 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSam-Guided Enhanced Fine-Grained Encoding with Mixed Semantic Learning for Medical Image Captioning
Nov 02, 2023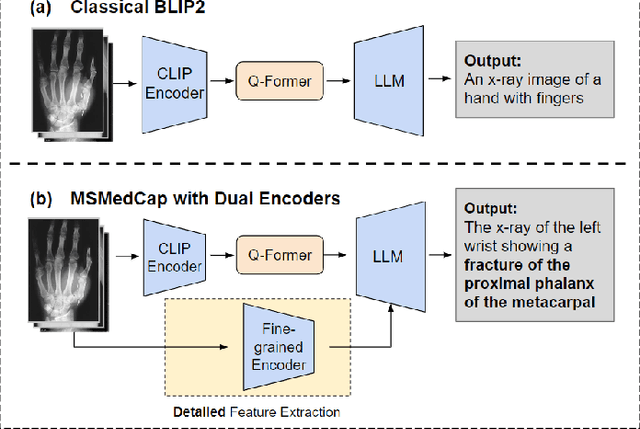
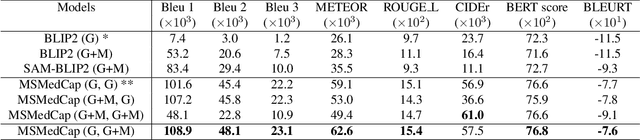
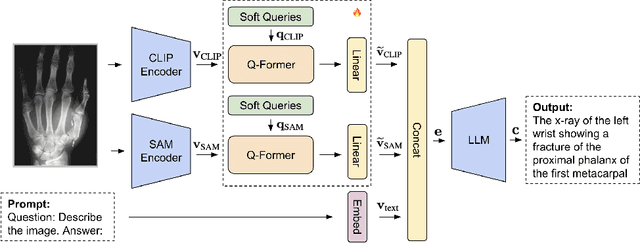
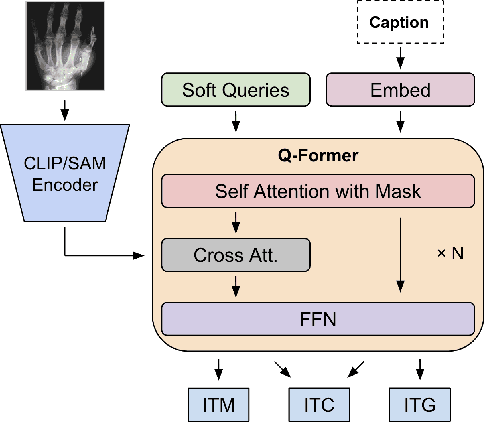
With the development of multimodality and large language models, the deep learning-based technique for medical image captioning holds the potential to offer valuable diagnostic recommendations. However, current generic text and image pre-trained models do not yield satisfactory results when it comes to describing intricate details within medical images. In this paper, we present a novel medical image captioning method guided by the segment anything model (SAM) to enable enhanced encoding with both general and detailed feature extraction. In addition, our approach employs a distinctive pre-training strategy with mixed semantic learning to simultaneously capture both the overall information and finer details within medical images. We demonstrate the effectiveness of this approach, as it outperforms the pre-trained BLIP2 model on various evaluation metrics for generating descriptions of medical images.
Blind Inpainting with Object-aware Discrimination for Artificial Marker Removal
Mar 27, 2023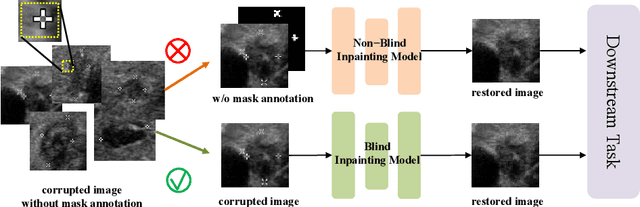



Medical images often contain artificial markers added by doctors, which can negatively affect the accuracy of AI-based diagnosis. To address this issue and recover the missing visual contents, inpainting techniques are highly needed. However, existing inpainting methods require manual mask input, limiting their application scenarios. In this paper, we introduce a novel blind inpainting method that automatically completes visual contents without specifying masks for target areas in an image. Our proposed model includes a mask-free reconstruction network and an object-aware discriminator. The reconstruction network consists of two branches that predict the corrupted regions with artificial markers and simultaneously recover the missing visual contents. The object-aware discriminator relies on the powerful recognition capabilities of the dense object detector to ensure that the markers of reconstructed images cannot be detected in any local regions. As a result, the reconstructed image can be close to the clean one as much as possible. Our proposed method is evaluated on different medical image datasets, covering multiple imaging modalities such as ultrasound (US), magnetic resonance imaging (MRI), and electron microscopy (EM), demonstrating that our method is effective and robust against various unknown missing region patterns.