 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simulation Benchmark for Autonomous Racing with Large-Scale Human Data
Jul 24, 2024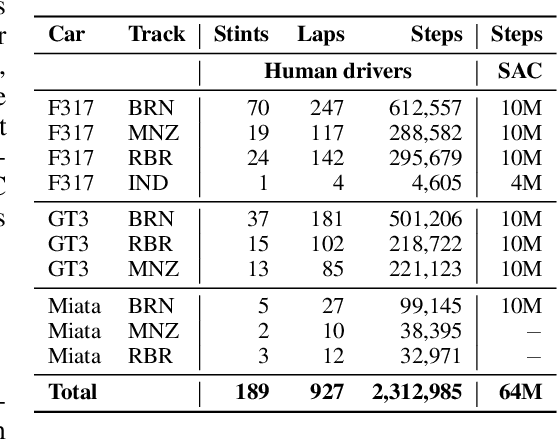

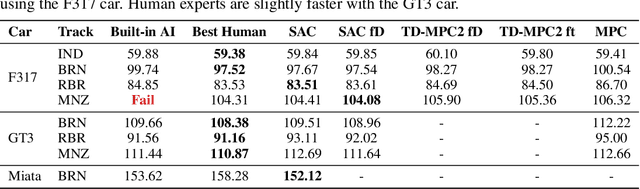
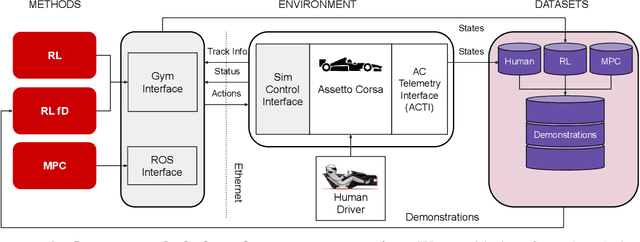
Despite the availability of international prize-money competitions, scaled vehicles, and simulation environments, research on autonomous racing and the control of sports cars operating close to the limit of handling has been limited by the high costs of vehicle acquisition and management, as well as the limited physics accuracy of open-source simulators. In this paper, we propose a racing simulation platform based on the simulator Assetto Corsa to test, validate, and benchmark autonomous driving algorithms, including reinforcement learning (RL) and classical Model Predictive Control (MPC), in realistic and challenging scenarios. Our contributions include the development of this simulation platform, several state-of-the-art algorithms tailored to the racing environment, and a comprehensive dataset collected from human drivers. Additionally, we evaluate algorithms in the offline RL setting. All the necessary code (including environment and benchmarks), working examples, datasets, and videos are publicly released and can be found at: https://assetto-corsa-gym.github.io
Acting upon Imagination: when to trust imagined trajectories in model based reinforcement learning
May 13, 2021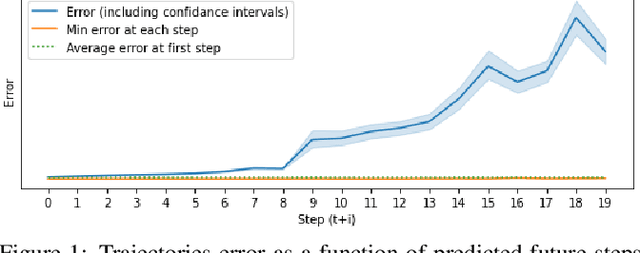
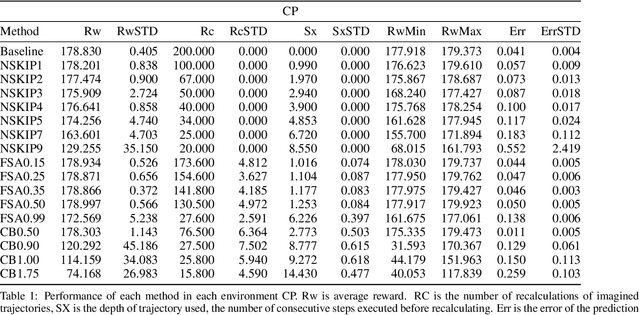

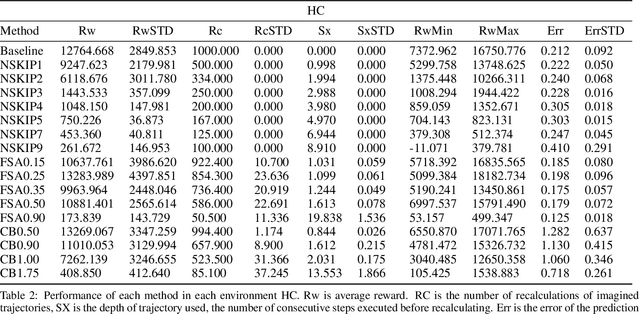
Model based reinforcement learning (MBRL) uses an imperfect model of the world to imagine trajectories of future states and plan the best actions to maximize a reward function. These trajectories are imperfect and MBRL attempts to overcome this by relying on model predictive control (MPC) to continuously re-imagine trajectories from scratch. Such re-generation of imagined trajectories carries the major computational cost and increasing complexity in tasks with longer receding horizon. This paper aims to investigate how far in the future the imagined trajectories can be relied upon while still maintaining acceptable reward. Firstly, an error analysis is presented for systematic skipping recalculations for varying number of consecutive steps.% in several challenging benchmark control tasks. Secondly, we propose two methods offering when to trust and act upon imagined trajectories, looking at recent errors with respect to expectations, or comparing the confidence in an action imagined against its execution. Thirdly, we evaluate the effects of acting upon imagination while training the model of the world. Results show that acting upon imagination can reduce calculations by at least 20% and up to 80%, depending on the environment, while retaining acceptable reward.
Formula RL: Deep Reinforcement Learning for Autonomous Racing using Telemetry Data
Apr 22, 2021

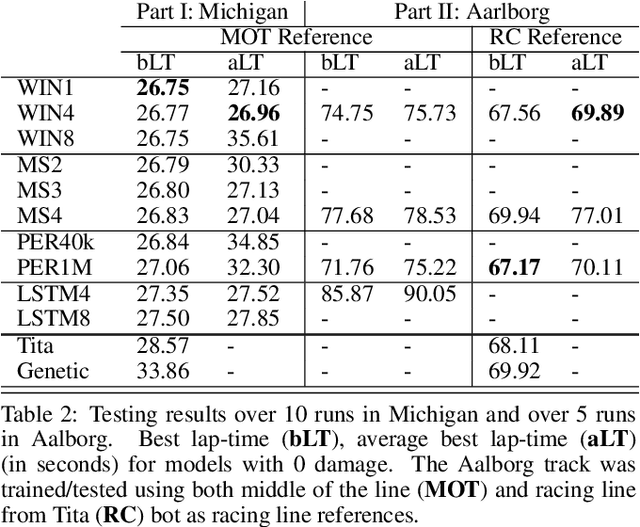
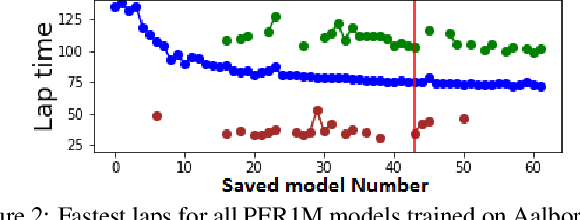
This paper explores the use of reinforcement learning (RL) models for autonomous racing. In contrast to passenger cars, where safety is the top priority, a racing car aims to minimize the lap-time. We frame the problem as a reinforcement learning task with a multidimensional input consisting of the vehicle telemetry, and a continuous action space. To find out which RL methods better solve the problem and whether the obtained models generalize to driving on unknown tracks, we put 10 variants of deep deterministic policy gradient (DDPG) to race in two experiments: i)~studying how RL methods learn to drive a racing car and ii)~studying how the learning scenario influences the capability of the models to generalize. Our studies show that models trained with RL are not only able to drive faster than the baseline open source handcrafted bots but also generalize to unknown tracks.