 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Prior-Guided and Task-Dependent Multi-Task Representation Learning for Action Recognition Pre-Training
Paper and Code
Apr 27, 2022
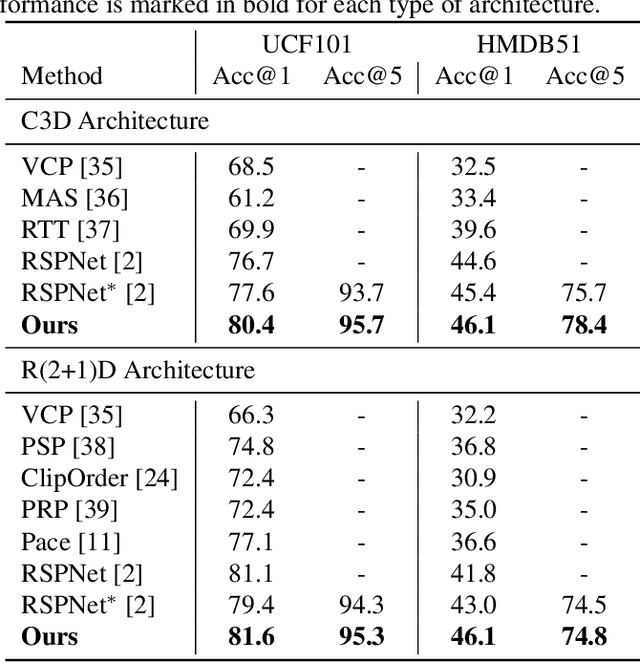
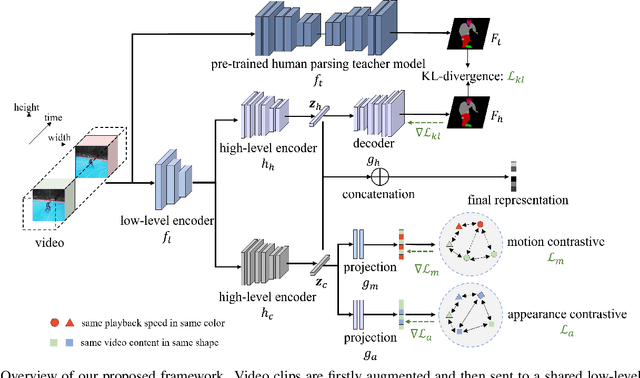
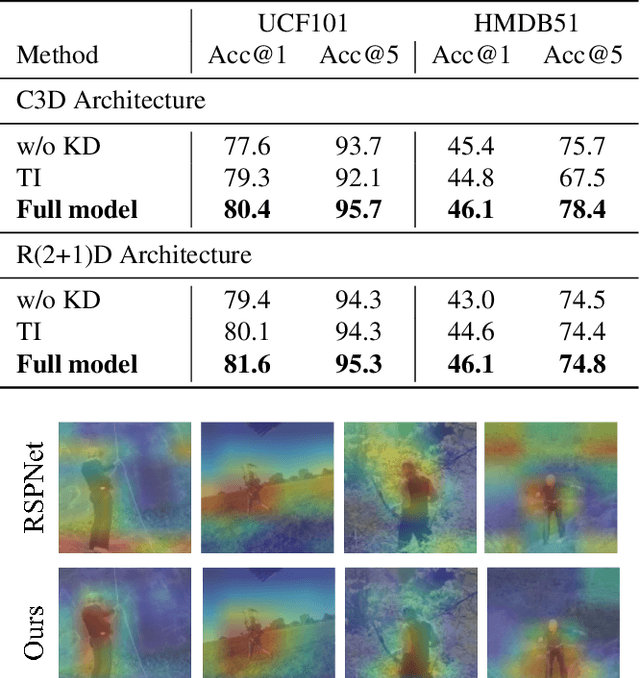
Recently, much progress has been made for self-supervised action recognition. Most existing approaches emphasize the contrastive relations among videos, including appearance and motion consistency. However, two main issues remain for existing pre-training methods: 1) the learned representation is neutral and not informative for a specific task; 2) multi-task learning-based pre-training sometimes leads to sub-optimal solutions due to inconsistent domains of different tasks. To address the above issues, we propose a novel action recognition pre-training framework, which exploits human-centered prior knowledge that generates more informative representation, and avoids the conflict between multiple tasks by using task-dependent representations. Specifically, we distill knowledge from a human parsing model to enrich the semantic capability of representation. In addition, we combine knowledge distillation with contrastive learning to constitute a task-dependent multi-task framework. We achieve state-of-the-art performance on two popular benchmarks for action recognition task, i.e., UCF101 and HMDB51, verifying the effectiveness of our method.