 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Convex Formulation of Robust One-hidden-layer Neural Network Training
Paper and Code
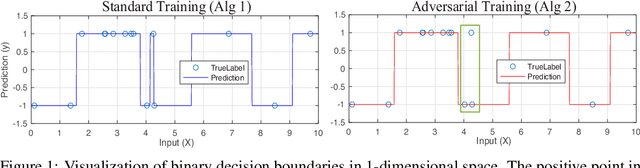
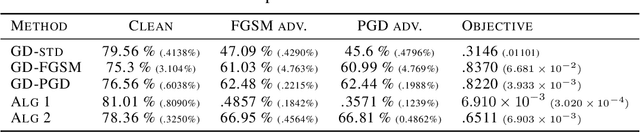
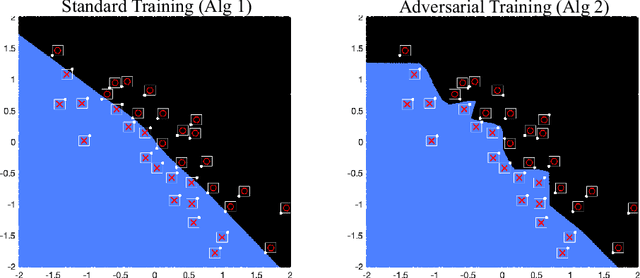
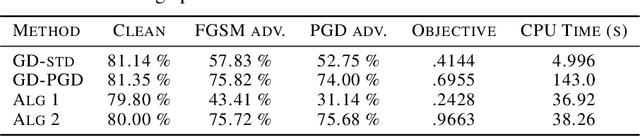
Recent work has shown that the training of a one-hidden-layer, scalar-output fully-connected ReLU neural network can be reformulated as a finite-dimensional convex program. Unfortunately, the scale of such a convex program grows exponentially in data size. In this work, we prove that a stochastic procedure with a linear complexity well approximates the exact formulation. Moreover, we derive a convex optimization approach to efficiently solve the "adversarial training" problem, which trains neural networks that are robust to adversarial input perturbations. Our method can be applied to binary classification and regression, and provides an alternative to the current adversarial training methods, such as Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD). We demonstrate in experiments that the proposed method achieves a noticeably better adversarial robustness and performance than the existing methods.