 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX Modality Assisting RGBT Object Tracking
Dec 27, 2023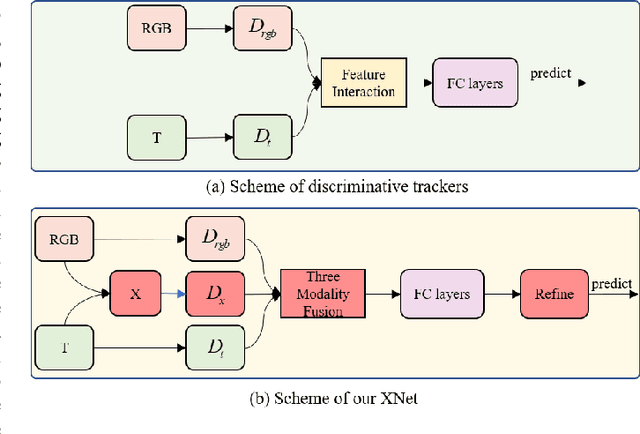
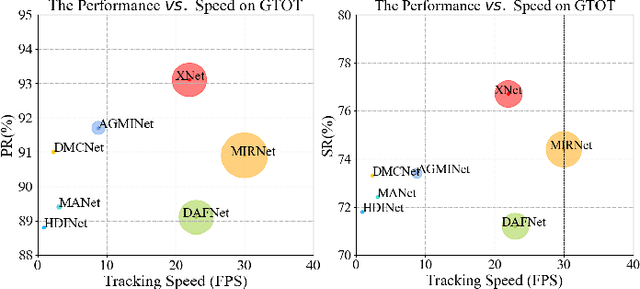
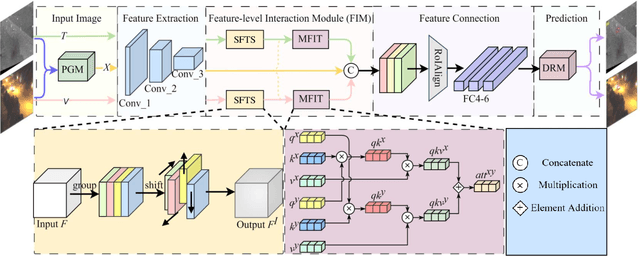
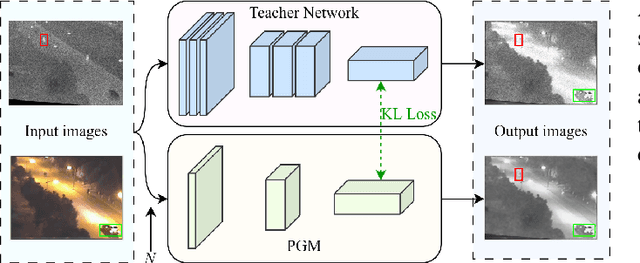
Learning robust multi-modal feature representations is critical for boosting tracking performance. To this end, we propose a novel X Modality Assisting Network (X-Net) to shed light on the impact of the fusion paradigm by decoupling the visual object tracking into three distinct levels, facilitating subsequent processing. Firstly, to tackle the feature learning hurdles stemming from significant differences between RGB and thermal modalities, a plug-and-play pixel-level generation module (PGM) is proposed based on self-knowledge distillation learning, which effectively generates X modality to bridge the gap between the dual patterns while reducing noise interference. Subsequently, to further achieve the optimal sample feature representation and facilitate cross-modal interactions, we propose a feature-level interaction module (FIM) that incorporates a mixed feature interaction transformer and a spatial-dimensional feature translation strategy. Ultimately, aiming at random drifting due to missing instance features, we propose a flexible online optimized strategy called the decision-level refinement module (DRM), which contains optical flow and refinement mechanisms. Experiments are conducted on three benchmarks to verify that the proposed X-Net outperforms state-of-the-art trackers.
UFA-FUSE: A novel deep supervised and hybrid model for multi-focus image fusion
Jan 12, 2021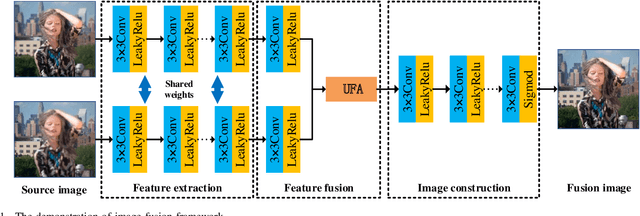
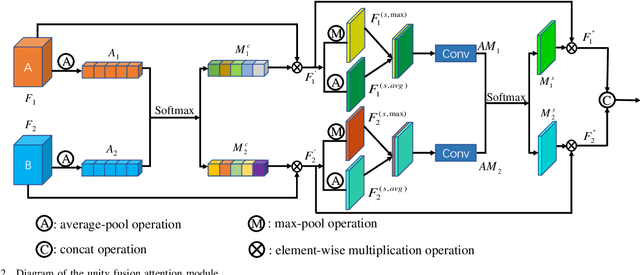


Traditional and deep learning-based fusion methods generated the intermediate decision map to obtain the fusion image through a series of post-processing procedures. However, the fusion results generated by these methods are easy to lose some source image details or results in artifacts. Inspired by the image reconstruction techniques based on deep learning, we propose a multi-focus image fusion network framework without any post-processing to solve these problems in the end-to-end and supervised learning way. To sufficiently train the fusion model, we have generated a large-scale multi-focus image dataset with ground-truth fusion images. What's more, to obtain a more informative fusion image, we further designed a novel fusion strategy based on unity fusion attention, which is composed of a channel attention module and a spatial attention module. Specifically, the proposed fusion approach mainly comprises three key components: feature extraction, feature fusion and image reconstruction. We firstly utilize seven convolutional blocks to extract the image features from source images. Then, the extracted convolutional features are fused by the proposed fusion strategy in the feature fusion layer. Finally, the fused image features are reconstructed by four convolutional blocks. Experimental results demonstrate that the proposed approach for multi-focus image fusion achieves remarkable fusion performance compared to 19 state-of-the-art fusion methods.