 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 28-nm Convolutional Neuromorphic Processor Enabling Online Learning with Spike-Based Retinas
May 13, 2020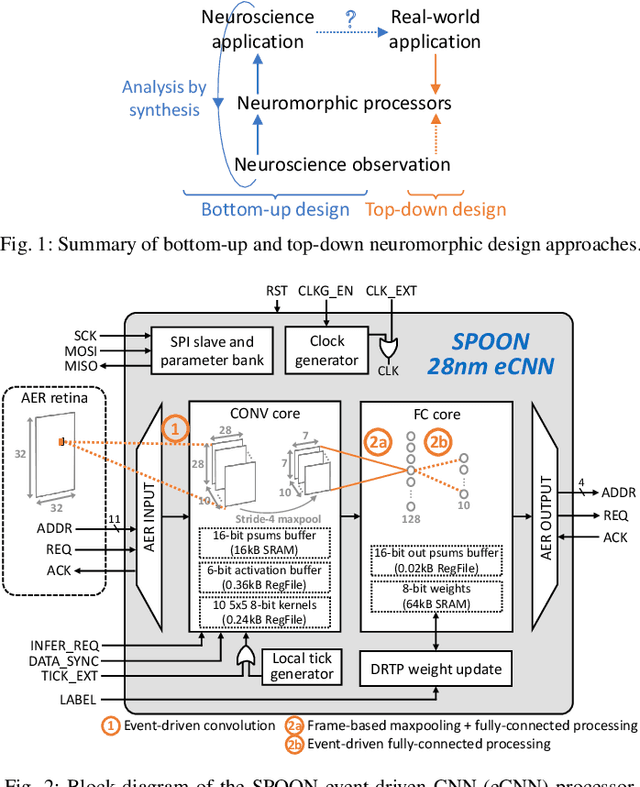
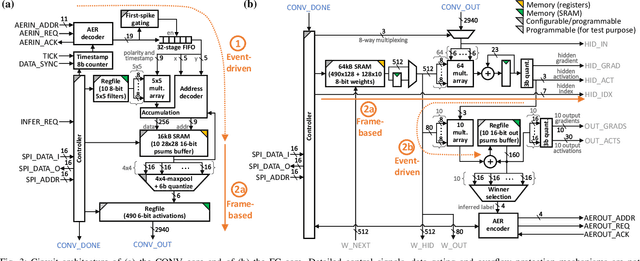
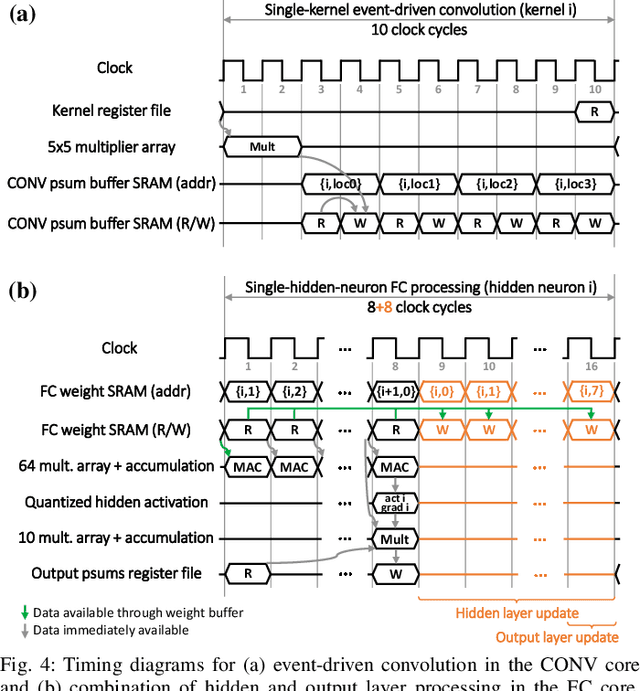

In an attempt to follow biological information representation and organization principles, the field of neuromorphic engineering is usually approached bottom-up, from the biophysical models to large-scale integration in silico. While ideal as experimentation platforms for cognitive computing and neuroscience, bottom-up neuromorphic processors have yet to demonstrate an efficiency advantage compared to specialized neural network accelerators for real-world problems. Top-down approaches aim at answering this difficulty by (i) starting from the applicative problem and (ii) investigating how to make the associated algorithms hardware-efficient and biologically-plausible. In order to leverage the data sparsity of spike-based neuromorphic retinas for adaptive edge computing and vision applications, we follow a top-down approach and propose SPOON, a 28-nm event-driven CNN (eCNN). It embeds online learning with only 16.8-% power and 11.8-% area overheads with the biologically-plausible direct random target projection (DRTP) algorithm. With an energy per classification of 313nJ at 0.6V and a 0.32-mm$^2$ area for accuracies of 95.3% (on-chip training) and 97.5% (off-chip training) on MNIST, we demonstrate that SPOON reaches the efficiency of conventional machine learning accelerators while embedding on-chip learning and being compatible with event-based sensors, a point that we further emphasize with N-MNIST benchmarking.
MorphIC: A 65-nm 738k-Synapse/mm$^2$ Quad-Core Binary-Weight Digital Neuromorphic Processor with Stochastic Spike-Driven Online Learning
Apr 17, 2019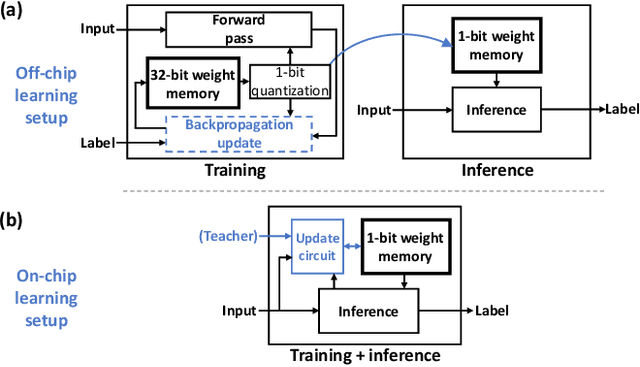
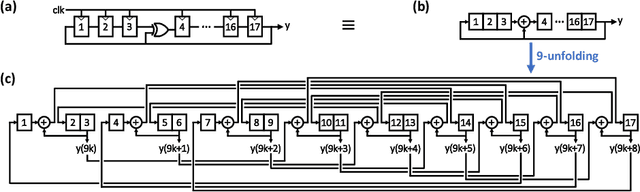
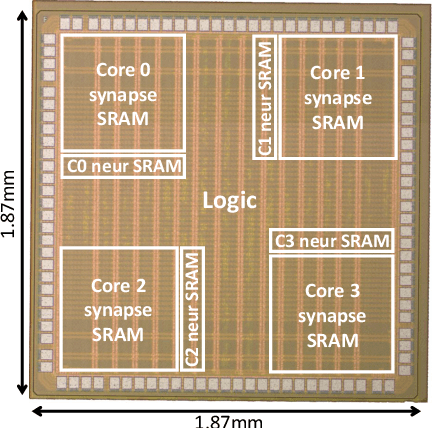
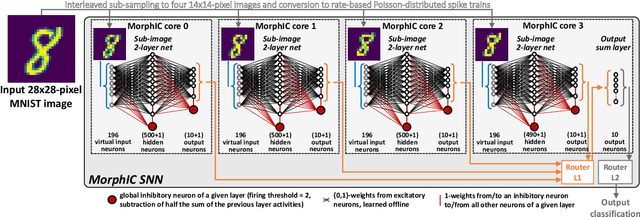
Recent trends in the field of artificial neural networks (ANNs) and convolutional neural networks (CNNs) investigate weight quantization as a means to increase the resource- and power-efficiency of hardware devices. As full on-chip weight storage is necessary to avoid the high energy cost of off-chip memory accesses, memory reduction requirements for weight storage pushed toward the use of binary weights, which were demonstrated to have a limited accuracy reduction on many applications when quantization-aware training techniques are used. In parallel, spiking neural network (SNN) architectures are explored to further reduce power when processing sparse event-based data streams, while on-chip spike-based online learning appears as a key feature for applications constrained in power and resources during the training phase. However, designing power- and area-efficient spiking neural networks still requires the development of specific techniques in order to leverage on-chip online learning on binary weights without compromising the synapse density. In this work, we demonstrate MorphIC, a quad-core binary-weight digital neuromorphic processor embedding a stochastic version of the spike-driven synaptic plasticity (S-SDSP) learning rule and a hierarchical routing fabric for large-scale chip interconnection. The MorphIC SNN processor embeds a total of 2k leaky integrate-and-fire (LIF) neurons and more than two million plastic synapses for an active silicon area of 2.86mm$^2$ in 65nm CMOS, achieving a high density of 738k synapses/mm$^2$. MorphIC demonstrates an order-of-magnitude improvement in the area-accuracy tradeoff on the MNIST classification task compared to previously-proposed SNNs, while keeping a competitive energy-accuracy tradeoff.