 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDReX: An Explainable Deep Learning-based Multimodal Recommendation Framework
Feb 23, 2026Multimodal recommender systems leverage diverse data sources, such as user interactions, content features, and contextual information, to address challenges like cold-start and data sparsity. However, existing methods often suffer from one or more key limitations: processing different modalities in isolation, requiring complete multimodal data for each interaction during training, or independent learning of user and item representations. These factors contribute to increased complexity and potential misalignment between user and item embeddings. To address these challenges, we propose DReX, a unified multimodal recommendation framework that incrementally refines user and item representations by leveraging interaction-level features from multimodal feedback. Our model employs gated recurrent units to selectively integrate these fine-grained features into global representations. This incremental update mechanism provides three key advantages: (1) simultaneous modeling of both nuanced interaction details and broader preference patterns, (2) eliminates the need for separate user and item feature extraction processes, leading to enhanced alignment in their learned representation, and (3) inherent robustness to varying or missing modalities. We evaluate the performance of the proposed approach on three real-world datasets containing reviews and ratings as interaction modalities. By considering review text as a modality, our approach automatically generates interpretable keyword profiles for both users and items, which supplement the recommendation process with interpretable preference indicators. Experiment results demonstrate that our approach outperforms state-of-the-art methods across all evaluated datasets.
GrIT: Group Informed Transformer for Sequential Recommendation
Feb 23, 2026Sequential recommender systems aim to predict a user's future interests by extracting temporal patterns from their behavioral history. Existing approaches typically employ transformer-based architectures to process long sequences of user interactions, capturing preference shifts by modeling temporal relationships between items. However, these methods often overlook the influence of group-level features that capture the collective behavior of similar users. We hypothesize that explicitly modeling temporally evolving group features alongside individual user histories can significantly enhance next-item recommendation. Our approach introduces latent group representations, where each user's affiliation to these groups is modeled through learnable, time-varying membership weights. The membership weights at each timestep are computed by modeling shifts in user preferences through their interaction history, where we incorporate both short-term and long-term user preferences. We extract a set of statistical features that capture the dynamics of user behavior and further refine them through a series of transformations to produce the final drift-aware membership weights. A group-based representation is derived by weighting latent group embeddings with the learned membership scores. This representation is integrated with the user's sequential representation within the transformer block to jointly capture personal and group-level temporal dynamics, producing richer embeddings that lead to more accurate, context-aware recommendations. We validate the effectiveness of our approach through extensive experiments on five benchmark datasets, where it consistently outperforms state-of-the-art sequential recommendation methods.
Geometric Preference Elicitation for Minimax Regret Optimization in Uncertainty Matroids
Mar 25, 2025


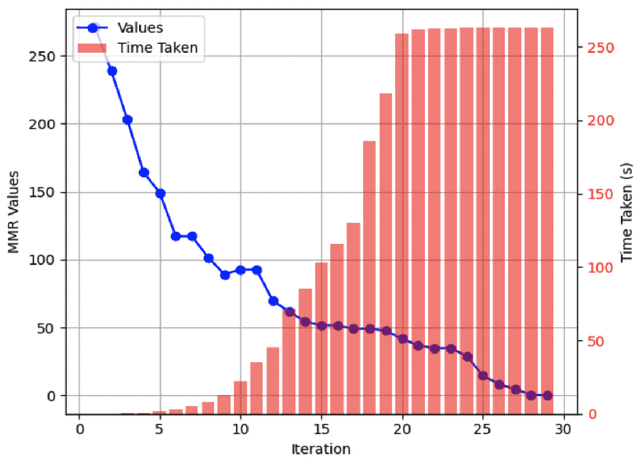
This paper presents an efficient preference elicitation framework for uncertain matroid optimization, where precise weight information is unavailable, but insights into possible weight values are accessible. The core innovation of our approach lies in its ability to systematically elicit user preferences, aligning the optimization process more closely with decision-makers' objectives. By incrementally querying preferences between pairs of elements, we iteratively refine the parametric uncertainty regions, leveraging the structural properties of matroids. Our method aims to achieve the exact optimum by reducing regret with a few elicitation rounds. Additionally, our approach avoids the computation of Minimax Regret and the use of Linear programming solvers at every iteration, unlike previous methods. Experimental results on four standard matroids demonstrate that our method reaches optimality more quickly and with fewer preference queries than existing techniques.
UniRecSys: A Unified Framework for Personalized, Group, Package, and Package-to-Group Recommendations
Aug 08, 2023Recommender systems aim to enhance the overall user experience by providing tailored recommendations for a variety of products and services. These systems help users make more informed decisions, leading to greater user satisfaction with the platform. However, the implementation of these systems largely depends on the context, which can vary from recommending an item or package to a user or a group. This requires careful exploration of several models during the deployment, as there is no comprehensive and unified approach that deals with recommendations at different levels. Furthermore, these individual models must be closely attuned to their generated recommendations depending on the context to prevent significant variation in their generated recommendations. In this paper, we propose a novel unified recommendation framework that addresses all four recommendation tasks, namely personalized, group, package, or package-to-group recommendation, filling the gap in the current research landscape. The proposed framework can be integrated with most of the traditional matrix factorization-based collaborative filtering models. The idea is to enhance the formulation of the existing approaches by incorporating components focusing on the exploitation of the group and package latent factors. These components also help in exploiting a rich latent representation of the user/item by enforcing them to align closely with their corresponding group/package representation. We consider two prominent CF techniques, Regularized Matrix Factorization and Maximum Margin Matrix factorization, as the baseline models and demonstrate their customization to various recommendation tasks. Experiment results on two publicly available datasets are reported, comparing them to other baseline approaches that consider individual rating feedback for group or package recommendations.
Conformal Group Recommender System
Jul 22, 2023
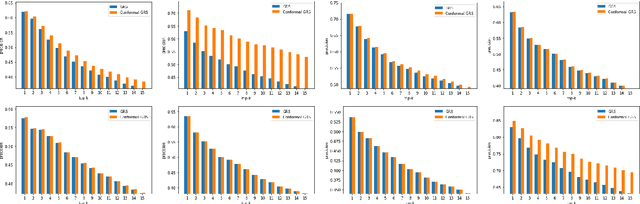
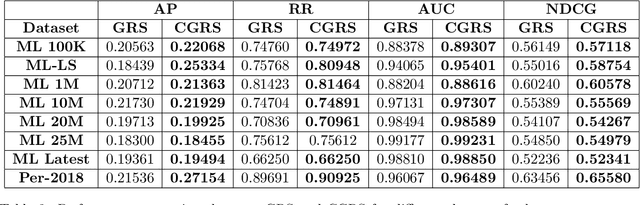
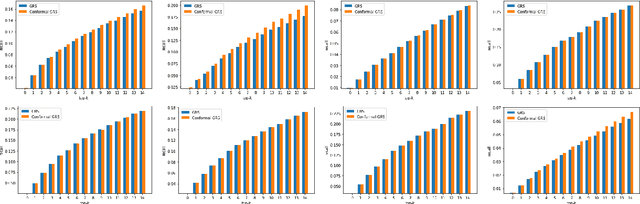
Group recommender systems (GRS) are critical in discovering relevant items from a near-infinite inventory based on group preferences rather than individual preferences, like recommending a movie, restaurant, or tourist destination to a group of individuals. The traditional models of group recommendation are designed to act like a black box with a strict focus on improving recommendation accuracy, and most often, they place the onus on the users to interpret recommendations. In recent years, the focus of Recommender Systems (RS) research has shifted away from merely improving recommendation accuracy towards value additions such as confidence and explanation. In this work, we propose a conformal prediction framework that provides a measure of confidence with prediction in conjunction with a group recommender system to augment the system-generated plain recommendations. In the context of group recommender systems, we propose various nonconformity measures that play a vital role in the efficiency of the conformal framework. We also show that defined nonconformity satisfies the exchangeability property. Experimental results demonstrate the effectiveness of the proposed approach over several benchmark datasets. Furthermore, our proposed approach also satisfies validity and efficiency properties.
Cross-domain Recommender Systems via Multimodal Domain Adaptation
Jul 02, 2023

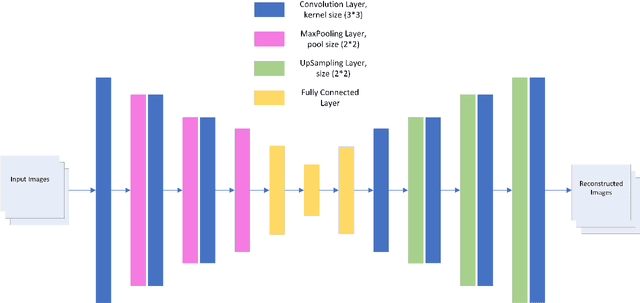

Collaborative Filtering (CF) has emerged as one of the most prominent implementation strategies for building recommender systems. The key idea is to exploit the usage patterns of individuals to generate personalized recommendations. CF techniques, especially for newly launched platforms, often face a critical issue known as the data sparsity problem, which greatly limits their performance. Several approaches in the literature have been proposed to tackle the problem of data sparsity, among which cross-domain collaborative filtering (CDCF) has gained significant attention in the recent past. In order to compensate for the scarcity of available feedback in a target domain, the CDCF approach utilizes information available in other auxiliary domains. Traditional CDCF approaches primarily focus on finding a common set of entities (users or items) across the domains, which then act as a conduit for knowledge transfer. Nevertheless, most real-world datasets are collected from different domains, so they often lack information about anchor points or reference information for entity alignment. This paper introduces a domain adaptation technique to align the embeddings of entities across the two domains. Our approach first exploits the available textual and visual information to independently learn a multi-view latent representation for each entity in the auxiliary and target domains. The different representations of the entity are then fused to generate the corresponding unified representation. A domain classifier is then trained to learn the embedding for the domain alignment by fixing the unified features as the anchor points. Experiments on two publicly benchmark datasets indicate the effectiveness of our proposed approach.
Data augmentation for recommender system: A semi-supervised approach using maximum margin matrix factorization
Jun 22, 2023



Collaborative filtering (CF) has become a popular method for developing recommender systems (RS) where ratings of a user for new items is predicted based on her past preferences and available preference information of other users. Despite the popularity of CF-based methods, their performance is often greatly limited by the sparsity of observed entries. In this study, we explore the data augmentation and refinement aspects of Maximum Margin Matrix Factorization (MMMF), a widely accepted CF technique for the rating predictions, which have not been investigated before. We exploit the inherent characteristics of CF algorithms to assess the confidence level of individual ratings and propose a semi-supervised approach for rating augmentation based on self-training. We hypothesize that any CF algorithm's predictions with low confidence are due to some deficiency in the training data and hence, the performance of the algorithm can be improved by adopting a systematic data augmentation strategy. We iteratively use some of the ratings predicted with high confidence to augment the training data and remove low-confidence entries through a refinement process. By repeating this process, the system learns to improve prediction accuracy. Our method is experimentally evaluated on several state-of-the-art CF algorithms and leads to informative rating augmentation, improving the performance of the baseline approaches.
On Robustness of Finetuned Transformer-based NLP Models
May 23, 2023



Transformer-based pretrained models like BERT, GPT-2 and T5 have been finetuned for a large number of natural language processing (NLP) tasks, and have been shown to be very effective. However, while finetuning, what changes across layers in these models with respect to pretrained checkpoints is under-studied. Further, how robust are these models to perturbations in input text? Does the robustness vary depending on the NLP task for which the models have been finetuned? While there exists some work on studying robustness of BERT finetuned for a few NLP tasks, there is no rigorous study which compares this robustness across encoder only, decoder only and encoder-decoder models. In this paper, we study the robustness of three language models (BERT, GPT-2 and T5) with eight different text perturbations on the General Language Understanding Evaluation (GLUE) benchmark. Also, we use two metrics (CKA and STIR) to quantify changes between pretrained and finetuned language model representations across layers. GPT-2 representations are more robust than BERT and T5 across multiple types of input perturbation. Although models exhibit good robustness broadly, dropping nouns, verbs or changing characters are the most impactful. Overall, this study provides valuable insights into perturbation-specific weaknesses of popular Transformer-based models which should be kept in mind when passing inputs.
Inductive Conformal Recommender System
Sep 18, 2021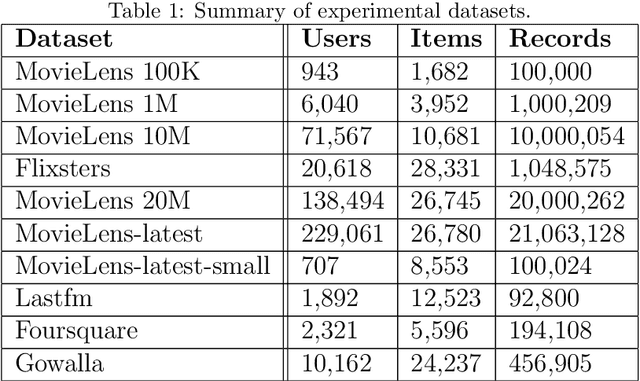
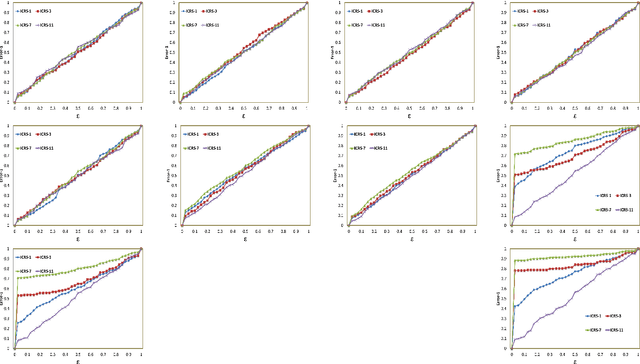
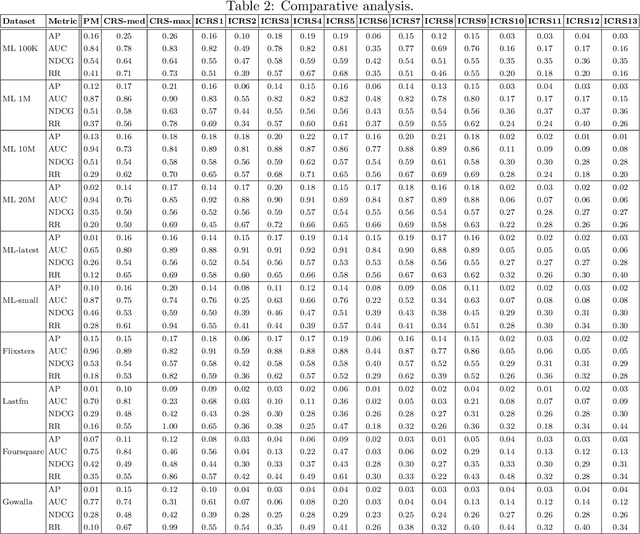

Traditional recommendation algorithms develop techniques that can help people to choose desirable items. However, in many real-world applications, along with a set of recommendations, it is also essential to quantify each recommendation's (un)certainty. The conformal recommender system uses the experience of a user to output a set of recommendations, each associated with a precise confidence value. Given a significance level $\varepsilon$, it provides a bound $\varepsilon$ on the probability of making a wrong recommendation. The conformal framework uses a key concept called nonconformity measure that measure the strangeness of an item concerning other items. One of the significant design challenges of any conformal recommendation framework is integrating nonconformity measure with the recommendation algorithm. In this paper, we introduce an inductive variant of a conformal recommender system. We propose and analyze different nonconformity measures in the inductive setting. We also provide theoretical proofs on the error-bound and the time complexity. Extensive empirical analysis on ten benchmark datasets demonstrates that the inductive variant substantially improves the performance in computation time while preserving the accuracy.
Committee Selection with Attribute Level Preferences
Jan 29, 2019

Approval ballot based committee formation is concerned with aggregating individual approvals of voters. Voters submit their approvals of candidates and these approvals are aggregated to arrive at the optimal committee of specified size. There are several aggregation techniques proposed in the literature and these techniques differ among themselves on the criterion function they optimize. Voters preferences for a candidate is based on his/her opinion on candidate suitability. We note that candidates have attributes that make him/her suitable or otherwise. Hence, it is relevant to approve attributes and select candidates who have the approved attributes. This paper addresses the committee selection problem when voters submit their approvals on attributes. Though attribute based preference is addressed in several contexts, committee selection problem with attribute approval has not been attempted earlier. We note that extending the theory of candidate approval to attribute approval in committee selection problem is not trivial. In this paper, we study different aspects of this problem and show that none of the existing aggregation rules satisfies Unanimity and Justified Representation when attribute based approvals are considered. We propose a new aggregation rule that satisfies both the above properties. We also present other analysis of committee selection problem with attribute approval.