 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Regression via Data-Dependent Sufficient Statistic Perturbation
May 23, 2024



Sufficient statistic perturbation (SSP) is a widely used method for differentially private linear regression. SSP adopts a data-independent approach where privacy noise from a simple distribution is added to sufficient statistics. However, sufficient statistics can often be expressed as linear queries and better approximated by data-dependent mechanisms. In this paper we introduce data-dependent SSP for linear regression based on post-processing privately released marginals, and find that it outperforms state-of-the-art data-independent SSP. We extend this result to logistic regression by developing an approximate objective that can be expressed in terms of sufficient statistics, resulting in a novel and highly competitive SSP approach for logistic regression. We also make a connection to synthetic data for machine learning: for models with sufficient statistics, training on synthetic data corresponds to data-dependent SSP, with the overall utility determined by how well the mechanism answers these linear queries.
Combining Public and Private Data
Oct 29, 2021
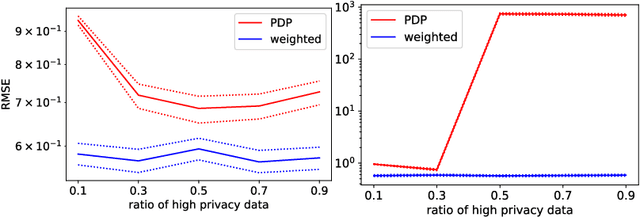
Differential privacy is widely adopted to provide provable privacy guarantees in data analysis. We consider the problem of combining public and private data (and, more generally, data with heterogeneous privacy needs) for estimating aggregate statistics. We introduce a mixed estimator of the mean optimized to minimize the variance. We argue that our mechanism is preferable to techniques that preserve the privacy of individuals by subsampling data proportionally to the privacy needs of users. Similarly, we present a mixed median estimator based on the exponential mechanism. We compare our mechanisms to the methods proposed in Jorgensen et al. [2015]. Our experiments provide empirical evidence that our mechanisms often outperform the baseline methods.
General-Purpose Differentially-Private Confidence Intervals
Jun 14, 2020



One of the most common statistical goals is to estimate a population parameter and quantify uncertainty by constructing a confidence interval. However, the field of differential privacy lacks easy-to-use and general methods for doing so. We partially fill this gap by developing two broadly applicable methods for private confidence-interval construction. The first is based on asymptotics: for two widely used model classes, exponential families and linear regression, a simple private estimator has the same asymptotic normal distribution as the corresponding non-private estimator, so confidence intervals can be constructed using quantiles of the normal distribution. These are computationally cheap and accurate for large data sets, but do not have good coverage for small data sets. The second approach is based on the parametric bootstrap. It applies "out of the box" to a wide class of private estimators and has good coverage at small sample sizes, but with increased computational cost. Both methods are based on post-processing the private estimator and do not consume additional privacy budget.