 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self supervised learning framework for imbalanced medical imaging datasets
Apr 02, 2026Two problems often plague medical imaging analysis: 1) Non-availability of large quantities of labeled training data, and 2) Dealing with imbalanced data, i.e., abundant data are available for frequent classes, whereas data are highly limited for the rare class. Self supervised learning (SSL) methods have been proposed to deal with the first problem to a certain extent, but the issue of investigating the robustness of SSL to imbalanced data has rarely been addressed in the domain of medical image classification. In this work, we make the following contributions: 1) The MIMV method proposed by us in an earlier work is extended with a new augmentation strategy to construct asymmetric multi-image, multi-view (AMIMV) pairs to address both data scarcity and dataset imbalance in medical image classification. 2) We carry out a data analysis to evaluate the robustness of AMIMV under varying degrees of class imbalance in medical imaging . 3) We evaluate eight representative SSL methods in 11 medical imaging datasets (MedMNIST) under long-tailed distributions and limited supervision. Our experimental results on the MedMNIST dataset show an improvement of 4.25% on retinaMNIST, 1.88% on tissueMNIST, and 3.1% on DermaMNIST.
Transfer of codebook latent factors for cross-domain recommendation with non-overlapping data
Mar 26, 2022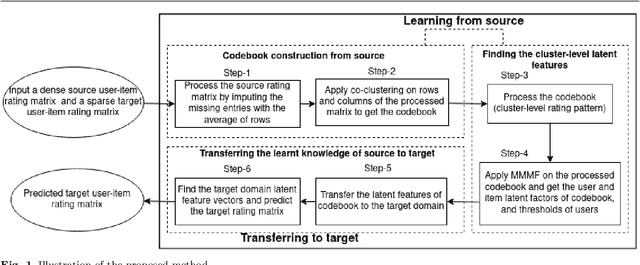

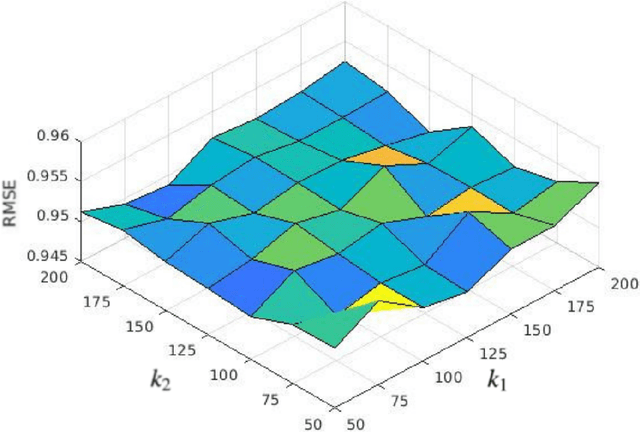

Recommender systems based on collaborative filtering play a vital role in many E-commerce applications as they guide the user in finding their items of interest based on the user's past transactions and feedback of other similar customers. Data Sparsity is one of the major drawbacks with collaborative filtering technique arising due to the less number of transactions and feedback data. In order to reduce the sparsity problem, techniques called transfer learning/cross-domain recommendation has emerged. In transfer learning methods, the data from other dense domain(s) (source) is considered in order to predict the missing ratings in the sparse domain (target). In this paper, we come up with a novel transfer learning approach for cross-domain recommendation, wherein the cluster-level rating pattern(codebook) of the source domain is obtained via a co-clustering technique. Thereafter we apply the Maximum Margin Matrix factorization (MMMF) technique on the codebook in order to learn the user and item latent features of codebook. Prediction of the target rating matrix is achieved by introducing these latent features in a novel way into the optimisation function. In the experiments we demonstrate that our model improves the prediction accuracy of the target matrix on benchmark datasets.
Decomposing the Deep: Finding Class Specific Filters in Deep CNNs
Jan 04, 2022



Interpretability of Deep Neural Networks has become a major area of exploration. Although these networks have achieved state of the art accuracy in many tasks, it is extremely difficult to interpret and explain their decisions. In this work we analyze the final and penultimate layers of Deep Convolutional Networks and provide an efficient method for identifying subsets of features that contribute most towards the network's decision for a class. We demonstrate that the number of such features per class is much lower in comparison to the dimension of the final layer and therefore the decision surface of Deep CNNs lies on a low dimensional manifold and is proportional to the network depth. Our methods allow to decompose the final layer into separate subspaces which is far more interpretable and has a lower computational cost as compared to the final layer of the full network.
Inductive Conformal Recommender System
Sep 18, 2021
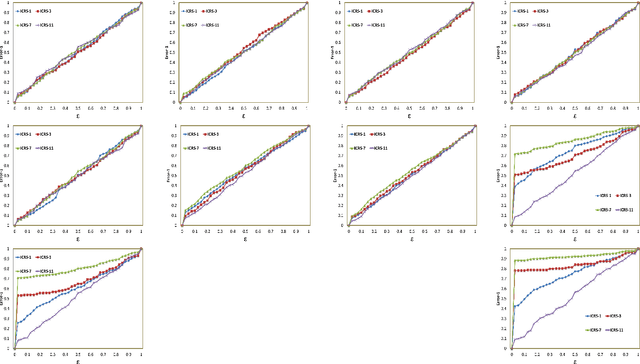
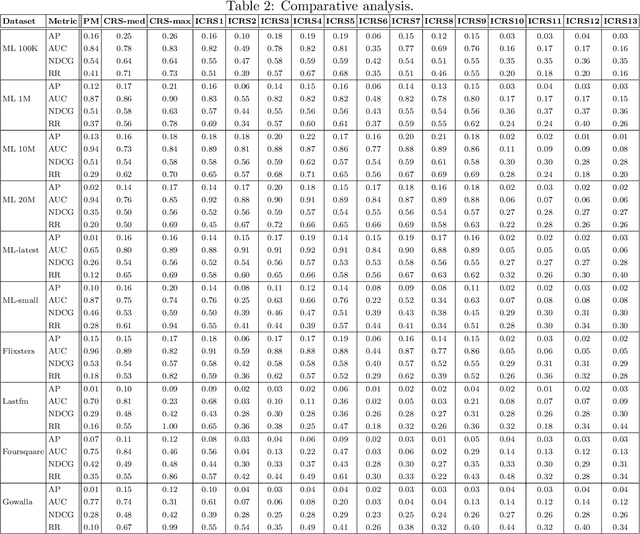

Traditional recommendation algorithms develop techniques that can help people to choose desirable items. However, in many real-world applications, along with a set of recommendations, it is also essential to quantify each recommendation's (un)certainty. The conformal recommender system uses the experience of a user to output a set of recommendations, each associated with a precise confidence value. Given a significance level $\varepsilon$, it provides a bound $\varepsilon$ on the probability of making a wrong recommendation. The conformal framework uses a key concept called nonconformity measure that measure the strangeness of an item concerning other items. One of the significant design challenges of any conformal recommendation framework is integrating nonconformity measure with the recommendation algorithm. In this paper, we introduce an inductive variant of a conformal recommender system. We propose and analyze different nonconformity measures in the inductive setting. We also provide theoretical proofs on the error-bound and the time complexity. Extensive empirical analysis on ten benchmark datasets demonstrates that the inductive variant substantially improves the performance in computation time while preserving the accuracy.
A Hinge-Loss based Codebook Transfer for Cross-Domain Recommendation with Nonoverlapping Data
Aug 02, 2021

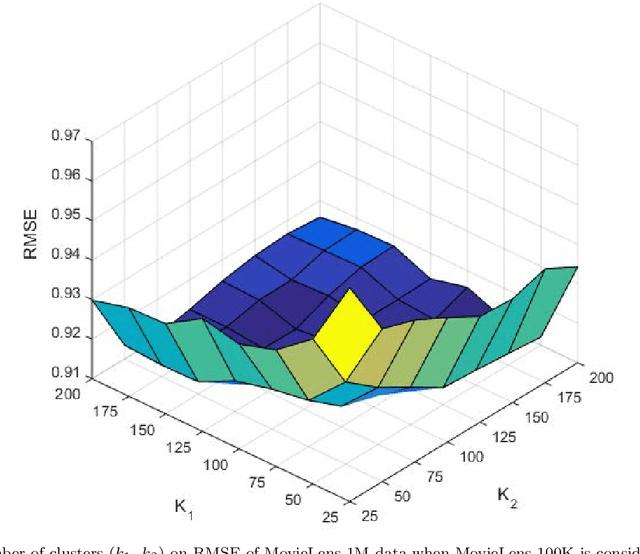
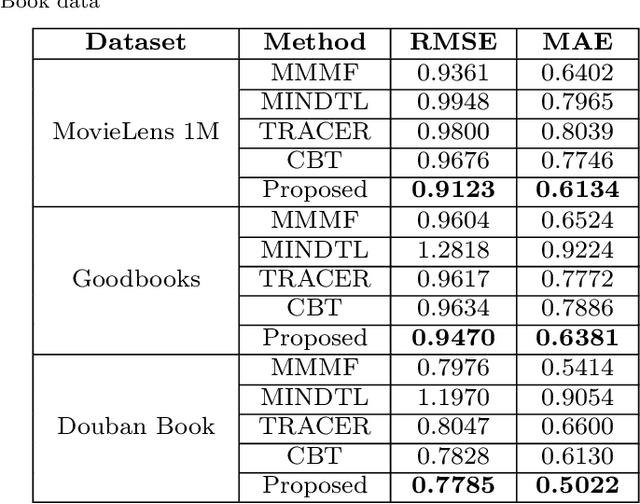
Recommender systems(RS), especially collaborative filtering(CF) based RS, has been playing an important role in many e-commerce applications. As the information being searched over the internet is rapidly increasing, users often face the difficulty of finding items of his/her own interest and RS often provides help in such tasks. Recent studies show that, as the item space increases, and the number of items rated by the users become very less, issues like sparsity arise. To mitigate the sparsity problem, transfer learning techniques are being used wherein the data from dense domain(source) is considered in order to predict the missing entries in the sparse domain(target). In this paper, we propose a transfer learning approach for cross-domain recommendation when both domains have no overlap of users and items. In our approach the transferring of knowledge from source to target domain is done in a novel way. We make use of co-clustering technique to obtain the codebook (cluster-level rating pattern) of source domain. By making use of hinge loss function we transfer the learnt codebook of the source domain to target. The use of hinge loss as a loss function is novel and has not been tried before in transfer learning. We demonstrate that our technique improves the approximation of the target matrix on benchmark datasets.
Block based Singular Value Decomposition approach to matrix factorization for recommender systems
Jul 17, 2019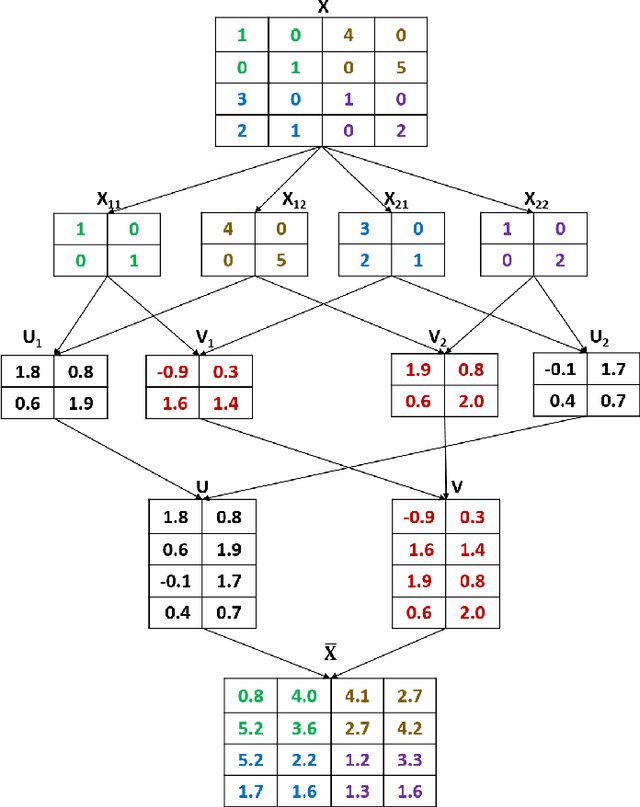
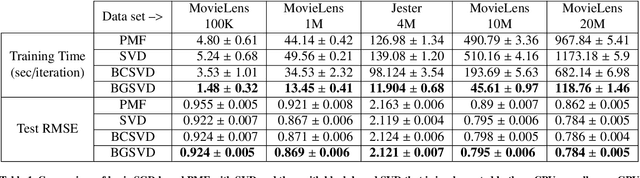
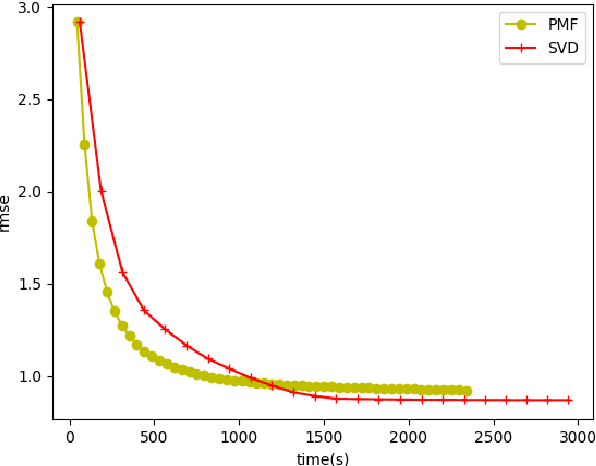
With the abundance of data in recent years, interesting challenges are posed in the area of recommender systems. Producing high quality recommendations with scalability and performance is the need of the hour. Singular Value Decomposition(SVD) based recommendation algorithms have been leveraged to produce better results. In this paper, we extend the SVD technique further for scalability and performance in the context of 1) multi-threading 2) multiple computational units (with the use of Graphical Processing Units) and 3) distributed computation. We propose block based matrix factorization (BMF) paired with SVD. This enabled us to take advantage of SVD over basic matrix factorization(MF) while taking advantage of parallelism and scalability through BMF. We used Compute Unified Device Architecture (CUDA) platform and related hardware for leveraging Graphical Processing Unit (GPU) along with block based SVD to demonstrate the advantages in terms of performance and memory.
Committee Selection with Attribute Level Preferences
Jan 29, 2019

Approval ballot based committee formation is concerned with aggregating individual approvals of voters. Voters submit their approvals of candidates and these approvals are aggregated to arrive at the optimal committee of specified size. There are several aggregation techniques proposed in the literature and these techniques differ among themselves on the criterion function they optimize. Voters preferences for a candidate is based on his/her opinion on candidate suitability. We note that candidates have attributes that make him/her suitable or otherwise. Hence, it is relevant to approve attributes and select candidates who have the approved attributes. This paper addresses the committee selection problem when voters submit their approvals on attributes. Though attribute based preference is addressed in several contexts, committee selection problem with attribute approval has not been attempted earlier. We note that extending the theory of candidate approval to attribute approval in committee selection problem is not trivial. In this paper, we study different aspects of this problem and show that none of the existing aggregation rules satisfies Unanimity and Justified Representation when attribute based approvals are considered. We propose a new aggregation rule that satisfies both the above properties. We also present other analysis of committee selection problem with attribute approval.
Group Preserving Label Embedding for Multi-Label Classification
Dec 24, 2018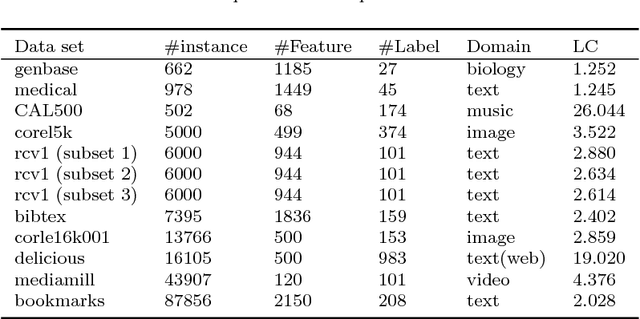
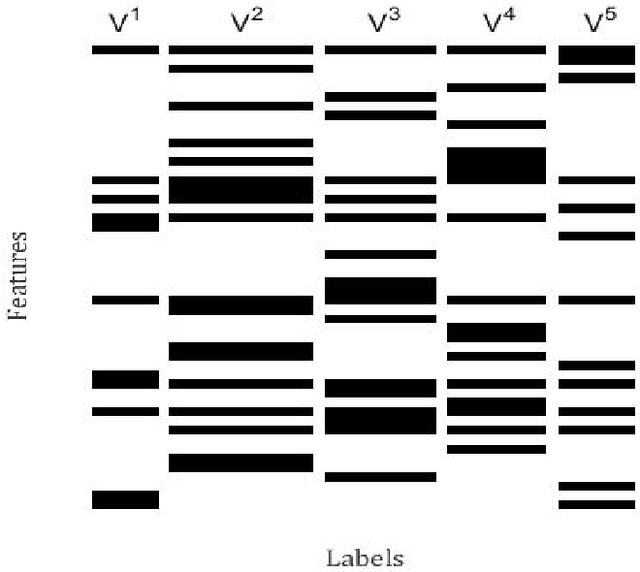
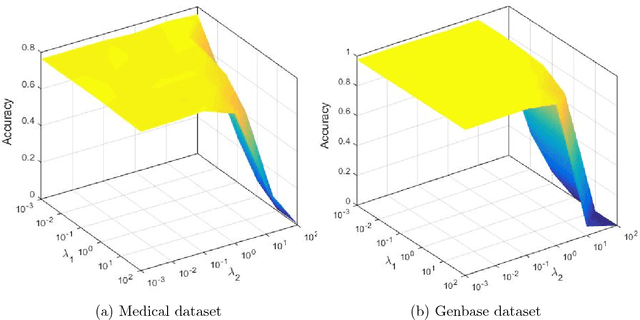

Multi-label learning is concerned with the classification of data with multiple class labels. This is in contrast to the traditional classification problem where every data instance has a single label. Due to the exponential size of output space, exploiting intrinsic information in feature and label spaces has been the major thrust of research in recent years and use of parametrization and embedding have been the prime focus. Researchers have studied several aspects of embedding which include label embedding, input embedding, dimensionality reduction and feature selection. These approaches differ from one another in their capability to capture other intrinsic properties such as label correlation, local invariance etc. We assume here that the input data form groups and as a result, the label matrix exhibits a sparsity pattern and hence the labels corresponding to objects in the same group have similar sparsity. In this paper, we study the embedding of labels together with the group information with an objective to build an efficient multi-label classification. We assume the existence of a low-dimensional space onto which the feature vectors and label vectors can be embedded. In order to achieve this, we address three sub-problems namely; (1) Identification of groups of labels; (2) Embedding of label vectors to a low rank-space so that the sparsity characteristic of individual groups remains invariant; and (3) Determining a linear mapping that embeds the feature vectors onto the same set of points, as in stage 2, in the low-dimensional space. We compare our method with seven well-known algorithms on twelve benchmark data sets. Our experimental analysis manifests the superiority of our proposed method over state-of-art algorithms for multi-label learning.
Multi-cell LSTM Based Neural Language Model
Nov 15, 2018



Language models, being at the heart of many NLP problems, are always of great interest to researchers. Neural language models come with the advantage of distributed representations and long range contexts. With its particular dynamics that allow the cycling of information within the network, `Recurrent neural network' (RNN) becomes an ideal paradigm for neural language modeling. Long Short-Term Memory (LSTM) architecture solves the inadequacies of the standard RNN in modeling long-range contexts. In spite of a plethora of RNN variants, possibility to add multiple memory cells in LSTM nodes was seldom explored. Here we propose a multi-cell node architecture for LSTMs and study its applicability for neural language modeling. The proposed multi-cell LSTM language models outperform the state-of-the-art results on well-known Penn Treebank (PTB) setup.