 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierDAMap: Towards Universal Domain Adaptive BEV Mapping via Hierarchical Perspective Priors
Mar 10, 2025The exploration of Bird's-Eye View (BEV) mapping technology has driven significant innovation in visual perception technology for autonomous driving. BEV mapping models need to be applied to the unlabeled real world, making the study of unsupervised domain adaptation models an essential path. However, research on unsupervised domain adaptation for BEV mapping remains limited and cannot perfectly accommodate all BEV mapping tasks. To address this gap, this paper proposes HierDAMap, a universal and holistic BEV domain adaptation framework with hierarchical perspective priors. Unlike existing research that solely focuses on image-level learning using prior knowledge, this paper explores the guiding role of perspective prior knowledge across three distinct levels: global, sparse, and instance levels. With these priors, HierDA consists of three essential components, including Semantic-Guided Pseudo Supervision (SGPS), Dynamic-Aware Coherence Learning (DACL), and Cross-Domain Frustum Mixing (CDFM). SGPS constrains the cross-domain consistency of perspective feature distribution through pseudo labels generated by vision foundation models in 2D space. To mitigate feature distribution discrepancies caused by spatial variations, DACL employs uncertainty-aware predicted depth as an intermediary to derive dynamic BEV labels from perspective pseudo-labels, thereby constraining the coarse BEV features derived from corresponding perspective features. CDFM, on the other hand, leverages perspective masks of view frustum to mix multi-view perspective images from both domains, which guides cross-domain view transformation and encoding learning through mixed BEV labels. The proposed method is verified on multiple BEV mapping tasks, such as BEV semantic segmentation, high-definition semantic, and vectorized mapping. The source code will be made publicly available at https://github.com/lynn-yu/HierDAMap.
UFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Jan 12, 2021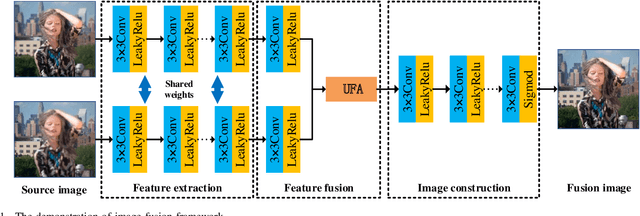
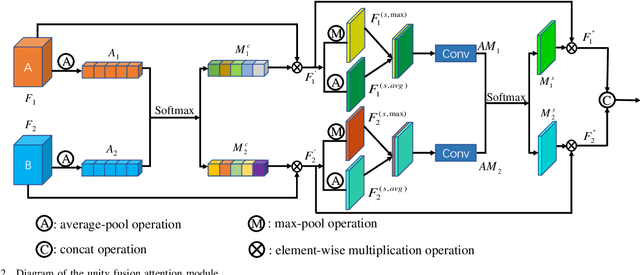


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.