 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual LLMs are Better Cross-lingual In-context Learners with Alignment
Paper and Code

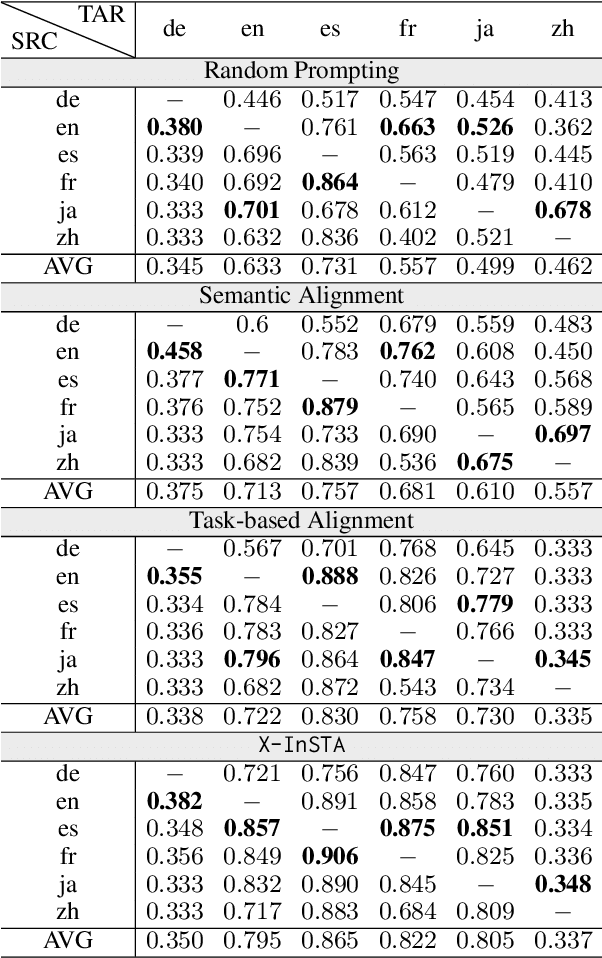


In-context learning (ICL) unfolds as large language models become capable of inferring test labels conditioned on a few labeled samples without any gradient update. ICL-enabled large language models provide a promising step forward toward bypassing recurrent annotation costs in a low-resource setting. Yet, only a handful of past studies have explored ICL in a cross-lingual setting, in which the need for transferring label-knowledge from a high-resource language to a low-resource one is immensely crucial. To bridge the gap, we provide the first in-depth analysis of ICL for cross-lingual text classification. We find that the prevalent mode of selecting random input-label pairs to construct the prompt-context is severely limited in the case of cross-lingual ICL, primarily due to the lack of alignment in the input as well as the output spaces. To mitigate this, we propose a novel prompt construction strategy -- Cross-lingual In-context Source-Target Alignment (X-InSTA). With an injected coherence in the semantics of the input examples and a task-based alignment across the source and target languages, X-InSTA is able to outperform random prompt selection by a large margin across three different tasks using 44 different cross-lingual pairs.