 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Sarcasm Detection and Humor Classification in Code-mixed Conversations
Paper and Code

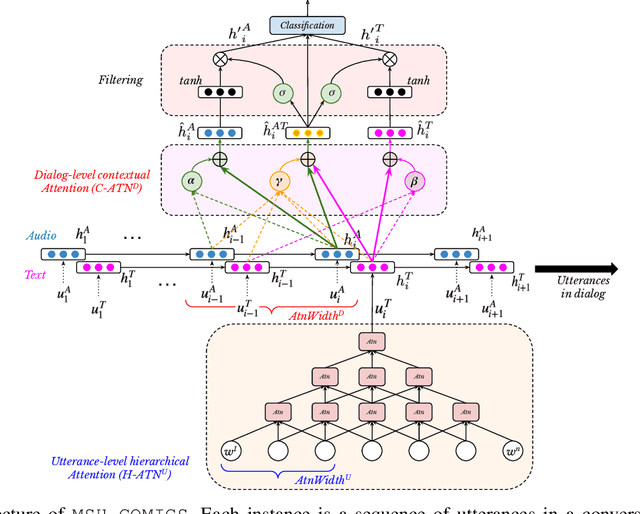


Sarcasm detection and humor classification are inherently subtle problems, primarily due to their dependence on the contextual and non-verbal information. Furthermore, existing studies in these two topics are usually constrained in non-English languages such as Hindi, due to the unavailability of qualitative annotated datasets. In this work, we make two major contributions considering the above limitations: (1) we develop a Hindi-English code-mixed dataset, MaSaC, for the multi-modal sarcasm detection and humor classification in conversational dialog, which to our knowledge is the first dataset of its kind; (2) we propose MSH-COMICS, a novel attention-rich neural architecture for the utterance classification. We learn efficient utterance representation utilizing a hierarchical attention mechanism that attends to a small portion of the input sentence at a time. Further, we incorporate dialog-level contextual attention mechanism to leverage the dialog history for the multi-modal classification. We perform extensive experiments for both the tasks by varying multi-modal inputs and various submodules of MSH-COMICS. We also conduct comparative analysis against existing approaches. We observe that MSH-COMICS attains superior performance over the existing models by > 1 F1-score point for the sarcasm detection and 10 F1-score points in humor classification. We diagnose our model and perform thorough analysis of the results to understand the superiority and pitfalls.