 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIFT-Graph: Benchmarking Multimodal Defense Against Image Adversarial Attacks With Robust Feature Graph
Nov 11, 2025Adversarial attacks expose a fundamental vulnerability in modern deep vision models by exploiting their dependence on dense, pixel-level representations that are highly sensitive to imperceptible perturbations. Traditional defense strategies typically operate within this fragile pixel domain, lacking mechanisms to incorporate inherently robust visual features. In this work, we introduce SIFT-Graph, a multimodal defense framework that enhances the robustness of traditional vision models by aggregating structurally meaningful features extracted from raw images using both handcrafted and learned modalities. Specifically, we integrate Scale-Invariant Feature Transform keypoints with a Graph Attention Network to capture scale and rotation invariant local structures that are resilient to perturbations. These robust feature embeddings are then fused with traditional vision model, such as Vision Transformer and Convolutional Neural Network, to form a unified, structure-aware and perturbation defensive model. Preliminary results demonstrate that our method effectively improves the visual model robustness against gradient-based white box adversarial attacks, while incurring only a marginal drop in clean accuracy.
Sam-Guided Enhanced Fine-Grained Encoding with Mixed Semantic Learning for Medical Image Captioning
Nov 02, 2023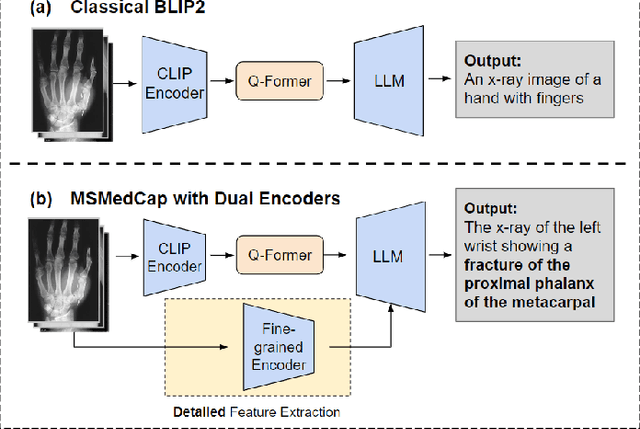
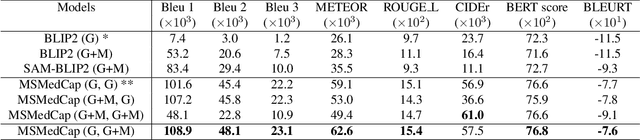
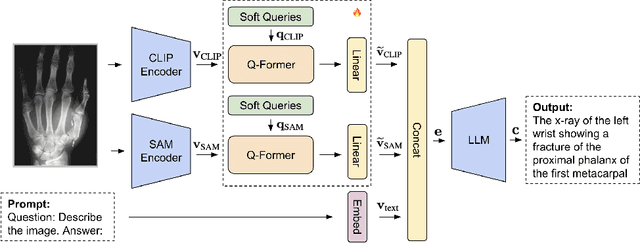
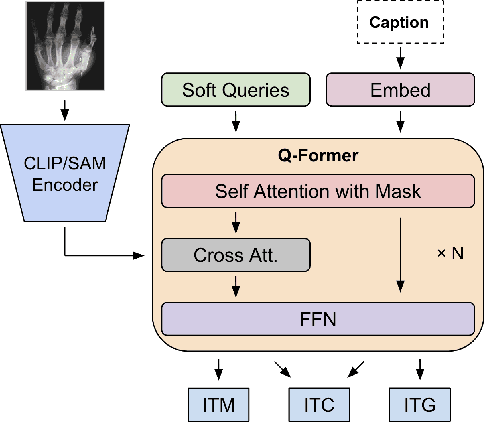
With the development of multimodality and large language models, the deep learning-based technique for medical image captioning holds the potential to offer valuable diagnostic recommendations. However, current generic text and image pre-trained models do not yield satisfactory results when it comes to describing intricate details within medical images. In this paper, we present a novel medical image captioning method guided by the segment anything model (SAM) to enable enhanced encoding with both general and detailed feature extraction. In addition, our approach employs a distinctive pre-training strategy with mixed semantic learning to simultaneously capture both the overall information and finer details within medical images. We demonstrate the effectiveness of this approach, as it outperforms the pre-trained BLIP2 model on various evaluation metrics for generating descriptions of medical images.