 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Instance Segmentation and Tracking via Data Association and Single-stage Detector
Paper and Code
Mar 31, 2022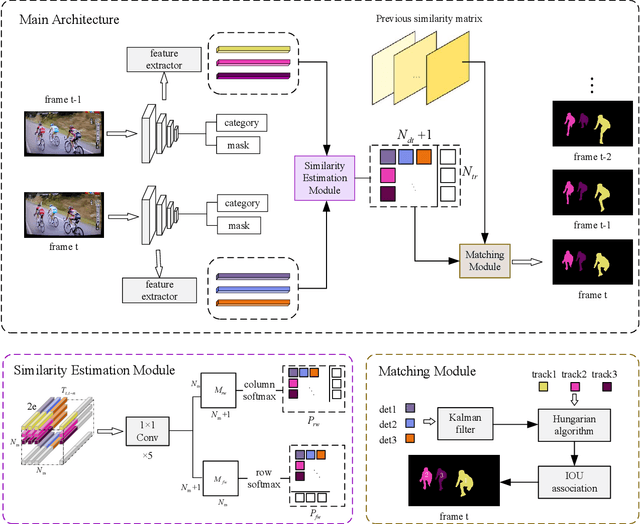


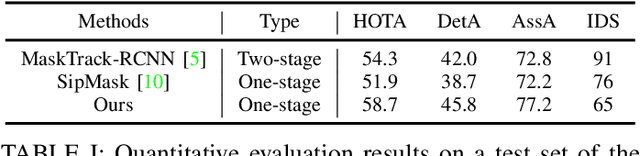
Human video instance segmentation plays an important role in computer understanding of human activities and is widely used in video processing, video surveillance, and human modeling in virtual reality. Most current VIS methods are based on Mask-RCNN framework, where the target appearance and motion information for data matching will increase computational cost and have an impact on segmentation real-time performance; on the other hand, the existing datasets for VIS focus less on all the people appearing in the video. In this paper, to solve the problems, we develop a new method for human video instance segmentation based on single-stage detector. To tracking the instance across the video, we have adopted data association strategy for matching the same instance in the video sequence, where we jointly learn target instance appearances and their affinities in a pair of video frames in an end-to-end fashion. We have also adopted the centroid sampling strategy for enhancing the embedding extraction ability of instance, which is to bias the instance position to the inside of each instance mask with heavy overlap condition. As a result, even there exists a sudden change in the character activity, the instance position will not move out of the mask, so that the problem that the same instance is represented by two different instances can be alleviated. Finally, we collect PVIS dataset by assembling several video instance segmentation datasets to fill the gap of the current lack of datasets dedicated to human video segmentation. Extensive simulations based on such dataset has been conduct. Simulation results verify the effectiveness and efficiency of the proposed work.