 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Agents 101: A Beginner's Guide to Critical Ingredients for Designing Effective Conversational Systems
Paper and Code
Jul 14, 2023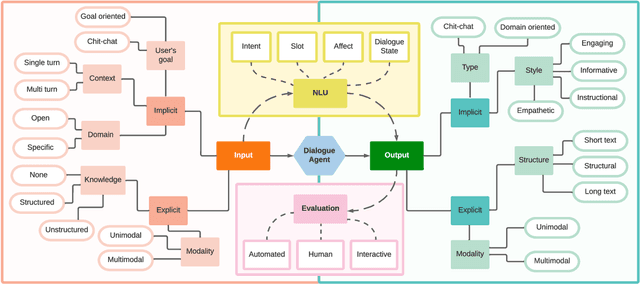
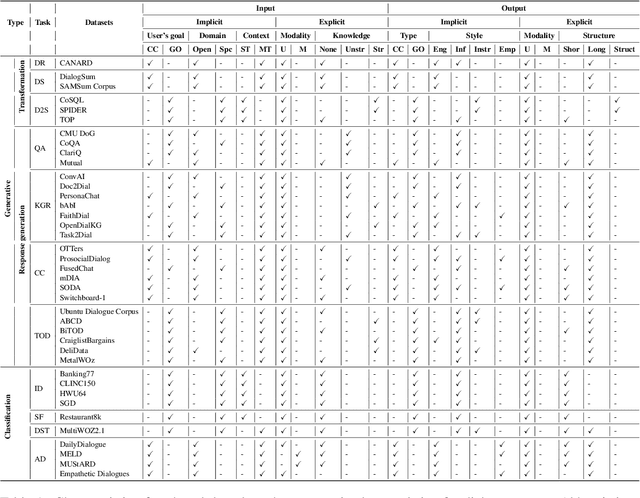
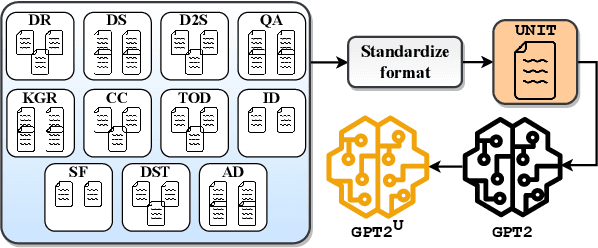

Sharing ideas through communication with peers is the primary mode of human interaction. Consequently, extensive research has been conducted in the area of conversational AI, leading to an increase in the availability and diversity of conversational tasks, datasets, and methods. However, with numerous tasks being explored simultaneously, the current landscape of conversational AI becomes fragmented. Therefore, initiating a well-thought-out model for a dialogue agent can pose significant challenges for a practitioner. Towards highlighting the critical ingredients needed for a practitioner to design a dialogue agent from scratch, the current study provides a comprehensive overview of the primary characteristics of a dialogue agent, the supporting tasks, their corresponding open-domain datasets, and the methods used to benchmark these datasets. We observe that different methods have been used to tackle distinct dialogue tasks. However, building separate models for each task is costly and does not leverage the correlation among the several tasks of a dialogue agent. As a result, recent trends suggest a shift towards building unified foundation models. To this end, we propose UNIT, a UNified dIalogue dataseT constructed from conversations of existing datasets for different dialogue tasks capturing the nuances for each of them. We also examine the evaluation strategies used to measure the performance of dialogue agents and highlight the scope for future research in the area of conversational AI.