 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP-BFGS attack: An adversarial attack based on the Hessian with limited pixels
Oct 26, 2022



Deep neural networks are vulnerable to adversarial attacks. Most white-box attacks are based on the gradient of models to the input. Since the computation and memory budget, adversarial attacks based on the Hessian information are not paid enough attention. In this work, we study the attack performance and computation cost of the attack method based on the Hessian with a limited perturbation pixel number. Specifically, we propose the Limited Pixel BFGS (LP-BFGS) attack method by incorporating the BFGS algorithm. Some pixels are selected as perturbation pixels by the Integrated Gradient algorithm, which are regarded as optimization variables of the LP-BFGS attack. Experimental results across different networks and datasets with various perturbation pixel numbers demonstrate our approach has a comparable attack with an acceptable computation compared with existing solutions.
Exploring Adversarial Examples and Adversarial Robustness of Convolutional Neural Networks by Mutual Information
Jul 12, 2022
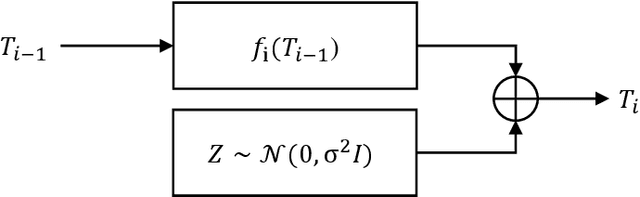
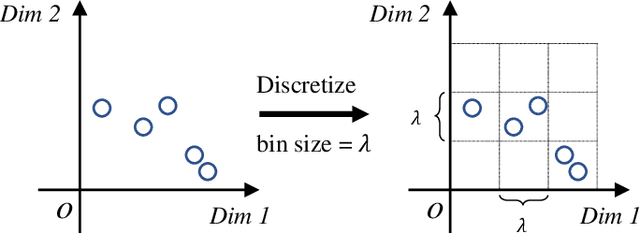
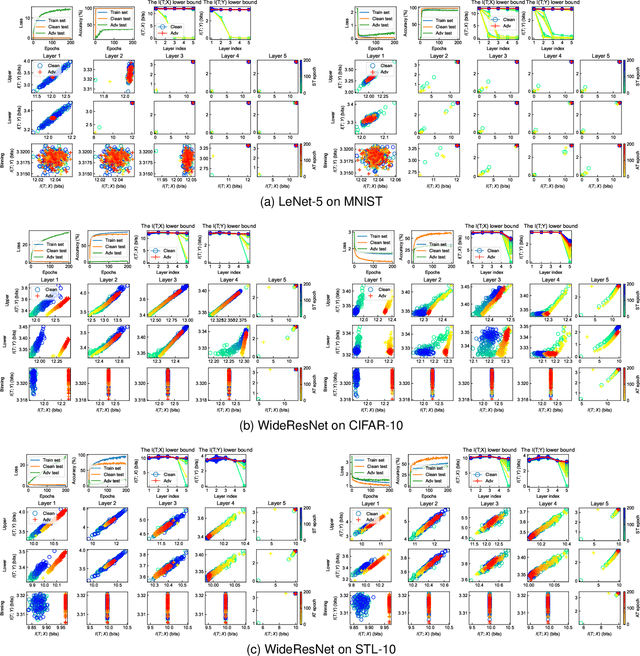
A counter-intuitive property of convolutional neural networks (CNNs) is their inherent susceptibility to adversarial examples, which severely hinders the application of CNNs in security-critical fields. Adversarial examples are similar to original examples but contain malicious perturbations. Adversarial training is a simple and effective training method to improve the robustness of CNNs to adversarial examples. The mechanisms behind adversarial examples and adversarial training are worth exploring. Therefore, this work investigates similarities and differences between two types of CNNs (both normal and robust ones) in information extraction by observing the trends towards the mutual information. We show that 1) the amount of mutual information that CNNs extract from original and adversarial examples is almost similar, whether CNNs are in normal training or adversarial training; the reason why adversarial examples mislead CNNs may be that they contain more texture-based information about other categories; 2) compared with normal training, adversarial training is more difficult and the amount of information extracted by the robust CNNs is less; 3) the CNNs trained with different methods have different preferences for certain types of information; normally trained CNNs tend to extract texture-based information from the inputs, while adversarially trained models prefer to shape-based information. Furthermore, we also analyze the mutual information estimators used in this work, kernel-density-estimation and binning methods, and find that these estimators outline the geometric properties of the middle layer's output to a certain extent.
UFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Jan 12, 2021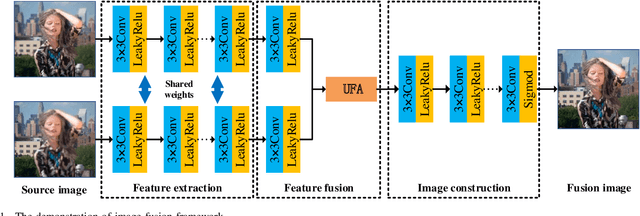
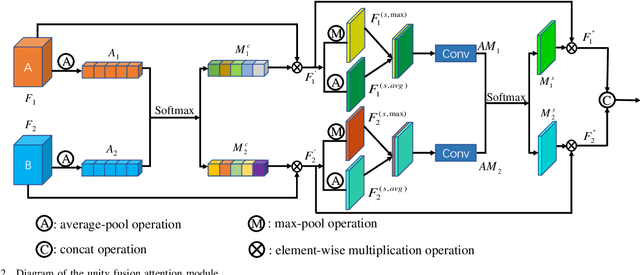


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.