 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing upon Imagination: when to trust imagined trajectories in model based reinforcement learning
Paper and Code
May 13, 2021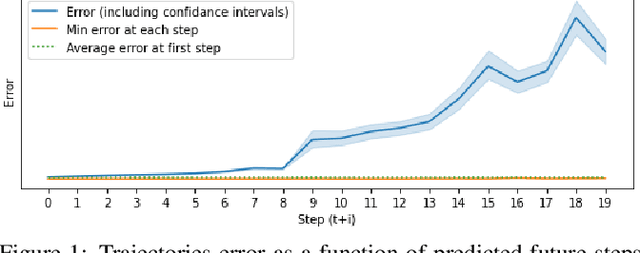
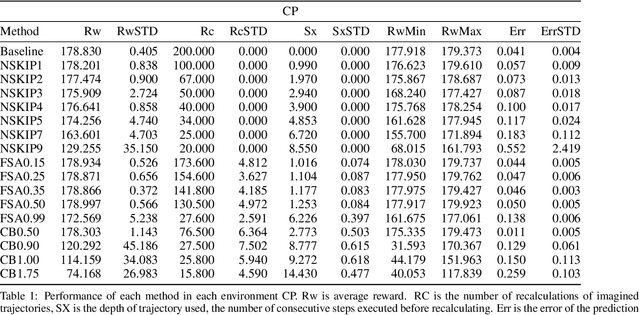

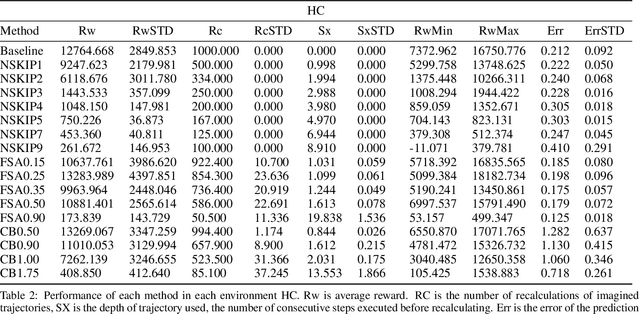
Model based reinforcement learning (MBRL) uses an imperfect model of the world to imagine trajectories of future states and plan the best actions to maximize a reward function. These trajectories are imperfect and MBRL attempts to overcome this by relying on model predictive control (MPC) to continuously re-imagine trajectories from scratch. Such re-generation of imagined trajectories carries the major computational cost and increasing complexity in tasks with longer receding horizon. This paper aims to investigate how far in the future the imagined trajectories can be relied upon while still maintaining acceptable reward. Firstly, an error analysis is presented for systematic skipping recalculations for varying number of consecutive steps.% in several challenging benchmark control tasks. Secondly, we propose two methods offering when to trust and act upon imagined trajectories, looking at recent errors with respect to expectations, or comparing the confidence in an action imagined against its execution. Thirdly, we evaluate the effects of acting upon imagination while training the model of the world. Results show that acting upon imagination can reduce calculations by at least 20% and up to 80%, depending on the environment, while retaining acceptable reward.