 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefakeHop++: An Enhanced Lightweight Deepfake Detector
Paper and Code

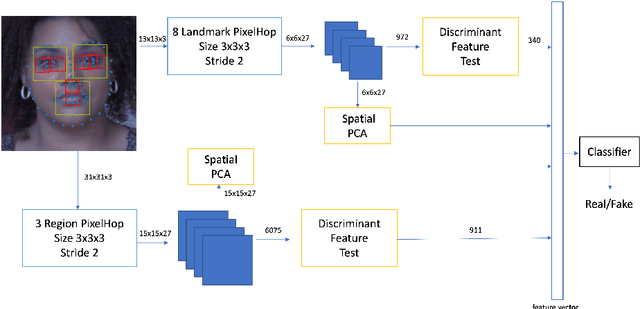
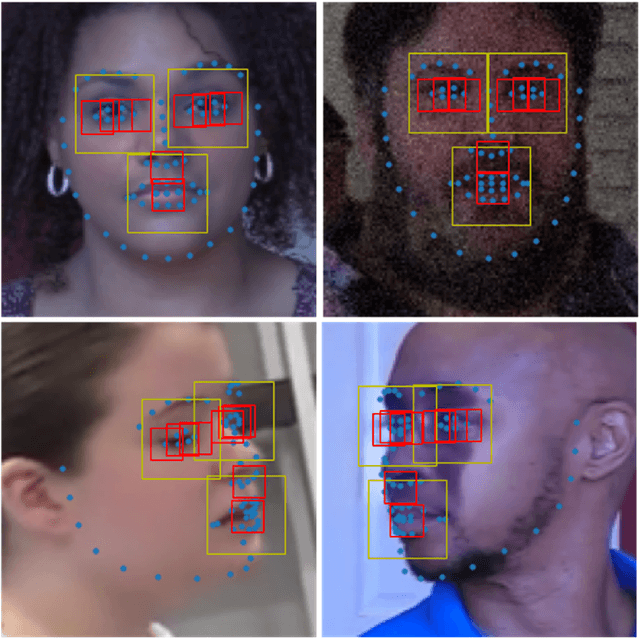
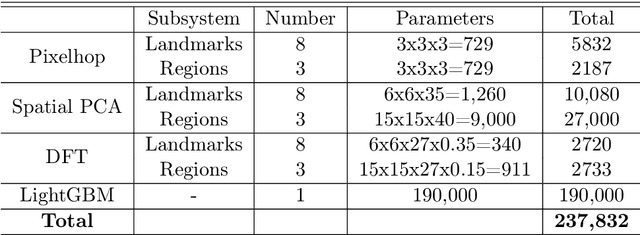
On the basis of DefakeHop, an enhanced lightweight Deepfake detector called DefakeHop++ is proposed in this work. The improvements lie in two areas. First, DefakeHop examines three facial regions (i.e., two eyes and mouth) while DefakeHop++ includes eight more landmarks for broader coverage. Second, for discriminant features selection, DefakeHop uses an unsupervised approach while DefakeHop++ adopts a more effective approach with supervision, called the Discriminant Feature Test (DFT). In DefakeHop++, rich spatial and spectral features are first derived from facial regions and landmarks automatically. Then, DFT is used to select a subset of discriminant features for classifier training. As compared with MobileNet v3 (a lightweight CNN model of 1.5M parameters targeting at mobile applications), DefakeHop++ has a model of 238K parameters, which is 16% of MobileNet v3. Furthermore, DefakeHop++ outperforms MobileNet v3 in Deepfake image detection performance in a weakly-supervised setting.