 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMAGINE: An 8-to-1b 22nm FD-SOI Compute-In-Memory CNN Accelerator With an End-to-End Analog Charge-Based 0.15-8POPS/W Macro Featuring Distribution-Aware Data Reshaping
Dec 27, 2024

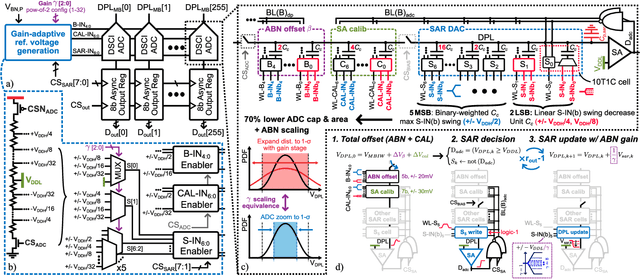
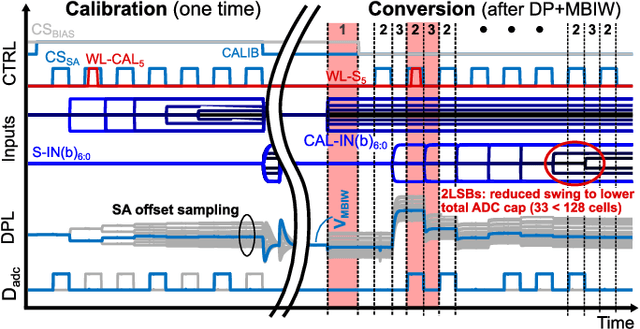
Charge-domain compute-in-memory (CIM) SRAMs have recently become an enticing compromise between computing efficiency and accuracy to process sub-8b convolutional neural networks (CNNs) at the edge. Yet, they commonly make use of a fixed dot-product (DP) voltage swing, which leads to a loss in effective ADC bits due to data-dependent clipping or truncation effects that waste precious conversion energy and computing accuracy. To overcome this, we present IMAGINE, a workload-adaptive 1-to-8b CIM-CNN accelerator in 22nm FD-SOI. It introduces a 1152x256 end-to-end charge-based macro with a multi-bit DP based on an input-serial, weight-parallel accumulation that avoids power-hungry DACs. An adaptive swing is achieved by combining a channel-wise DP array split with a linear in-ADC implementation of analog batch-normalization (ABN), obtaining a distribution-aware data reshaping. Critical design constraints are relaxed by including the post-silicon equivalent noise within a CIM-aware CNN training framework. Measurement results showcase an 8b system-level energy efficiency of 40TOPS/W at 0.3/0.6V, with competitive accuracies on MNIST and CIFAR-10. Moreover, the peak energy and area efficiencies of the 187kB/mm2 macro respectively reach up to 0.15-8POPS/W and 2.6-154TOPS/mm2, scaling with the 8-to-1b computing precision. These results exceed previous charge-based designs by 3-to-5x while being the first work to provide linear in-memory rescaling.
Implementing a LoRa Software-Defined Radio on a General-Purpose ULP Microcontroller
Jul 17, 2021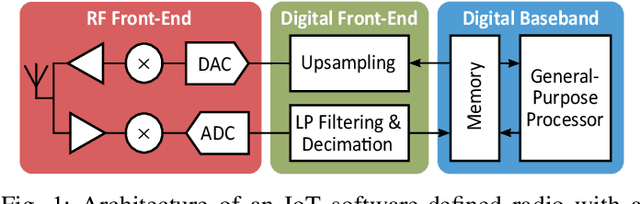
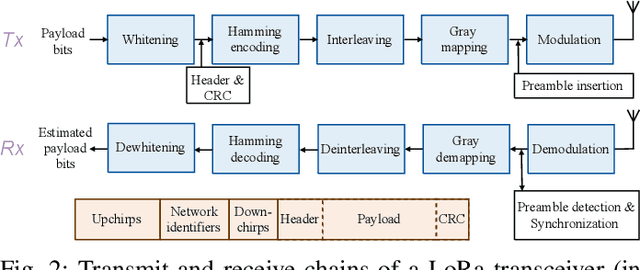
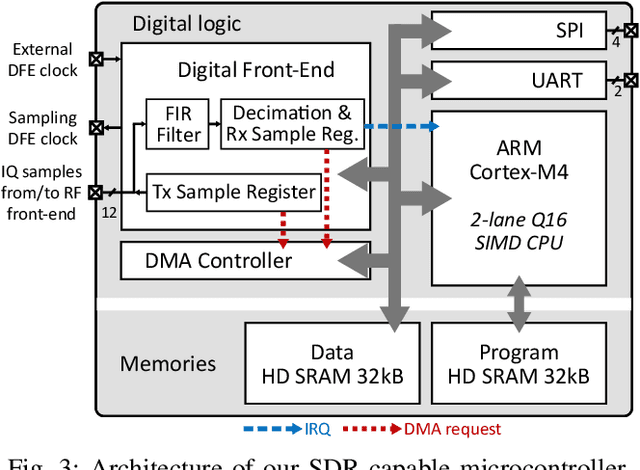
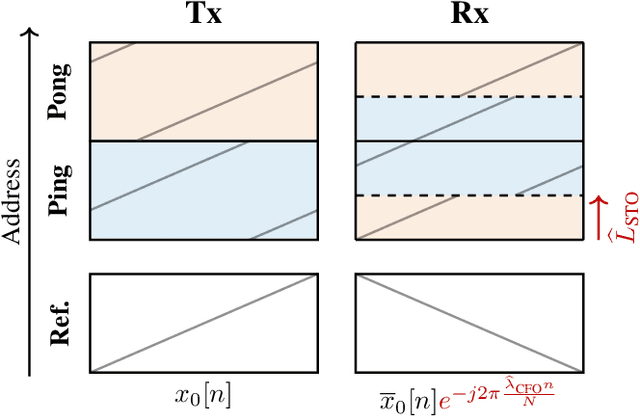
Emerging Internet-of-Things sensing applications rely on ultra low-power (ULP) microcontroller units (MCUs) that wirelessly transmit data to the cloud. Typical MCUs nowadays consist of generic blocks, except for the protocol-specific radios implemented in hardware. Hardware radios however slow down the evolution of wireless protocols due to retrocompatiblity concerns. In this work, we explore a software-defined radio architecture by demonstrating a LoRa transceiver running on custom ULP MCU codenamed SleepRider with an ARM Cortex-M4 CPU. In SleepRider MCU, we offload the generic baseband operations (e.g., low-pass filtering) to a reconfigurable digital front-end block and use the Cortex-M4 CPU to perform the protocol-specific computations. Our software implementation of the LoRa physical layer only uses the native SIMD instructions of the Cortex-M4 to achieve real-time transmission and reception of LoRa packets. SleepRider MCU has been fabricated in a 28nm FDSOI CMOS technology and is used in a testbed to experimentally validate the software implementation. Experimental results show that the proposed software-defined radio requires only a CPU frequency of 20 MHz to correctly receive a LoRa packet, with an ultra-low power consumption of 0.42 mW on average.
Bottom-Up and Top-Down Neural Processing Systems Design: Neuromorphic Intelligence as the Convergence of Natural and Artificial Intelligence
Jun 02, 2021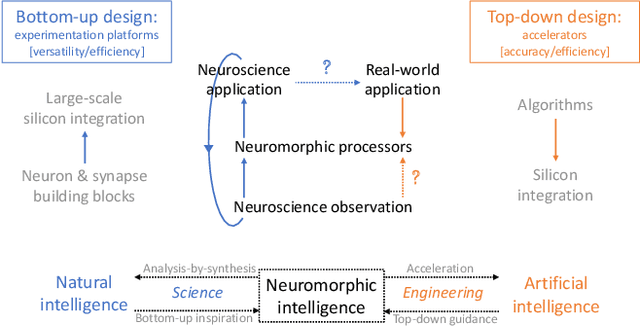
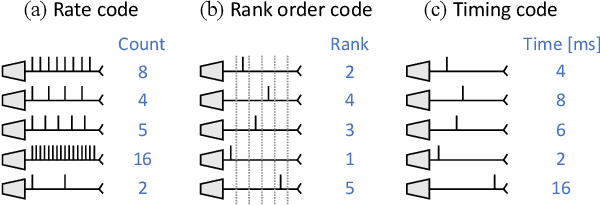
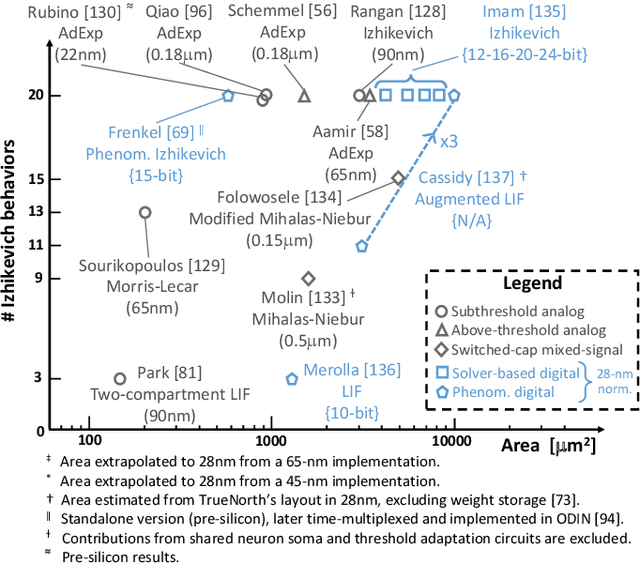
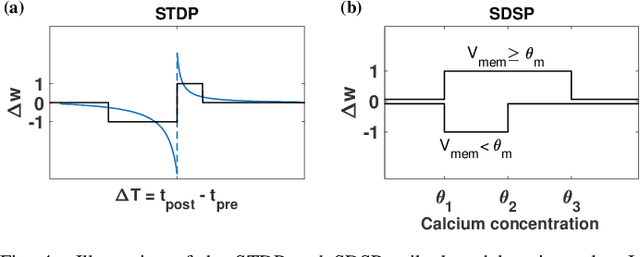
While Moore's law has driven exponential computing power expectations, its nearing end calls for new avenues for improving the overall system performance. One of these avenues is the exploration of new alternative brain-inspired computing architectures that promise to achieve the flexibility and computational efficiency of biological neural processing systems. Within this context, neuromorphic intelligence represents a paradigm shift in computing based on the implementation of spiking neural network architectures tightly co-locating processing and memory. In this paper, we provide a comprehensive overview of the field, highlighting the different levels of granularity present in existing silicon implementations, comparing approaches that aim at replicating natural intelligence (bottom-up) versus those that aim at solving practical artificial intelligence applications (top-down), and assessing the benefits of the different circuit design styles used to achieve these goals. First, we present the analog, mixed-signal and digital circuit design styles, identifying the boundary between processing and memory through time multiplexing, in-memory computation and novel devices. Next, we highlight the key tradeoffs for each of the bottom-up and top-down approaches, survey their silicon implementations, and carry out detailed comparative analyses to extract design guidelines. Finally, we identify both necessary synergies and missing elements required to achieve a competitive advantage for neuromorphic edge computing over conventional machine-learning accelerators, and outline the key elements for a framework toward neuromorphic intelligence.
A 28-nm Convolutional Neuromorphic Processor Enabling Online Learning with Spike-Based Retinas
May 13, 2020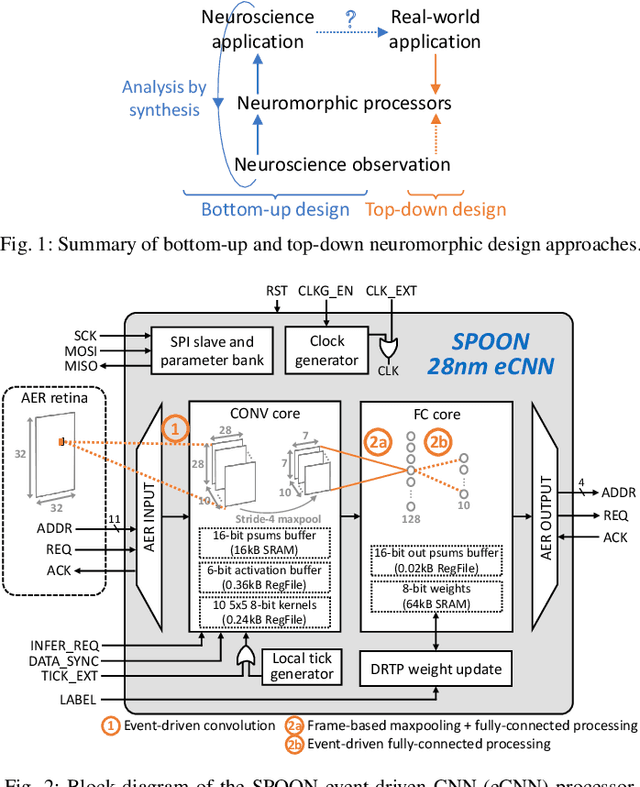
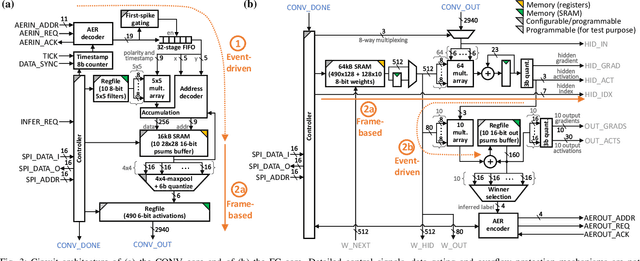
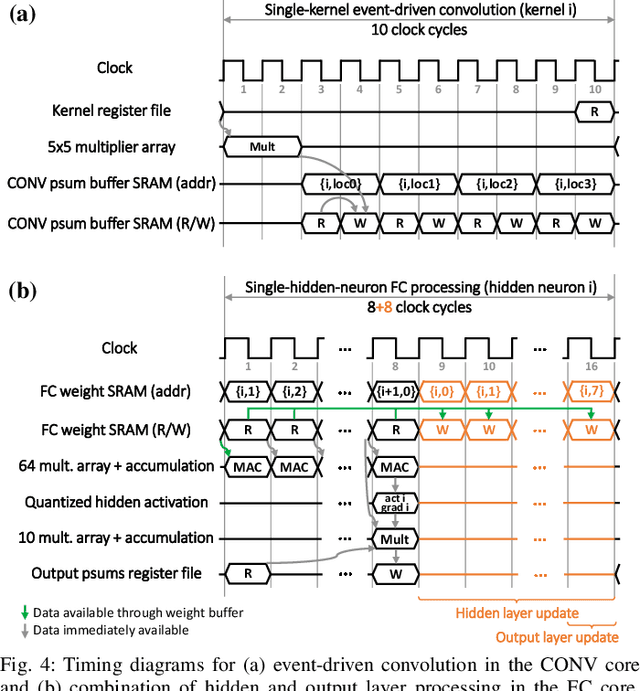

In an attempt to follow biological information representation and organization principles, the field of neuromorphic engineering is usually approached bottom-up, from the biophysical models to large-scale integration in silico. While ideal as experimentation platforms for cognitive computing and neuroscience, bottom-up neuromorphic processors have yet to demonstrate an efficiency advantage compared to specialized neural network accelerators for real-world problems. Top-down approaches aim at answering this difficulty by (i) starting from the applicative problem and (ii) investigating how to make the associated algorithms hardware-efficient and biologically-plausible. In order to leverage the data sparsity of spike-based neuromorphic retinas for adaptive edge computing and vision applications, we follow a top-down approach and propose SPOON, a 28-nm event-driven CNN (eCNN). It embeds online learning with only 16.8-% power and 11.8-% area overheads with the biologically-plausible direct random target projection (DRTP) algorithm. With an energy per classification of 313nJ at 0.6V and a 0.32-mm$^2$ area for accuracies of 95.3% (on-chip training) and 97.5% (off-chip training) on MNIST, we demonstrate that SPOON reaches the efficiency of conventional machine learning accelerators while embedding on-chip learning and being compatible with event-based sensors, a point that we further emphasize with N-MNIST benchmarking.
Learning without feedback: Direct random target projection as a feedback-alignment algorithm with layerwise feedforward training
Sep 03, 2019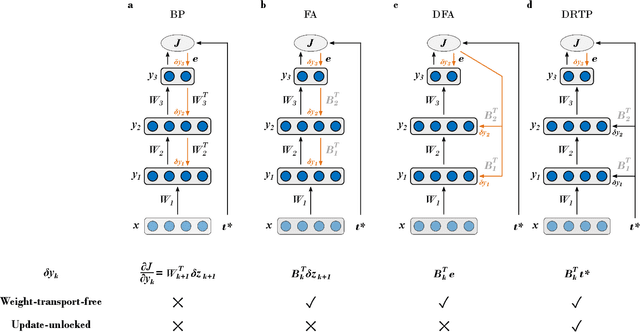
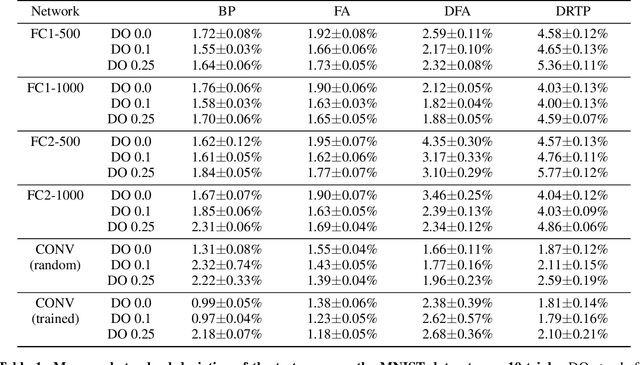
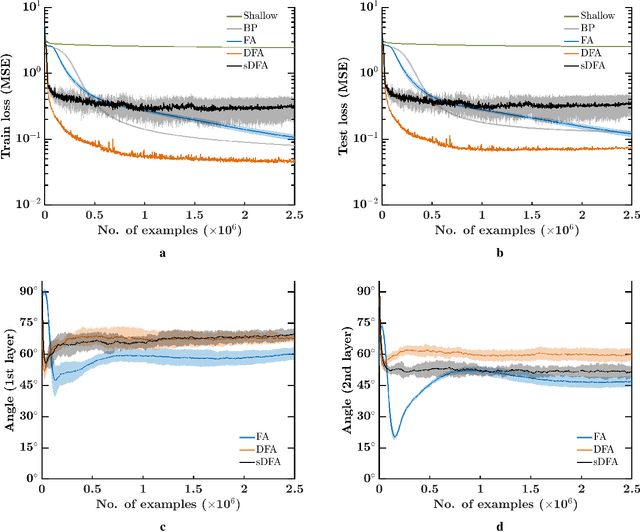

While the backpropagation of error algorithm allowed for a rapid rise in the development and deployment of artificial neural networks, two key issues currently preclude biological plausibility: (i) symmetry is required between forward and backward weights, which is known as the weight transport problem, and (ii) updates are locked before both the forward and backward passes have been completed. The feedback alignment (FA) algorithm uses fixed random feedback weights to release the weight transport problem. The direct feedback alignment (DFA) variation directly propagates the output error to each hidden layer through fixed random connectivity matrices. In this work, we show that using only the error sign is sufficient to maintain feedback alignment and to provide learning in the hidden layers. As in classification problems the error sign information is already contained in the target vector, using the latter as a proxy for the error brings three advantages: (i) it solves the weight transport problem by eliminating the requirement for an explicit feedback pathway, which also reduces the computational workload, (ii) it reduces memory requirements by removing update locking, allowing for weight updates to be computed in each layer independently without requiring a full forward pass, and (iii) it leads to a purely feedforward and low-cost algorithm that only requires a label-dependent random vector selection to estimate the layerwise loss gradients. Therefore, in this work, we propose the direct random target projection (DRTP) algorithm and demonstrate on the MNIST and CIFAR-10 datasets that, despite the absence of an explicit error feedback, DRTP performance can still lie close to the one of BP, FA and DFA. The low memory and computational cost of DRTP and its reliance only on layerwise feedforward computation make it suitable for deployment in adaptive edge computing devices.
MorphIC: A 65-nm 738k-Synapse/mm$^2$ Quad-Core Binary-Weight Digital Neuromorphic Processor with Stochastic Spike-Driven Online Learning
Apr 17, 2019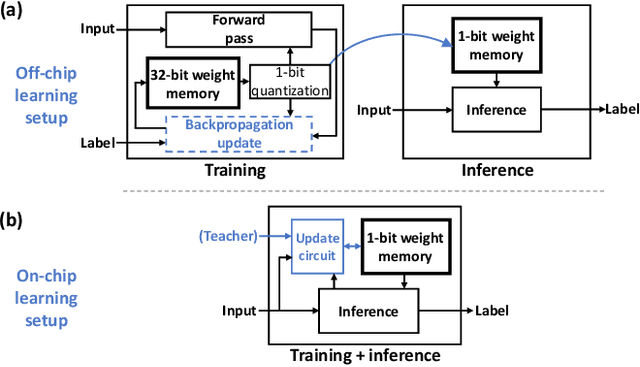
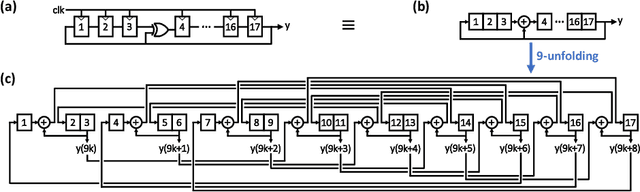
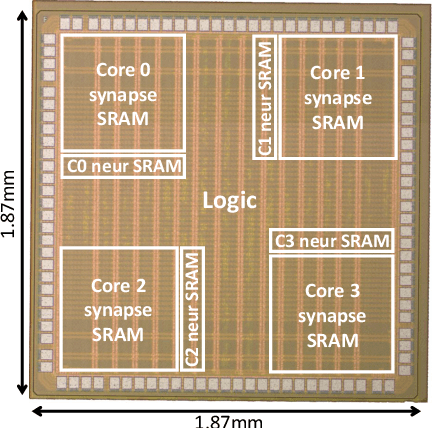
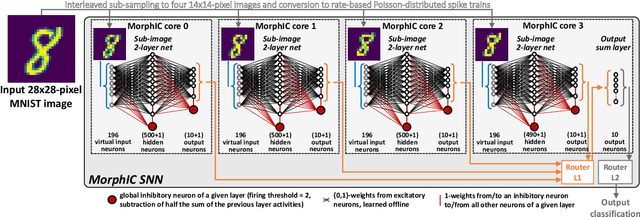
Recent trends in the field of artificial neural networks (ANNs) and convolutional neural networks (CNNs) investigate weight quantization as a means to increase the resource- and power-efficiency of hardware devices. As full on-chip weight storage is necessary to avoid the high energy cost of off-chip memory accesses, memory reduction requirements for weight storage pushed toward the use of binary weights, which were demonstrated to have a limited accuracy reduction on many applications when quantization-aware training techniques are used. In parallel, spiking neural network (SNN) architectures are explored to further reduce power when processing sparse event-based data streams, while on-chip spike-based online learning appears as a key feature for applications constrained in power and resources during the training phase. However, designing power- and area-efficient spiking neural networks still requires the development of specific techniques in order to leverage on-chip online learning on binary weights without compromising the synapse density. In this work, we demonstrate MorphIC, a quad-core binary-weight digital neuromorphic processor embedding a stochastic version of the spike-driven synaptic plasticity (S-SDSP) learning rule and a hierarchical routing fabric for large-scale chip interconnection. The MorphIC SNN processor embeds a total of 2k leaky integrate-and-fire (LIF) neurons and more than two million plastic synapses for an active silicon area of 2.86mm$^2$ in 65nm CMOS, achieving a high density of 738k synapses/mm$^2$. MorphIC demonstrates an order-of-magnitude improvement in the area-accuracy tradeoff on the MNIST classification task compared to previously-proposed SNNs, while keeping a competitive energy-accuracy tradeoff.