 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effect of Instruction Tuning Loss on Generalization
Jul 10, 2025Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been given to optimizing the loss function used. A fundamental, yet often overlooked, question is whether the conventional auto-regressive objective - where loss is computed only on response tokens, excluding prompt tokens - is truly optimal for instruction tuning. In this work, we systematically investigate the impact of differentially weighting prompt and response tokens in instruction tuning loss, and propose Weighted Instruction Tuning (WIT) as a better alternative to conventional instruction tuning. Through extensive experiments on five language models of different families and scale, three finetuning datasets of different sizes, and five diverse evaluation benchmarks, we show that the standard instruction tuning loss often yields suboptimal performance and limited robustness to input prompt variations. We find that a low-to-moderate weight for prompt tokens coupled with a moderate-to-high weight for response tokens yields the best-performing models across settings and also serve as better starting points for the subsequent preference alignment training. These findings highlight the need to reconsider instruction tuning loss and offer actionable insights for developing more robust and generalizable models. Our code is open-sourced at https://github.com/kowndinya-renduchintala/WIT.
POSIX: A Prompt Sensitivity Index For Large Language Models
Oct 03, 2024



Despite their remarkable capabilities, Large Language Models (LLMs) are found to be surprisingly sensitive to minor variations in prompts, often generating significantly divergent outputs in response to minor variations in the prompts, such as spelling errors, alteration of wording or the prompt template. However, while assessing the quality of an LLM, the focus often tends to be solely on its performance on downstream tasks, while very little to no attention is paid to prompt sensitivity. To fill this gap, we propose POSIX - a novel PrOmpt Sensitivity IndeX as a reliable measure of prompt sensitivity, thereby offering a more comprehensive evaluation of LLM performance. The key idea behind POSIX is to capture the relative change in loglikelihood of a given response upon replacing the corresponding prompt with a different intent-preserving prompt. We provide thorough empirical evidence demonstrating the efficacy of POSIX in capturing prompt sensitivity and subsequently use it to measure and thereby compare prompt sensitivity of various open-source LLMs. We find that merely increasing the parameter count or instruction tuning does not necessarily reduce prompt sensitivity whereas adding some few-shot exemplars, even just one, almost always leads to significant decrease in prompt sensitivity. We also find that alterations to prompt template lead to the highest sensitivity in the case of MCQtype tasks, whereas paraphrasing results in the highest sensitivity in open-ended generation tasks. The code for reproducing our results is open-sourced at https://github.com/kowndinyarenduchintala/POSIX.
SMART: Submodular Data Mixture Strategy for Instruction Tuning
Mar 13, 2024


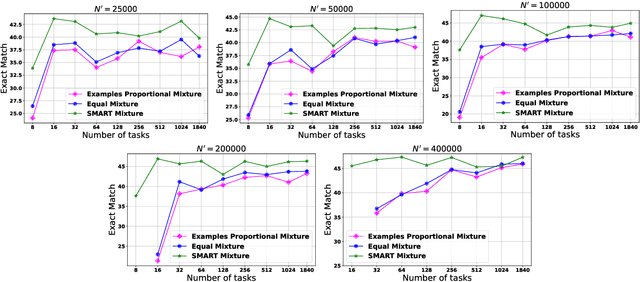
Instruction Tuning involves finetuning a language model on a collection of instruction-formatted datasets in order to enhance the generalizability of the model to unseen tasks. Studies have shown the importance of balancing different task proportions during finetuning, but finding the right balance remains challenging. Unfortunately, there's currently no systematic method beyond manual tuning or relying on practitioners' intuition. In this paper, we introduce SMART (Submodular data Mixture strAtegy for instRuction Tuning) - a novel data mixture strategy which makes use of a submodular function to assign importance scores to tasks which are then used to determine the mixture weights. Given a fine-tuning budget, SMART redistributes the budget among tasks and selects non-redundant samples from each task. Experimental results demonstrate that SMART significantly outperforms traditional methods such as examples proportional mixing and equal mixing. Furthermore, SMART facilitates the creation of data mixtures based on a few representative subsets of tasks alone and through task pruning analysis, we reveal that in a limited budget setting, allocating budget among a subset of representative tasks yields superior performance compared to distributing the budget among all tasks. The code for reproducing our results is open-sourced at https://github.com/kowndinya-renduchintala/SMART.
INGENIOUS: Using Informative Data Subsets for Efficient Pre-Training of Large Language Models
May 11, 2023
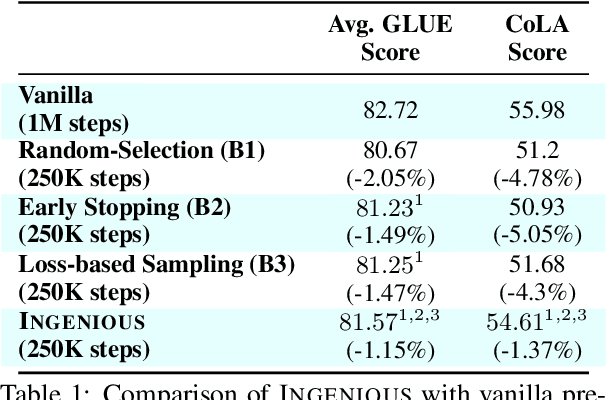

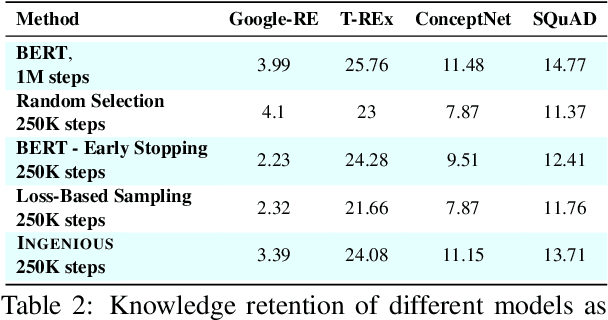
A salient characteristic of large pre-trained language models (PTLMs) is a remarkable improvement in their generalization capability and emergence of new capabilities with increasing model capacity and pre-training dataset size. Consequently, we are witnessing the development of enormous models pushing the state-of-the-art. It is, however, imperative to realize that this inevitably leads to prohibitively long training times, extortionate computing costs, and a detrimental environmental impact. Significant efforts are underway to make PTLM training more efficient through innovations in model architectures, training pipelines, and loss function design, with scant attention being paid to optimizing the utility of training data. The key question that we ask is whether it is possible to train PTLMs by employing only highly informative subsets of the training data while maintaining downstream performance? Building upon the recent progress in informative data subset selection, we show how we can employ submodular optimization to select highly representative subsets of the training corpora. Our results demonstrate that the proposed framework can be applied to efficiently train multiple PTLMs (BERT, BioBERT, GPT-2) using only a fraction of data while retaining up to $\sim99\%$ of the performance of the fully-trained models.