 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Paper and Code
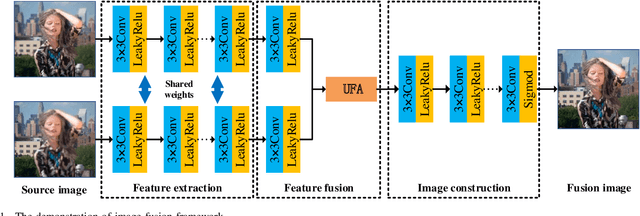
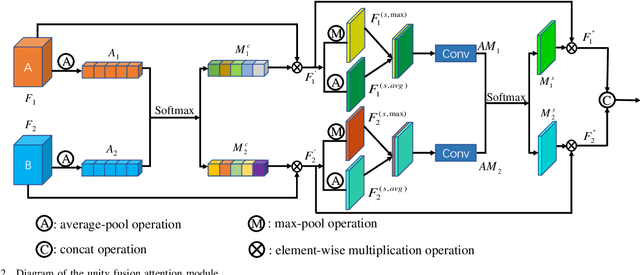


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.