 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Haar Filter based Deep Networks for Real-Time Object Detection in Traffic Scene
Oct 30, 2016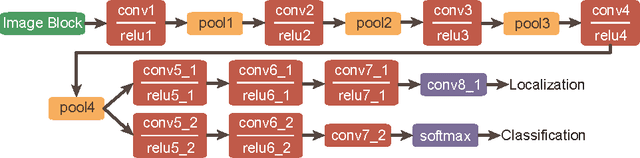
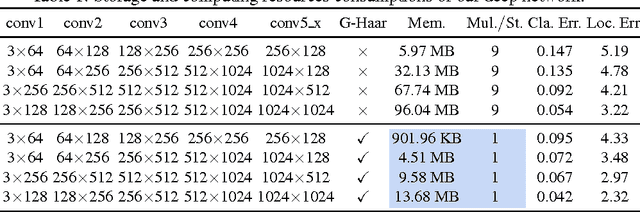
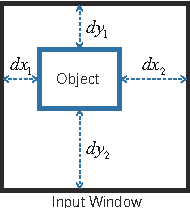

Vision-based object detection is one of the fundamental functions in numerous traffic scene applications such as self-driving vehicle systems and advance driver assistance systems (ADAS). However, it is also a challenging task due to the diversity of traffic scene and the storage, power and computing source limitations of the platforms for traffic scene applications. This paper presents a generalized Haar filter based deep network which is suitable for the object detection tasks in traffic scene. In this approach, we first decompose a object detection task into several easier local regression tasks. Then, we handle the local regression tasks by using several tiny deep networks which simultaneously output the bounding boxes, categories and confidence scores of detected objects. To reduce the consumption of storage and computing resources, the weights of the deep networks are constrained to the form of generalized Haar filter in training phase. Additionally, we introduce the strategy of sparse windows generation to improve the efficiency of the algorithm. Finally, we perform several experiments to validate the performance of our proposed approach. Experimental results demonstrate that the proposed approach is both efficient and effective in traffic scene compared with the state-of-the-art.
Visual Saliency Based on Scale-Space Analysis in the Frequency Domain
May 06, 2016



We address the issue of visual saliency from three perspectives. First, we consider saliency detection as a frequency domain analysis problem. Second, we achieve this by employing the concept of {\it non-saliency}. Third, we simultaneously consider the detection of salient regions of different size. The paper proposes a new bottom-up paradigm for detecting visual saliency, characterized by a scale-space analysis of the amplitude spectrum of natural images. We show that the convolution of the {\it image amplitude spectrum} with a low-pass Gaussian kernel of an appropriate scale is equivalent to such an image saliency detector. The saliency map is obtained by reconstructing the 2-D signal using the original phase and the amplitude spectrum, filtered at a scale selected by minimizing saliency map entropy. A Hypercomplex Fourier Transform performs the analysis in the frequency domain. Using available databases, we demonstrate experimentally that the proposed model can predict human fixation data. We also introduce a new image database and use it to show that the saliency detector can highlight both small and large salient regions, as well as inhibit repeated distractors in cluttered images. In addition, we show that it is able to predict salient regions on which people focus their attention.