 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Preference Elicitation for Minimax Regret Optimization in Uncertainty Matroids
Mar 25, 2025This paper presents an efficient preference elicitation framework for uncertain matroid optimization, where precise weight information is unavailable, but insights into possible weight values are accessible. The core innovation of our approach lies in its ability to systematically elicit user preferences, aligning the optimization process more closely with decision-makers' objectives. By incrementally querying preferences between pairs of elements, we iteratively refine the parametric uncertainty regions, leveraging the structural properties of matroids. Our method aims to achieve the exact optimum by reducing regret with a few elicitation rounds. Additionally, our approach avoids the computation of Minimax Regret and the use of Linear programming solvers at every iteration, unlike previous methods. Experimental results on four standard matroids demonstrate that our method reaches optimality more quickly and with fewer preference queries than existing techniques.
Gradient Based Hybridization of PSO
Dec 15, 2023Particle Swarm Optimization (PSO) has emerged as a powerful metaheuristic global optimization approach over the past three decades. Its appeal lies in its ability to tackle complex multidimensional problems that defy conventional algorithms. However, PSO faces challenges, such as premature stagnation in single-objective scenarios and the need to strike a balance between exploration and exploitation. Hybridizing PSO by integrating its cooperative nature with established optimization techniques from diverse paradigms offers a promising solution. In this paper, we investigate various strategies for synergizing gradient-based optimizers with PSO. We introduce different hybridization principles and explore several approaches, including sequential decoupled hybridization, coupled hybridization, and adaptive hybridization. These strategies aim to enhance the efficiency and effectiveness of PSO, ultimately improving its ability to navigate intricate optimization landscapes. By combining the strengths of gradient-based methods with the inherent social dynamics of PSO, we seek to address the critical objectives of intelligent exploration and exploitation in complex optimization tasks. Our study delves into the comparative merits of these hybridization techniques and offers insights into their application across different problem domains.
UniRecSys: A Unified Framework for Personalized, Group, Package, and Package-to-Group Recommendations
Aug 08, 2023Recommender systems aim to enhance the overall user experience by providing tailored recommendations for a variety of products and services. These systems help users make more informed decisions, leading to greater user satisfaction with the platform. However, the implementation of these systems largely depends on the context, which can vary from recommending an item or package to a user or a group. This requires careful exploration of several models during the deployment, as there is no comprehensive and unified approach that deals with recommendations at different levels. Furthermore, these individual models must be closely attuned to their generated recommendations depending on the context to prevent significant variation in their generated recommendations. In this paper, we propose a novel unified recommendation framework that addresses all four recommendation tasks, namely personalized, group, package, or package-to-group recommendation, filling the gap in the current research landscape. The proposed framework can be integrated with most of the traditional matrix factorization-based collaborative filtering models. The idea is to enhance the formulation of the existing approaches by incorporating components focusing on the exploitation of the group and package latent factors. These components also help in exploiting a rich latent representation of the user/item by enforcing them to align closely with their corresponding group/package representation. We consider two prominent CF techniques, Regularized Matrix Factorization and Maximum Margin Matrix factorization, as the baseline models and demonstrate their customization to various recommendation tasks. Experiment results on two publicly available datasets are reported, comparing them to other baseline approaches that consider individual rating feedback for group or package recommendations.
Conformal Group Recommender System
Jul 22, 2023
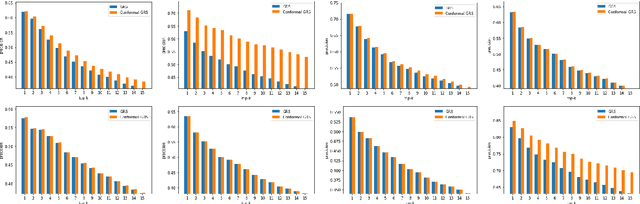
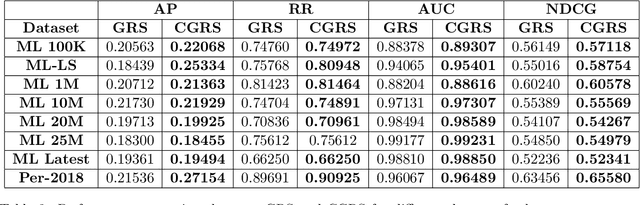
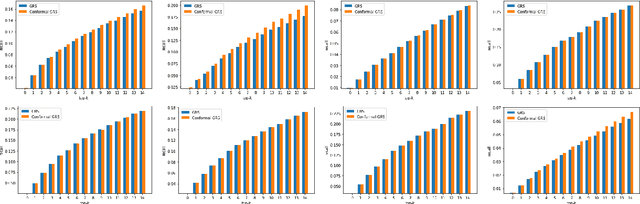
Group recommender systems (GRS) are critical in discovering relevant items from a near-infinite inventory based on group preferences rather than individual preferences, like recommending a movie, restaurant, or tourist destination to a group of individuals. The traditional models of group recommendation are designed to act like a black box with a strict focus on improving recommendation accuracy, and most often, they place the onus on the users to interpret recommendations. In recent years, the focus of Recommender Systems (RS) research has shifted away from merely improving recommendation accuracy towards value additions such as confidence and explanation. In this work, we propose a conformal prediction framework that provides a measure of confidence with prediction in conjunction with a group recommender system to augment the system-generated plain recommendations. In the context of group recommender systems, we propose various nonconformity measures that play a vital role in the efficiency of the conformal framework. We also show that defined nonconformity satisfies the exchangeability property. Experimental results demonstrate the effectiveness of the proposed approach over several benchmark datasets. Furthermore, our proposed approach also satisfies validity and efficiency properties.
Data augmentation for recommender system: A semi-supervised approach using maximum margin matrix factorization
Jun 22, 2023Collaborative filtering (CF) has become a popular method for developing recommender systems (RS) where ratings of a user for new items is predicted based on her past preferences and available preference information of other users. Despite the popularity of CF-based methods, their performance is often greatly limited by the sparsity of observed entries. In this study, we explore the data augmentation and refinement aspects of Maximum Margin Matrix Factorization (MMMF), a widely accepted CF technique for the rating predictions, which have not been investigated before. We exploit the inherent characteristics of CF algorithms to assess the confidence level of individual ratings and propose a semi-supervised approach for rating augmentation based on self-training. We hypothesize that any CF algorithm's predictions with low confidence are due to some deficiency in the training data and hence, the performance of the algorithm can be improved by adopting a systematic data augmentation strategy. We iteratively use some of the ratings predicted with high confidence to augment the training data and remove low-confidence entries through a refinement process. By repeating this process, the system learns to improve prediction accuracy. Our method is experimentally evaluated on several state-of-the-art CF algorithms and leads to informative rating augmentation, improving the performance of the baseline approaches.
Transfer of codebook latent factors for cross-domain recommendation with non-overlapping data
Mar 26, 2022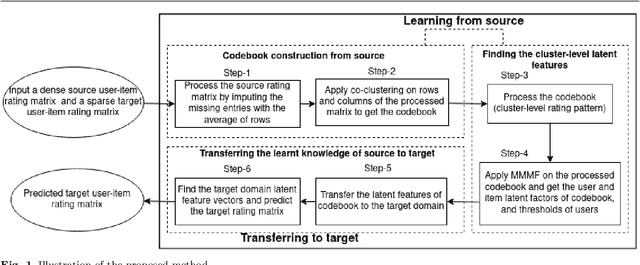

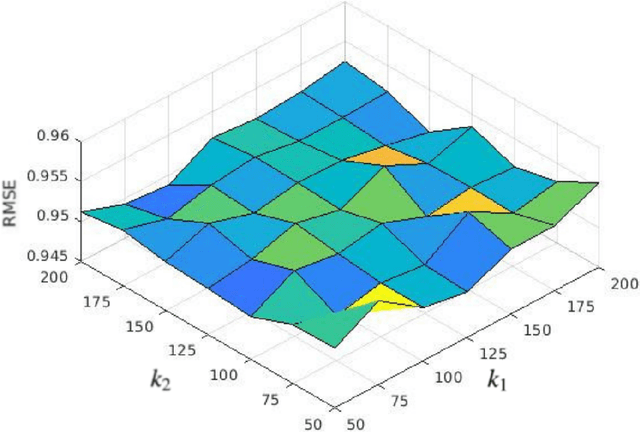

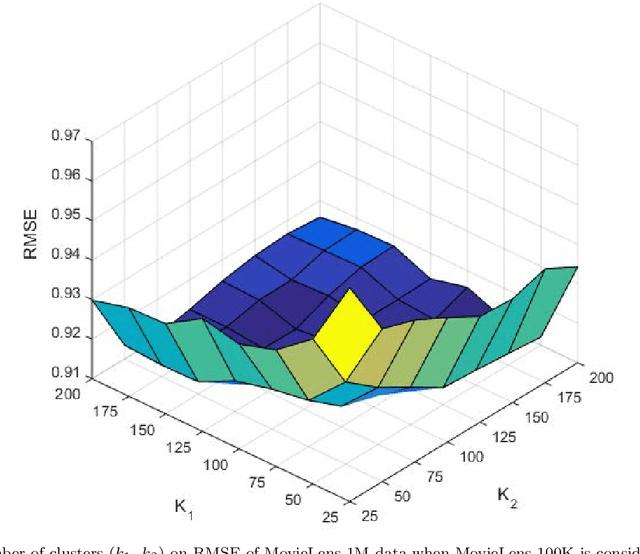
Recommender systems based on collaborative filtering play a vital role in many E-commerce applications as they guide the user in finding their items of interest based on the user's past transactions and feedback of other similar customers. Data Sparsity is one of the major drawbacks with collaborative filtering technique arising due to the less number of transactions and feedback data. In order to reduce the sparsity problem, techniques called transfer learning/cross-domain recommendation has emerged. In transfer learning methods, the data from other dense domain(s) (source) is considered in order to predict the missing ratings in the sparse domain (target). In this paper, we come up with a novel transfer learning approach for cross-domain recommendation, wherein the cluster-level rating pattern(codebook) of the source domain is obtained via a co-clustering technique. Thereafter we apply the Maximum Margin Matrix factorization (MMMF) technique on the codebook in order to learn the user and item latent features of codebook. Prediction of the target rating matrix is achieved by introducing these latent features in a novel way into the optimisation function. In the experiments we demonstrate that our model improves the prediction accuracy of the target matrix on benchmark datasets.
Inductive Conformal Recommender System
Sep 18, 2021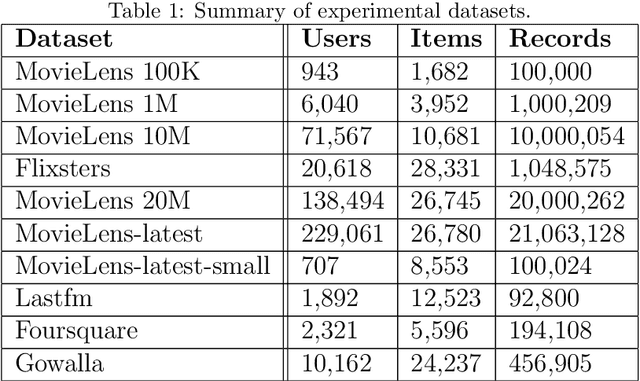
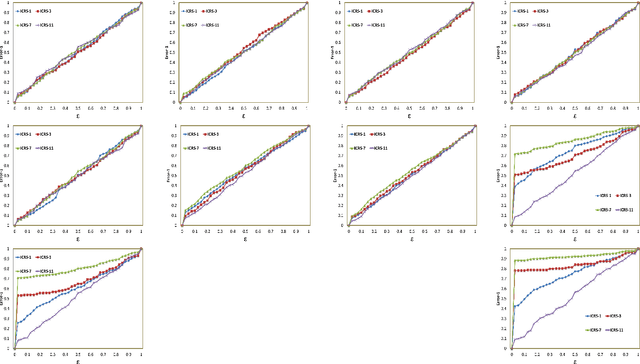

Traditional recommendation algorithms develop techniques that can help people to choose desirable items. However, in many real-world applications, along with a set of recommendations, it is also essential to quantify each recommendation's (un)certainty. The conformal recommender system uses the experience of a user to output a set of recommendations, each associated with a precise confidence value. Given a significance level $\varepsilon$, it provides a bound $\varepsilon$ on the probability of making a wrong recommendation. The conformal framework uses a key concept called nonconformity measure that measure the strangeness of an item concerning other items. One of the significant design challenges of any conformal recommendation framework is integrating nonconformity measure with the recommendation algorithm. In this paper, we introduce an inductive variant of a conformal recommender system. We propose and analyze different nonconformity measures in the inductive setting. We also provide theoretical proofs on the error-bound and the time complexity. Extensive empirical analysis on ten benchmark datasets demonstrates that the inductive variant substantially improves the performance in computation time while preserving the accuracy.
A Hinge-Loss based Codebook Transfer for Cross-Domain Recommendation with Nonoverlapping Data
Aug 02, 2021

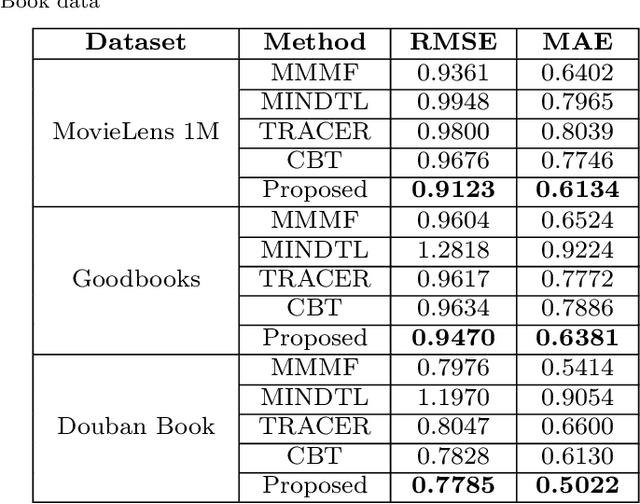
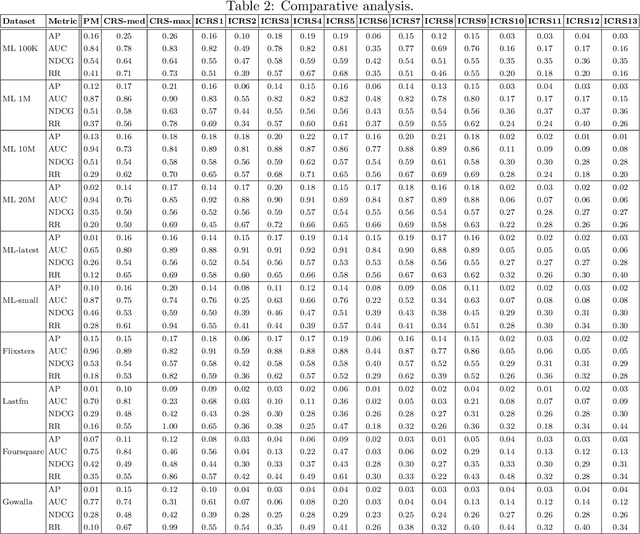
Recommender systems(RS), especially collaborative filtering(CF) based RS, has been playing an important role in many e-commerce applications. As the information being searched over the internet is rapidly increasing, users often face the difficulty of finding items of his/her own interest and RS often provides help in such tasks. Recent studies show that, as the item space increases, and the number of items rated by the users become very less, issues like sparsity arise. To mitigate the sparsity problem, transfer learning techniques are being used wherein the data from dense domain(source) is considered in order to predict the missing entries in the sparse domain(target). In this paper, we propose a transfer learning approach for cross-domain recommendation when both domains have no overlap of users and items. In our approach the transferring of knowledge from source to target domain is done in a novel way. We make use of co-clustering technique to obtain the codebook (cluster-level rating pattern) of source domain. By making use of hinge loss function we transfer the learnt codebook of the source domain to target. The use of hinge loss as a loss function is novel and has not been tried before in transfer learning. We demonstrate that our technique improves the approximation of the target matrix on benchmark datasets.
Committee Selection with Attribute Level Preferences
Jan 29, 2019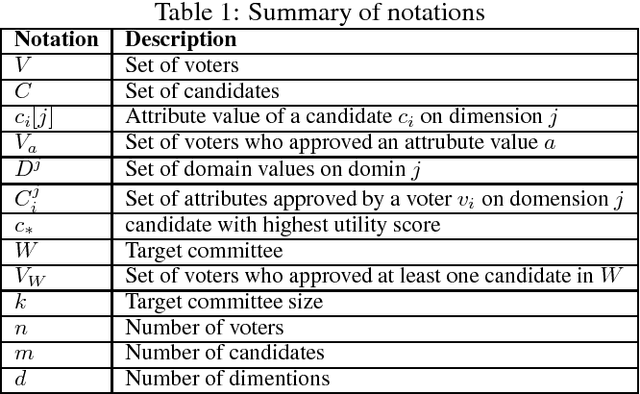

Approval ballot based committee formation is concerned with aggregating individual approvals of voters. Voters submit their approvals of candidates and these approvals are aggregated to arrive at the optimal committee of specified size. There are several aggregation techniques proposed in the literature and these techniques differ among themselves on the criterion function they optimize. Voters preferences for a candidate is based on his/her opinion on candidate suitability. We note that candidates have attributes that make him/her suitable or otherwise. Hence, it is relevant to approve attributes and select candidates who have the approved attributes. This paper addresses the committee selection problem when voters submit their approvals on attributes. Though attribute based preference is addressed in several contexts, committee selection problem with attribute approval has not been attempted earlier. We note that extending the theory of candidate approval to attribute approval in committee selection problem is not trivial. In this paper, we study different aspects of this problem and show that none of the existing aggregation rules satisfies Unanimity and Justified Representation when attribute based approvals are considered. We propose a new aggregation rule that satisfies both the above properties. We also present other analysis of committee selection problem with attribute approval.
Group Preserving Label Embedding for Multi-Label Classification
Dec 24, 2018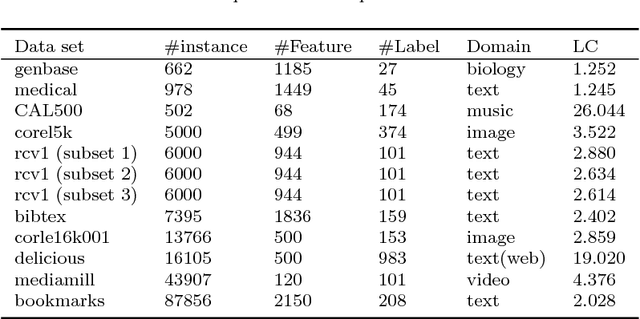
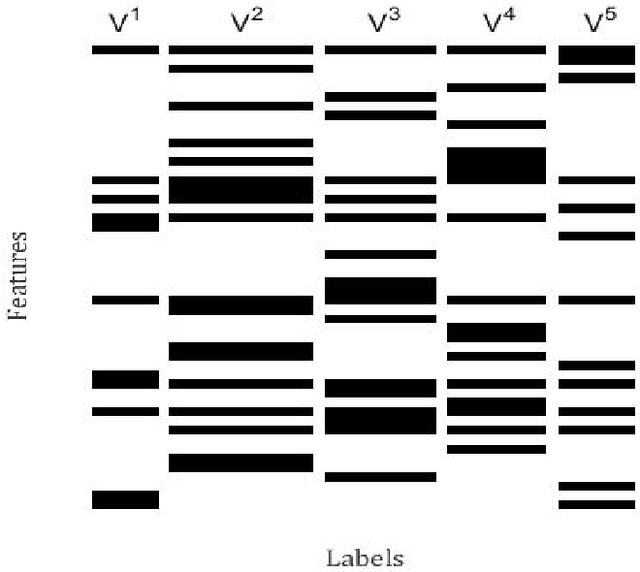
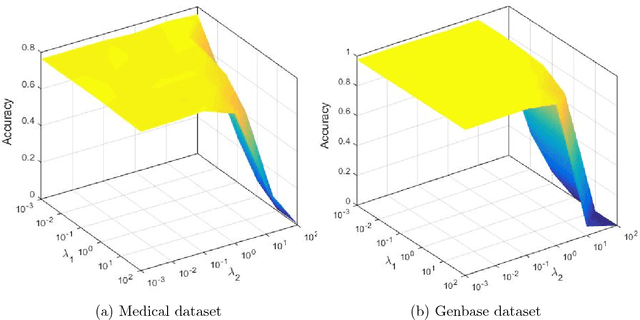

Multi-label learning is concerned with the classification of data with multiple class labels. This is in contrast to the traditional classification problem where every data instance has a single label. Due to the exponential size of output space, exploiting intrinsic information in feature and label spaces has been the major thrust of research in recent years and use of parametrization and embedding have been the prime focus. Researchers have studied several aspects of embedding which include label embedding, input embedding, dimensionality reduction and feature selection. These approaches differ from one another in their capability to capture other intrinsic properties such as label correlation, local invariance etc. We assume here that the input data form groups and as a result, the label matrix exhibits a sparsity pattern and hence the labels corresponding to objects in the same group have similar sparsity. In this paper, we study the embedding of labels together with the group information with an objective to build an efficient multi-label classification. We assume the existence of a low-dimensional space onto which the feature vectors and label vectors can be embedded. In order to achieve this, we address three sub-problems namely; (1) Identification of groups of labels; (2) Embedding of label vectors to a low rank-space so that the sparsity characteristic of individual groups remains invariant; and (3) Determining a linear mapping that embeds the feature vectors onto the same set of points, as in stage 2, in the low-dimensional space. We compare our method with seven well-known algorithms on twelve benchmark data sets. Our experimental analysis manifests the superiority of our proposed method over state-of-art algorithms for multi-label learning.