 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Adversarial Examples and Adversarial Robustness of Convolutional Neural Networks by Mutual Information
Paper and Code

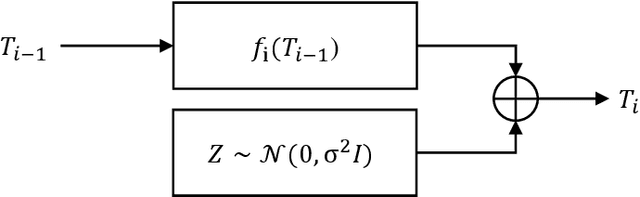
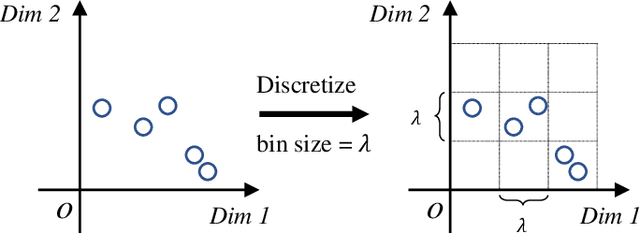
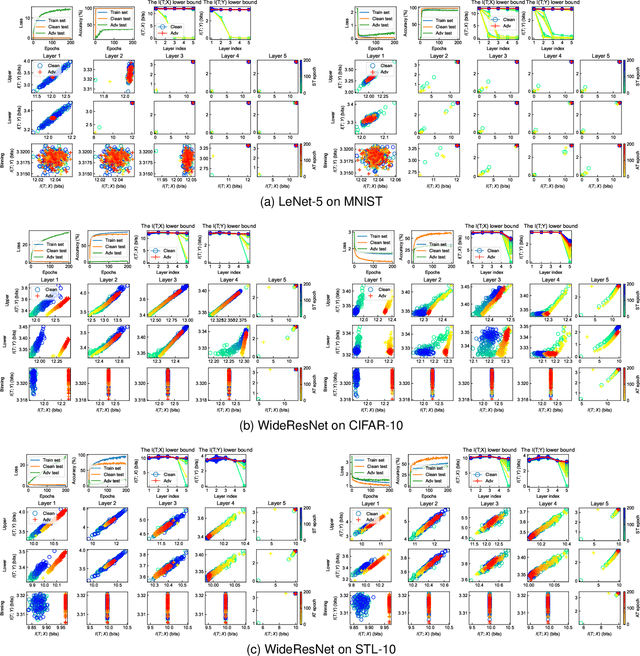
A counter-intuitive property of convolutional neural networks (CNNs) is their inherent susceptibility to adversarial examples, which severely hinders the application of CNNs in security-critical fields. Adversarial examples are similar to original examples but contain malicious perturbations. Adversarial training is a simple and effective training method to improve the robustness of CNNs to adversarial examples. The mechanisms behind adversarial examples and adversarial training are worth exploring. Therefore, this work investigates similarities and differences between two types of CNNs (both normal and robust ones) in information extraction by observing the trends towards the mutual information. We show that 1) the amount of mutual information that CNNs extract from original and adversarial examples is almost similar, whether CNNs are in normal training or adversarial training; the reason why adversarial examples mislead CNNs may be that they contain more texture-based information about other categories; 2) compared with normal training, adversarial training is more difficult and the amount of information extracted by the robust CNNs is less; 3) the CNNs trained with different methods have different preferences for certain types of information; normally trained CNNs tend to extract texture-based information from the inputs, while adversarially trained models prefer to shape-based information. Furthermore, we also analyze the mutual information estimators used in this work, kernel-density-estimation and binning methods, and find that these estimators outline the geometric properties of the middle layer's output to a certain extent.