 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook, Cast and Mold: Learning 3D Shape Manifold from Single-view Synthetic Data
Mar 18, 2021

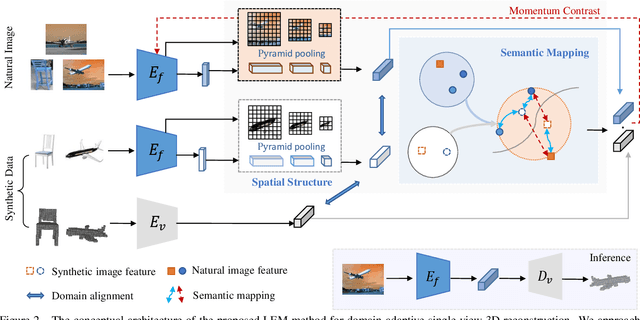
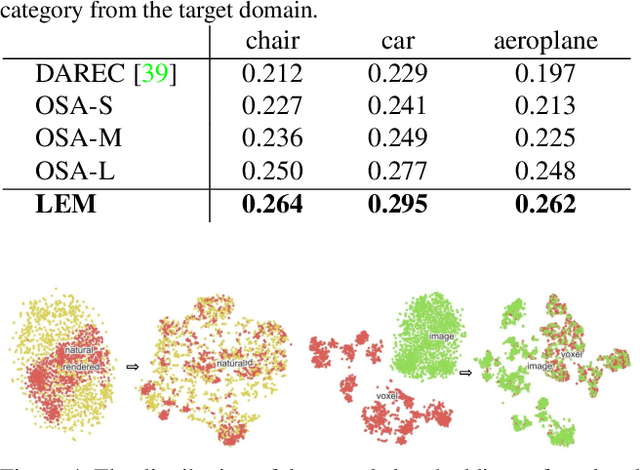
Inferring the stereo structure of objects in the real world is a challenging yet practical task. To equip deep models with this ability usually requires abundant 3D supervision which is hard to acquire. It is promising that we can simply benefit from synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gaps are nontrivial considering the variant texture, shape and context. To overcome these difficulties, we propose a Visio-Perceptual Adaptive Network for single-view 3D reconstruction, dubbed VPAN. To generalize the model towards a real scenario, we propose to fulfill several aspects: (1) Look: visually incorporate spatial structure from the single view to enhance the expressiveness of representation; (2) Cast: perceptually align the 2D image features to the 3D shape priors with cross-modal semantic contrastive mapping; (3) Mold: reconstruct stereo-shape of target by transforming embeddings into the desired manifold. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method in learning the 3D shape manifold from synthetic data via a single-view. The proposed method outperforms state-of-the-arts on Pix3D dataset with IoU 0.292 and CD 0.108, and reaches IoU 0.329 and CD 0.104 on Pascal 3D+.