 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Rule: Recurrent Partitioned Network for Dynamic Processes
Jun 01, 2021

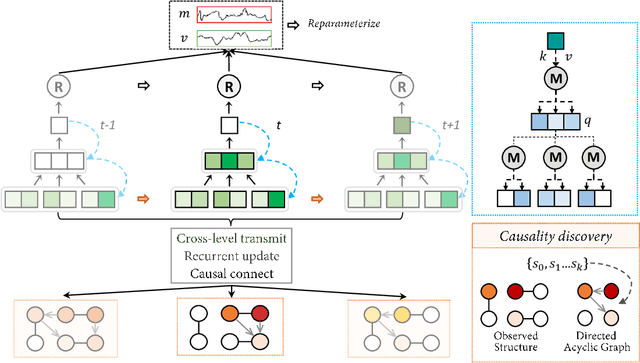
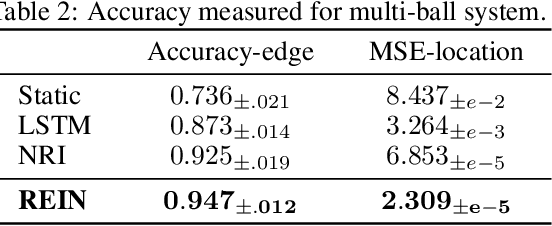
In general, many dynamic processes are involved with interacting variables, from physical systems to sociological analysis. The interplay of components in the system can give rise to confounding dynamic behavior. Many approaches model temporal sequences holistically ignoring the internal interaction which are impotent in capturing the protogenic actuation. Differently, our goal is to represent a system with a part-whole hierarchy and discover the implied dependencies among intra-system variables: inferring the interactions that possess causal effects on the sub-system behavior with REcurrent partItioned Network (REIN). The proposed architecture consists of (i) a perceptive module that extracts a hierarchical and temporally consistent representation of the observation at multiple levels, (ii) a deductive module for determining the relational connection between neurons at each level, and (iii) a statistical module that can predict the future by conditioning on the temporal distributional estimation. Our model is demonstrated to be effective in identifying the componential interactions with limited observation and stable in long-term future predictions experimented with diverse physical systems.
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 05, 2021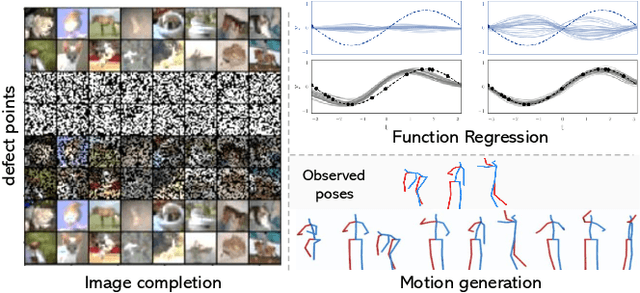
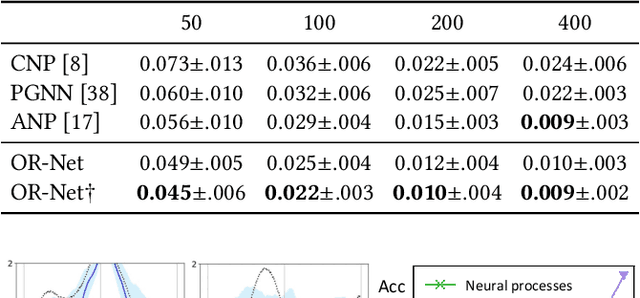
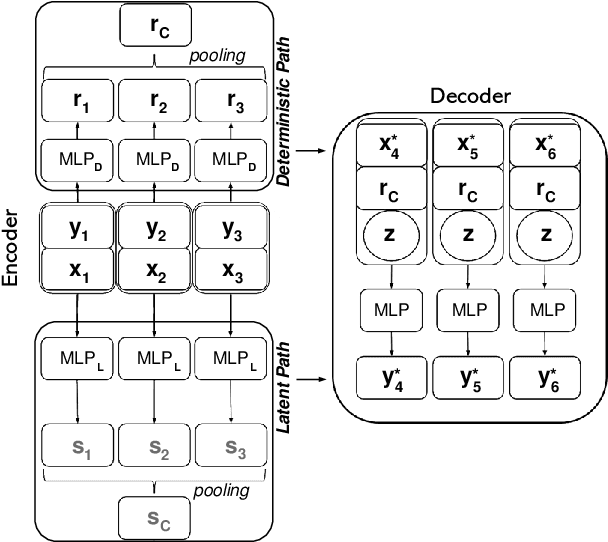

Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
Decoupled Spatial Temporal Graphs for Generic Visual Grounding
Mar 18, 2021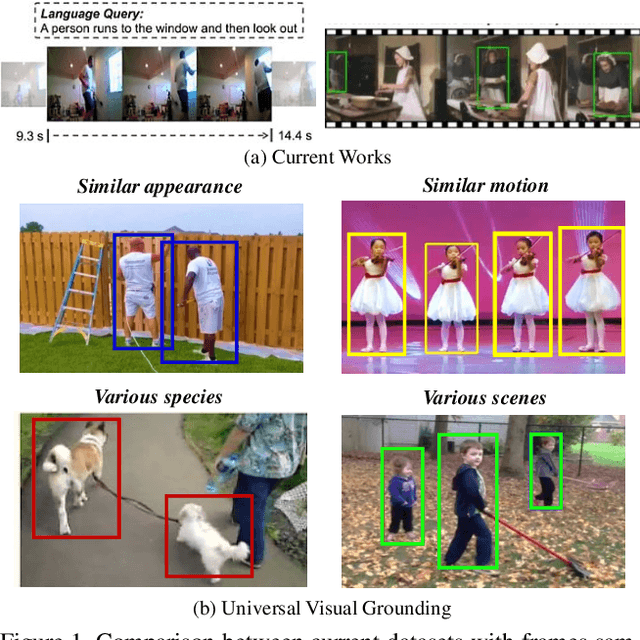

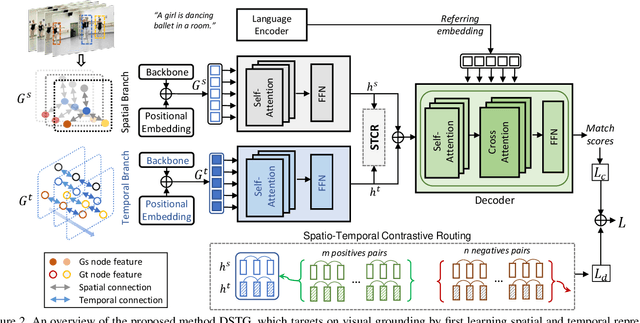

Visual grounding is a long-lasting problem in vision-language understanding due to its diversity and complexity. Current practices concentrate mostly on performing visual grounding in still images or well-trimmed video clips. This work, on the other hand, investigates into a more general setting, generic visual grounding, aiming to mine all the objects satisfying the given expression, which is more challenging yet practical in real-world scenarios. Importantly, grounding results are expected to accurately localize targets in both space and time. Whereas, it is tricky to make trade-offs between the appearance and motion features. In real scenarios, model tends to fail in distinguishing distractors with similar attributes. Motivated by these considerations, we propose a simple yet effective approach, named DSTG, which commits to 1) decomposing the spatial and temporal representations to collect all-sided cues for precise grounding; 2) enhancing the discriminativeness from distractors and the temporal consistency with a contrastive learning routing strategy. We further elaborate a new video dataset, GVG, that consists of challenging referring cases with far-ranging videos. Empirical experiments well demonstrate the superiority of DSTG over state-of-the-art on Charades-STA, ActivityNet-Caption and GVG datasets. Code and dataset will be made available.
Look, Cast and Mold: Learning 3D Shape Manifold from Single-view Synthetic Data
Mar 18, 2021

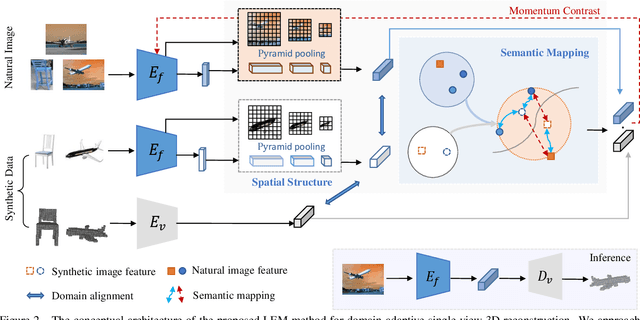
Inferring the stereo structure of objects in the real world is a challenging yet practical task. To equip deep models with this ability usually requires abundant 3D supervision which is hard to acquire. It is promising that we can simply benefit from synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gaps are nontrivial considering the variant texture, shape and context. To overcome these difficulties, we propose a Visio-Perceptual Adaptive Network for single-view 3D reconstruction, dubbed VPAN. To generalize the model towards a real scenario, we propose to fulfill several aspects: (1) Look: visually incorporate spatial structure from the single view to enhance the expressiveness of representation; (2) Cast: perceptually align the 2D image features to the 3D shape priors with cross-modal semantic contrastive mapping; (3) Mold: reconstruct stereo-shape of target by transforming embeddings into the desired manifold. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method in learning the 3D shape manifold from synthetic data via a single-view. The proposed method outperforms state-of-the-arts on Pix3D dataset with IoU 0.292 and CD 0.108, and reaches IoU 0.329 and CD 0.104 on Pascal 3D+.
Attract or Distract: Exploit the Margin of Open Set
Aug 10, 2019
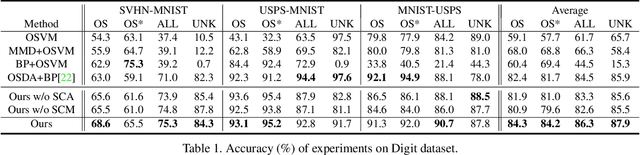
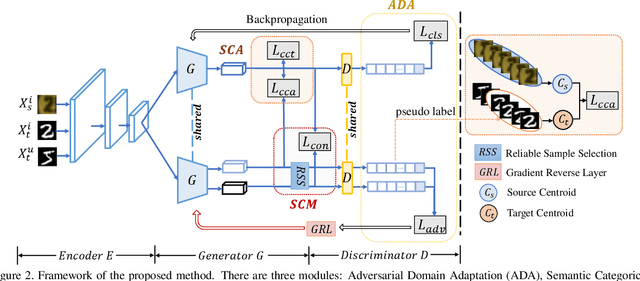

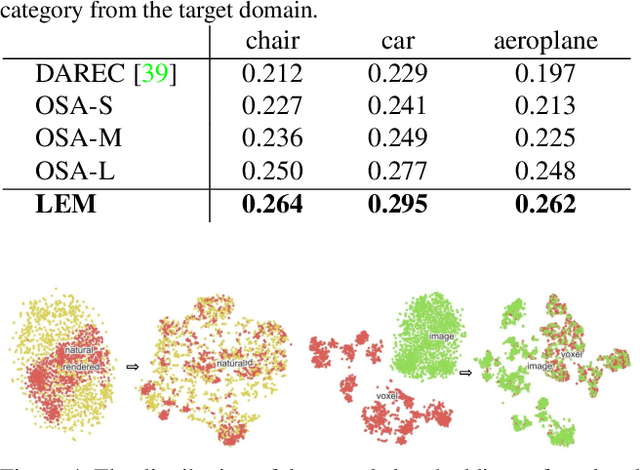
Open set domain adaptation aims to diminish the domain shift across domains, with partially shared classes. There exist unknown target samples out of the knowledge of source domain. Compared to the close set setting, how to separate the unknown (unshared) class from the known (shared) ones plays a key role. Whereas, previous methods did not emphasize the semantic structure of the open set data, which may introduce bias into the domain alignment and confuse the classifier around the decision boundary. In this paper, we exploit the semantic structure of open set data from two aspects: 1) Semantic Categorical Alignment, which aims to achieve good separability of target known classes by categorically aligning the centroid of target with the source. 2)Semantic Contrastive Mapping, which aims to push the unknown class away from the decision boundary. Empirically, we demonstrate that our method performs favourably against the state-of-the-art methods on representative benchmarks, e.g. Digit datasets and Office-31 datasets.
Cascaded Revision Network for Novel Object Captioning
Aug 06, 2019

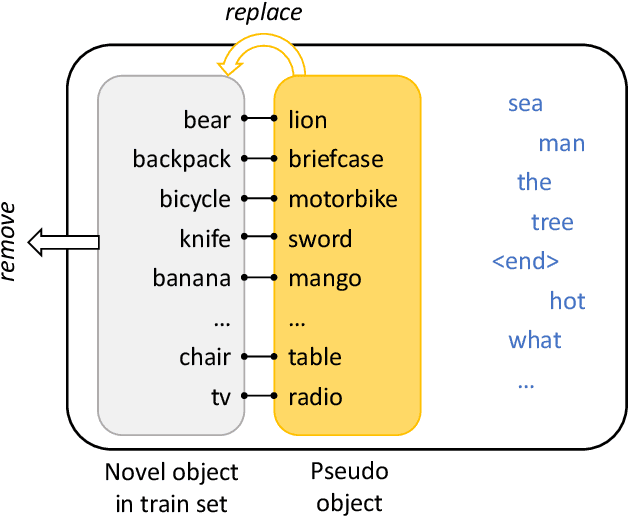

Image captioning, a challenging task where the machine automatically describes an image by sentences, has drawn significant attention in recent years. Despite the remarkable improvements of recent approaches, however, these methods are built upon a large set of training image-sentence pairs. The expensive labor efforts hence limit the captioning model to describe the wider world. In this paper, we present a novel network structure, Cascaded Revision Network, which aims at relieving the problem by equipping the model with out-of-domain knowledge. CRN first tries its best to describe an image using the existing vocabulary from in-domain knowledge. Due to the lack of out-of-domain knowledge, the caption may be inaccurate or include ambiguous words for the image with unknown (novel) objects. We propose to re-edit the primary captioning sentence by a series of cascaded operations. We introduce a perplexity predictor to find out which words are most likely to be inaccurate given the input image. Thereafter, we utilize external knowledge from a pre-trained object detection model and select more accurate words from detection results by the visual matching module. In the last step, we design a semantic matching module to ensure that the novel object is fit in the right position. By this novel cascaded captioning-revising mechanism, CRN can accurately describe images with unseen objects. We validate the proposed method with state-of-the-art performance on the held-out MSCOCO dataset as well as scale to ImageNet, demonstrating the effectiveness of this method.