 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserve Pre-trained Knowledge: Transfer Learning With Self-Distillation For Action Recognition
May 01, 2022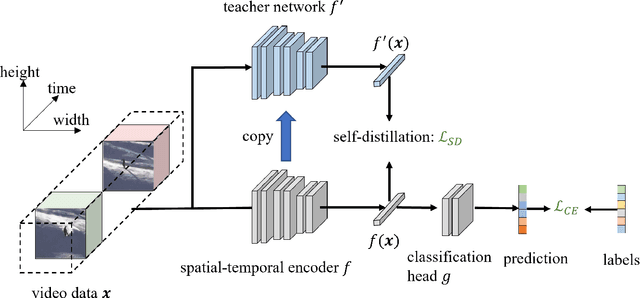
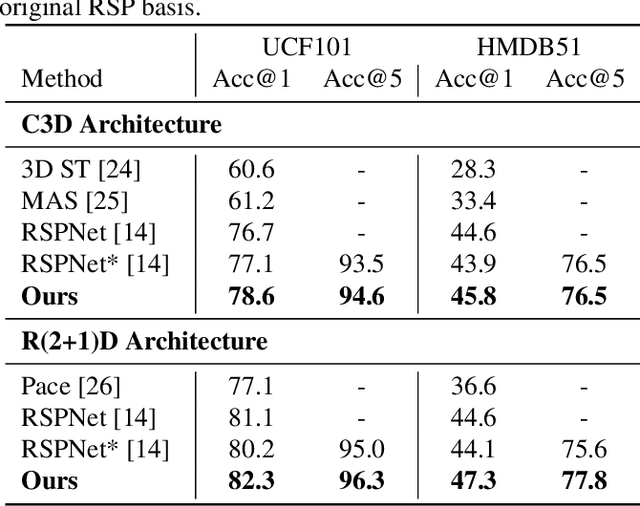
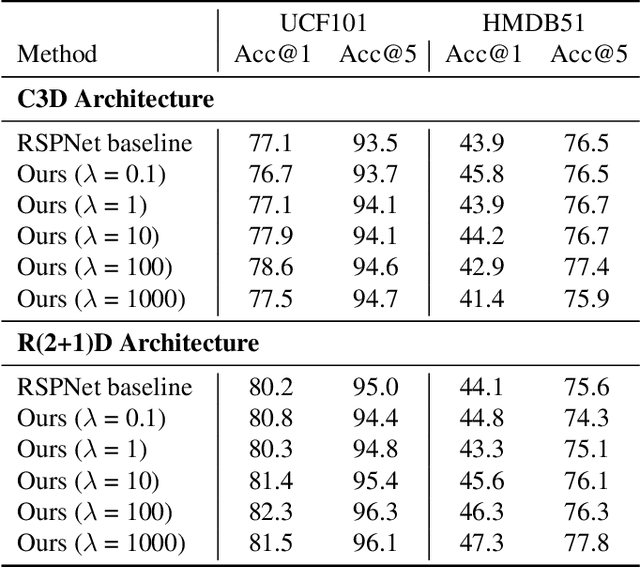
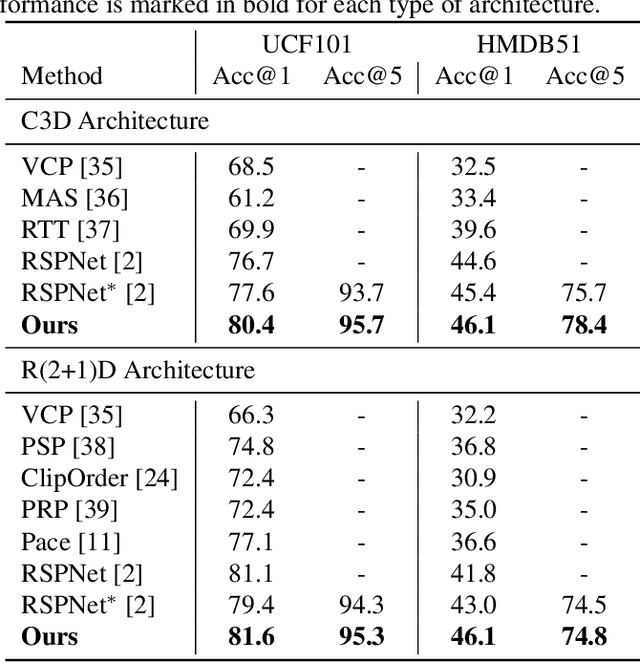
Video-based action recognition is one of the most popular topics in computer vision. With recent advances of selfsupervised video representation learning approaches, action recognition usually follows a two-stage training framework, i.e., self-supervised pre-training on large-scale unlabeled sets and transfer learning on a downstream labeled set. However, catastrophic forgetting of the pre-trained knowledge becomes the main issue in the downstream transfer learning of action recognition, resulting in a sub-optimal solution. In this paper, to alleviate the above issue, we propose a novel transfer learning approach that combines self-distillation in fine-tuning to preserve knowledge from the pre-trained model learned from the large-scale dataset. Specifically, we fix the encoder from the last epoch as the teacher model to guide the training of the encoder from the current epoch in the transfer learning. With such a simple yet effective learning strategy, we outperform state-of-the-art methods on widely used UCF101 and HMDB51 datasets in action recognition task.
Human-Centered Prior-Guided and Task-Dependent Multi-Task Representation Learning for Action Recognition Pre-Training
Apr 27, 2022
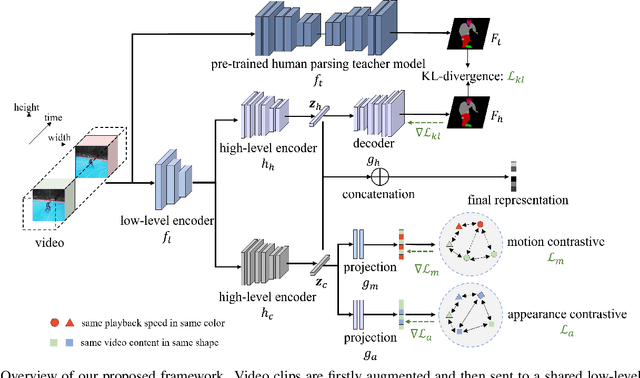
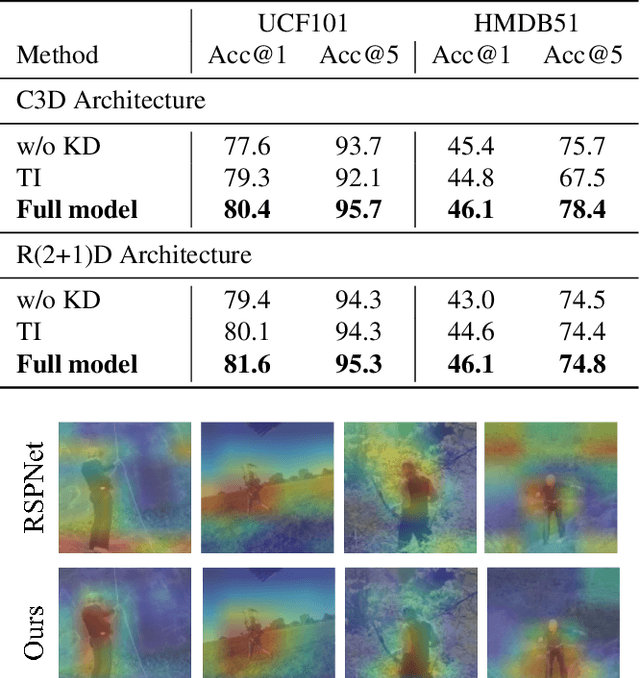
Recently, much progress has been made for self-supervised action recognition. Most existing approaches emphasize the contrastive relations among videos, including appearance and motion consistency. However, two main issues remain for existing pre-training methods: 1) the learned representation is neutral and not informative for a specific task; 2) multi-task learning-based pre-training sometimes leads to sub-optimal solutions due to inconsistent domains of different tasks. To address the above issues, we propose a novel action recognition pre-training framework, which exploits human-centered prior knowledge that generates more informative representation, and avoids the conflict between multiple tasks by using task-dependent representations. Specifically, we distill knowledge from a human parsing model to enrich the semantic capability of representation. In addition, we combine knowledge distillation with contrastive learning to constitute a task-dependent multi-task framework. We achieve state-of-the-art performance on two popular benchmarks for action recognition task, i.e., UCF101 and HMDB51, verifying the effectiveness of our method.
Learning Sports Camera Selection from Internet Videos
Sep 08, 2018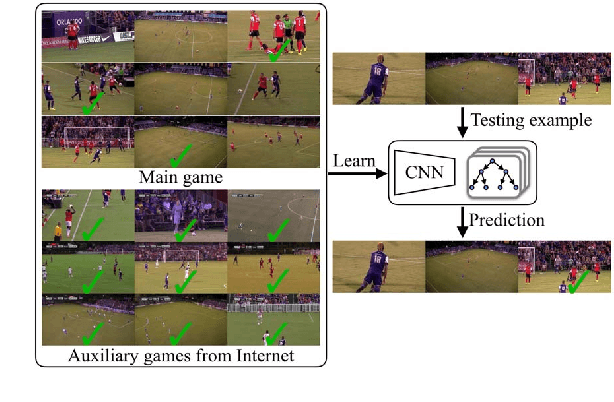


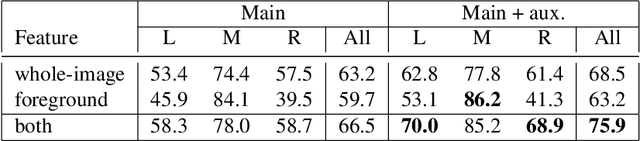
This work addresses camera selection, the task of predicting which camera should be "on air" from multiple candidate cameras for soccer broadcast. The task is challenging because of the scarcity of learning data with all candidate views. Meanwhile, broadcast videos are freely available on the Internet (e.g. Youtube). However, these videos only record the selected camera views, omitting the other candidate views. To overcome this problem, we first introduce a random survival forest (RSF) method to impute the incomplete data effectively. Then, we propose a spatial-appearance heatmap to describe foreground objects (e.g. players and balls) in an image. To evaluate the performance of our system, we collect the largest-ever dataset for soccer broadcasting camera selection. It has one main game which has all candidate views and twelve auxiliary games which only have the broadcast view. Our method significantly outperforms state-of-the-art methods on this challenging dataset. Further analysis suggests that the improvement in performance is indeed from the extra information from auxiliary games.
Light Cascaded Convolutional Neural Networks for Accurate Player Detection
Sep 29, 2017
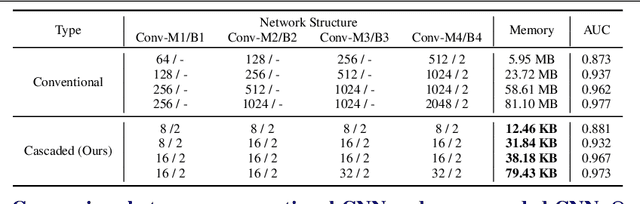
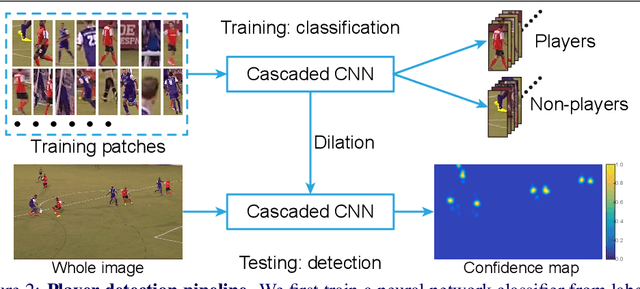
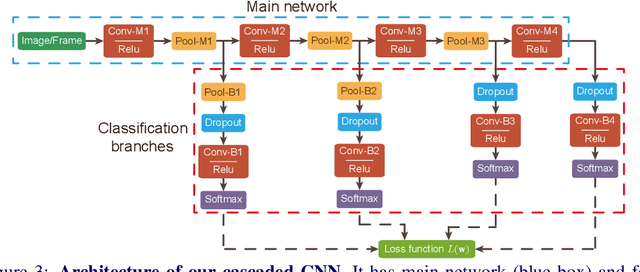
Vision based player detection is important in sports applications. Accuracy, efficiency, and low memory consumption are desirable for real-time tasks such as intelligent broadcasting and automatic event classification. In this paper, we present a cascaded convolutional neural network (CNN) that satisfies all three of these requirements. Our method first trains a binary (player/non-player) classification network from labeled image patches. Then, our method efficiently applies the network to a whole image in testing. We conducted experiments on basketball and soccer games. Experimental results demonstrate that our method can accurately detect players under challenging conditions such as varying illumination, highly dynamic camera movements and motion blur. Comparing with conventional CNNs, our approach achieves state-of-the-art accuracy on both games with 1000x fewer parameters (i.e., it is light}.
Generalized Haar Filter based Deep Networks for Real-Time Object Detection in Traffic Scene
Oct 30, 2016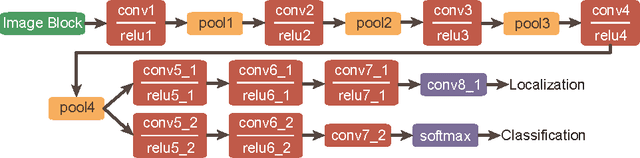
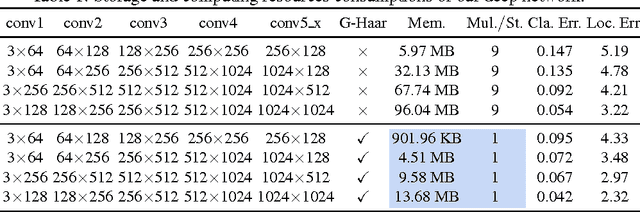
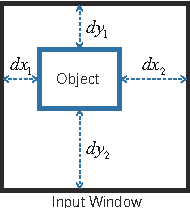

Vision-based object detection is one of the fundamental functions in numerous traffic scene applications such as self-driving vehicle systems and advance driver assistance systems (ADAS). However, it is also a challenging task due to the diversity of traffic scene and the storage, power and computing source limitations of the platforms for traffic scene applications. This paper presents a generalized Haar filter based deep network which is suitable for the object detection tasks in traffic scene. In this approach, we first decompose a object detection task into several easier local regression tasks. Then, we handle the local regression tasks by using several tiny deep networks which simultaneously output the bounding boxes, categories and confidence scores of detected objects. To reduce the consumption of storage and computing resources, the weights of the deep networks are constrained to the form of generalized Haar filter in training phase. Additionally, we introduce the strategy of sparse windows generation to improve the efficiency of the algorithm. Finally, we perform several experiments to validate the performance of our proposed approach. Experimental results demonstrate that the proposed approach is both efficient and effective in traffic scene compared with the state-of-the-art.