 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Private Linear Queries Adaptively using the Common Mechanism
Paper and Code

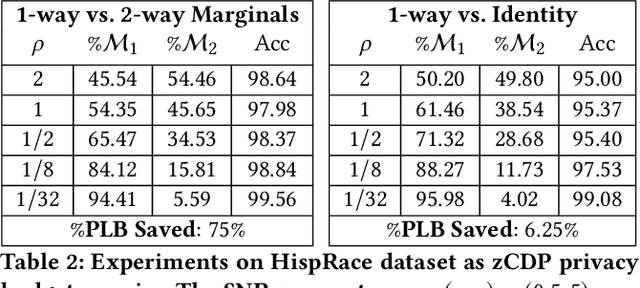
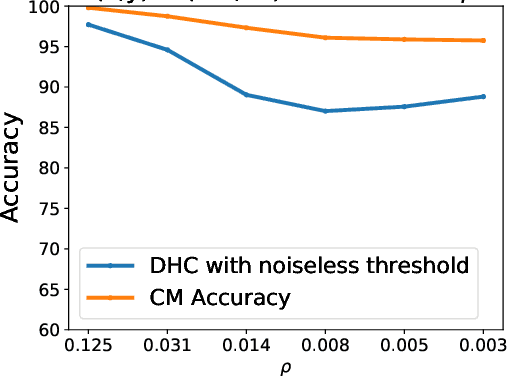
When analyzing confidential data through a privacy filter, a data scientist often needs to decide which queries will best support their intended analysis. For example, an analyst may wish to study noisy two-way marginals in a dataset produced by a mechanism M1. But, if the data are relatively sparse, the analyst may choose to examine noisy one-way marginals, produced by a mechanism M2 instead. Since the choice of whether to use M1 or M2 is data-dependent, a typical differentially private workflow is to first split the privacy loss budget rho into two parts: rho1 and rho2, then use the first part rho1 to determine which mechanism to use, and the remainder rho2 to obtain noisy answers from the chosen mechanism. In a sense, the first step seems wasteful because it takes away part of the privacy loss budget that could have been used to make the query answers more accurate. In this paper, we consider the question of whether the choice between M1 and M2 can be performed without wasting any privacy loss budget. For linear queries, we propose a method for decomposing M1 and M2 into three parts: (1) a mechanism M* that captures their shared information, (2) a mechanism M1' that captures information that is specific to M1, (3) a mechanism M2' that captures information that is specific to M2. Running M* and M1' together is completely equivalent to running M1 (both in terms of query answer accuracy and total privacy cost rho). Similarly, running M* and M2' together is completely equivalent to running M2. Since M* will be used no matter what, the analyst can use its output to decide whether to subsequently run M1'(thus recreating the analysis supported by M1) or M2'(recreating the analysis supported by M2), without wasting privacy loss budget.