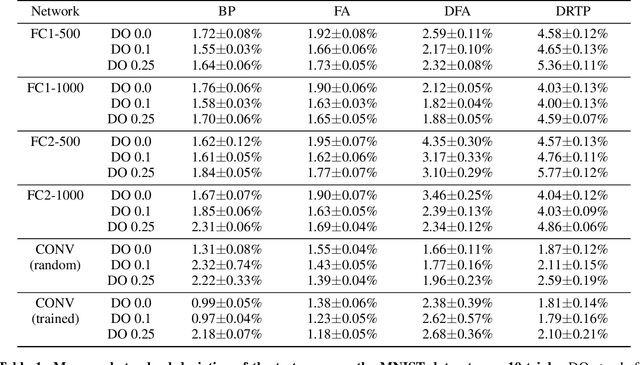
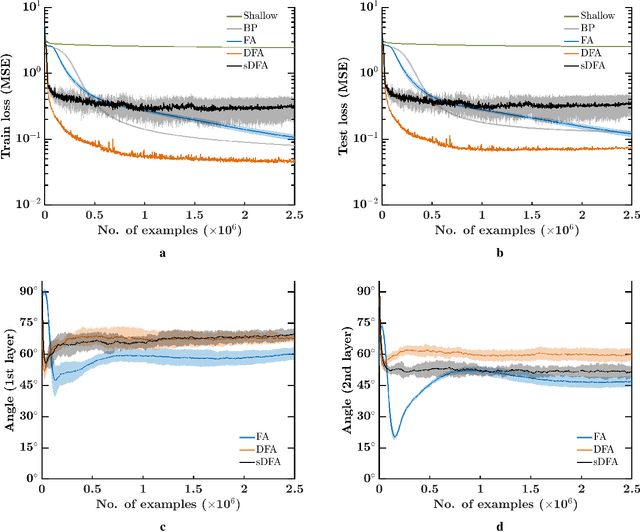

While the backpropagation of error algorithm allowed for a rapid rise in the development and deployment of artificial neural networks, two key issues currently preclude biological plausibility: (i) symmetry is required between forward and backward weights, which is known as the weight transport problem, and (ii) updates are locked before both the forward and backward passes have been completed. The feedback alignment (FA) algorithm uses fixed random feedback weights to release the weight transport problem. The direct feedback alignment (DFA) variation directly propagates the output error to each hidden layer through fixed random connectivity matrices. In this work, we show that using only the error sign is sufficient to maintain feedback alignment and to provide learning in the hidden layers. As in classification problems the error sign information is already contained in the target vector, using the latter as a proxy for the error brings three advantages: (i) it solves the weight transport problem by eliminating the requirement for an explicit feedback pathway, which also reduces the computational workload, (ii) it reduces memory requirements by removing update locking, allowing for weight updates to be computed in each layer independently without requiring a full forward pass, and (iii) it leads to a purely feedforward and low-cost algorithm that only requires a label-dependent random vector selection to estimate the layerwise loss gradients. Therefore, in this work, we propose the direct random target projection (DRTP) algorithm and demonstrate on the MNIST and CIFAR-10 datasets that, despite the absence of an explicit error feedback, DRTP performance can still lie close to the one of BP, FA and DFA. The low memory and computational cost of DRTP and its reliance only on layerwise feedforward computation make it suitable for deployment in adaptive edge computing devices.