 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable Pre-training: A Survey on Model Architectures, Pretraining Objectives, and Downstream Tasks
Jan 27, 2022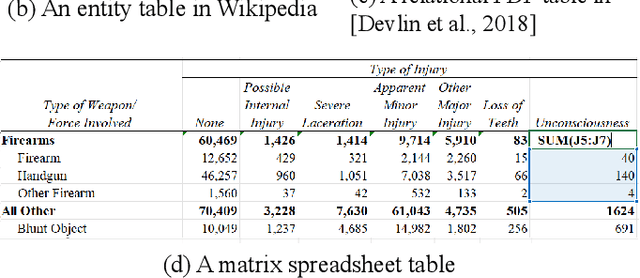


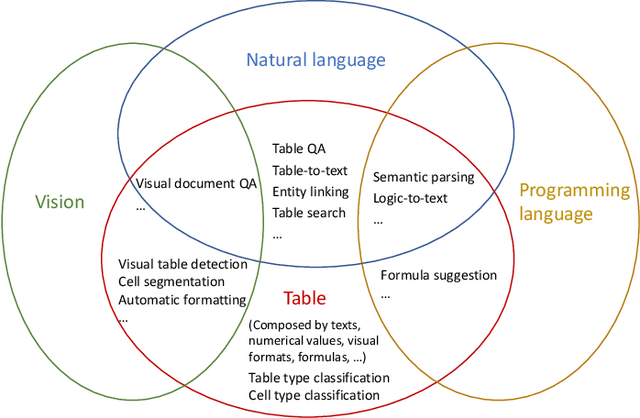
Since a vast number of tables can be easily collected from web pages, spreadsheets, PDFs, and various other document types, a flurry of table pre-training frameworks have been proposed following the success of text and images, and they have achieved new state-of-the-arts on various tasks such as table question answering, table type recognition, column relation classification, table search, formula prediction, etc. To fully use the supervision signals in unlabeled tables, a variety of pre-training objectives have been designed and evaluated, for example, denoising cell values, predicting numerical relationships, and implicitly executing SQLs. And to best leverage the characteristics of (semi-)structured tables, various tabular language models, particularly with specially-designed attention mechanisms, have been explored. Since tables usually appear and interact with free-form text, table pre-training usually takes the form of table-text joint pre-training, which attracts significant research interests from multiple domains. This survey aims to provide a comprehensive review of different model designs, pre-training objectives, and downstream tasks for table pre-training, and we further share our thoughts and vision on existing challenges and future opportunities.