 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Domain Adaptation Ability for Chinese Spelling Check Models
Paper and Code

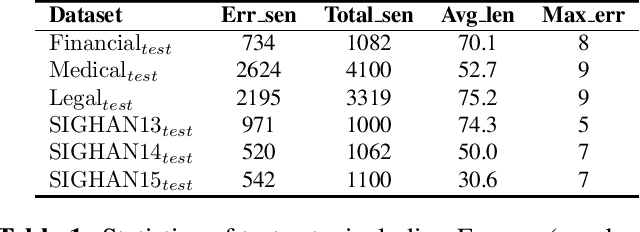
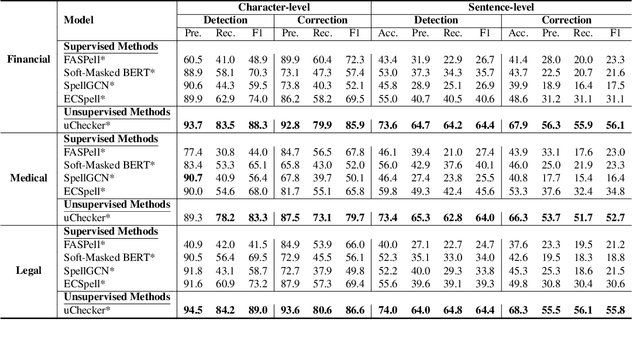
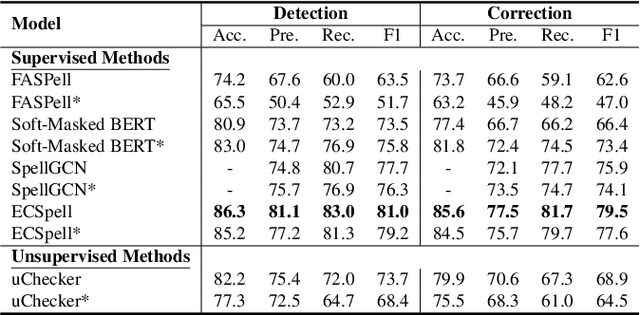
Chinese Spelling Check (CSC) is a meaningful task in the area of Natural Language Processing (NLP) which aims at detecting spelling errors in Chinese texts and then correcting these errors. However, CSC models are based on pretrained language models, which are trained on a general corpus. Consequently, their performance may drop when confronted with downstream tasks involving domain-specific terms. In this paper, we conduct a thorough evaluation about the domain adaption ability of various typical CSC models by building three new datasets encompassing rich domain-specific terms from the financial, medical, and legal domains. Then we conduct empirical investigations in the corresponding domain-specific test datasets to ascertain the cross-domain adaptation ability of several typical CSC models. We also test the performance of the popular large language model ChatGPT. As shown in our experiments, the performances of the CSC models drop significantly in the new domains.