 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Revision Network for Novel Object Captioning
Paper and Code


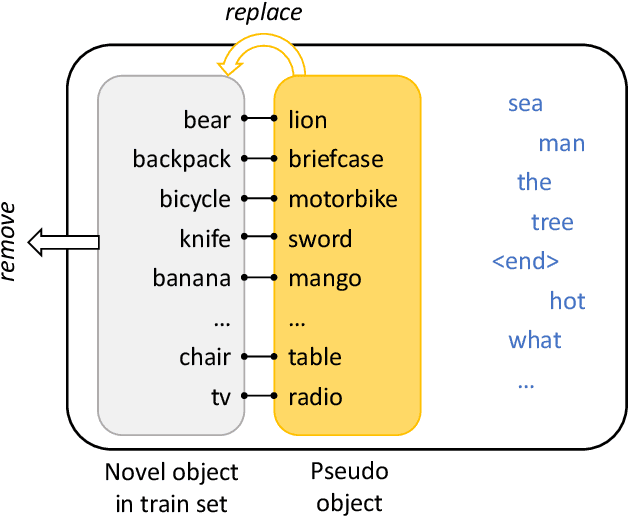

Image captioning, a challenging task where the machine automatically describes an image by sentences, has drawn significant attention in recent years. Despite the remarkable improvements of recent approaches, however, these methods are built upon a large set of training image-sentence pairs. The expensive labor efforts hence limit the captioning model to describe the wider world. In this paper, we present a novel network structure, Cascaded Revision Network, which aims at relieving the problem by equipping the model with out-of-domain knowledge. CRN first tries its best to describe an image using the existing vocabulary from in-domain knowledge. Due to the lack of out-of-domain knowledge, the caption may be inaccurate or include ambiguous words for the image with unknown (novel) objects. We propose to re-edit the primary captioning sentence by a series of cascaded operations. We introduce a perplexity predictor to find out which words are most likely to be inaccurate given the input image. Thereafter, we utilize external knowledge from a pre-trained object detection model and select more accurate words from detection results by the visual matching module. In the last step, we design a semantic matching module to ensure that the novel object is fit in the right position. By this novel cascaded captioning-revising mechanism, CRN can accurately describe images with unseen objects. We validate the proposed method with state-of-the-art performance on the held-out MSCOCO dataset as well as scale to ImageNet, demonstrating the effectiveness of this method.