 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLE: A Unified Perspective of Data Augmentation for Cross-Spectral Re-identification
Nov 02, 2024



This paper makes a step towards modeling the modality discrepancy in the cross-spectral re-identification task. Based on the Lambertain model, we observe that the non-linear modality discrepancy mainly comes from diverse linear transformations acting on the surface of different materials. From this view, we unify all data augmentation strategies for cross-spectral re-identification by mimicking such local linear transformations and categorizing them into moderate transformation and radical transformation. By extending the observation, we propose a Random Linear Enhancement (RLE) strategy which includes Moderate Random Linear Enhancement (MRLE) and Radical Random Linear Enhancement (RRLE) to push the boundaries of both types of transformation. Moderate Random Linear Enhancement is designed to provide diverse image transformations that satisfy the original linear correlations under constrained conditions, whereas Radical Random Linear Enhancement seeks to generate local linear transformations directly without relying on external information. The experimental results not only demonstrate the superiority and effectiveness of RLE but also confirm its great potential as a general-purpose data augmentation for cross-spectral re-identification. The code is available at \textcolor{magenta}{\url{https://github.com/stone96123/RLE}}.
Frequency Domain Nuances Mining for Visible-Infrared Person Re-identification
Jan 10, 2024



The key of visible-infrared person re-identification (VIReID) lies in how to minimize the modality discrepancy between visible and infrared images. Existing methods mainly exploit the spatial information while ignoring the discriminative frequency information. To address this issue, this paper aims to reduce the modality discrepancy from the frequency domain perspective. Specifically, we propose a novel Frequency Domain Nuances Mining (FDNM) method to explore the cross-modality frequency domain information, which mainly includes an amplitude guided phase (AGP) module and an amplitude nuances mining (ANM) module. These two modules are mutually beneficial to jointly explore frequency domain visible-infrared nuances, thereby effectively reducing the modality discrepancy in the frequency domain. Besides, we propose a center-guided nuances mining loss to encourage the ANM module to preserve discriminative identity information while discovering diverse cross-modality nuances. Extensive experiments show that the proposed FDNM has significant advantages in improving the performance of VIReID. Specifically, our method outperforms the second-best method by 5.2\% in Rank-1 accuracy and 5.8\% in mAP on the SYSU-MM01 dataset under the indoor search mode, respectively. Besides, we also validate the effectiveness and generalization of our method on the challenging visible-infrared face recognition task. \textcolor{magenta}{The code will be available.}
PARFormer: Transformer-based Multi-Task Network for Pedestrian Attribute Recognition
Apr 14, 2023Pedestrian attribute recognition (PAR) has received increasing attention because of its wide application in video surveillance and pedestrian analysis. Extracting robust feature representation is one of the key challenges in this task. The existing methods mainly use the convolutional neural network (CNN) as the backbone network to extract features. However, these methods mainly focus on small discriminative regions while ignoring the global perspective. To overcome these limitations, we propose a pure transformer-based multi-task PAR network named PARFormer, which includes four modules. In the feature extraction module, we build a transformer-based strong baseline for feature extraction, which achieves competitive results on several PAR benchmarks compared with the existing CNN-based baseline methods. In the feature processing module, we propose an effective data augmentation strategy named batch random mask (BRM) block to reinforce the attentive feature learning of random patches. Furthermore, we propose a multi-attribute center loss (MACL) to enhance the inter-attribute discriminability in the feature representations. In the viewpoint perception module, we explore the impact of viewpoints on pedestrian attributes, and propose a multi-view contrastive loss (MCVL) that enables the network to exploit the viewpoint information. In the attribute recognition module, we alleviate the negative-positive imbalance problem to generate the attribute predictions. The above modules interact and jointly learn a highly discriminative feature space, and supervise the generation of the final features. Extensive experimental results show that the proposed PARFormer network performs well compared to the state-of-the-art methods on several public datasets, including PETA, RAP, and PA100K. Code will be released at https://github.com/xwf199/PARFormer.
MRCN: A Novel Modality Restitution and Compensation Network for Visible-Infrared Person Re-identification
Mar 26, 2023Visible-infrared person re-identification (VI-ReID), which aims to search identities across different spectra, is a challenging task due to large cross-modality discrepancy between visible and infrared images. The key to reduce the discrepancy is to filter out identity-irrelevant interference and effectively learn modality-invariant person representations. In this paper, we propose a novel Modality Restitution and Compensation Network (MRCN) to narrow the gap between the two modalities. Specifically, we first reduce the modality discrepancy by using two Instance Normalization (IN) layers. Next, to reduce the influence of IN layers on removing discriminative information and to reduce modality differences, we propose a Modality Restitution Module (MRM) and a Modality Compensation Module (MCM) to respectively distill modality-irrelevant and modality-relevant features from the removed information. Then, the modality-irrelevant features are used to restitute to the normalized visible and infrared features, while the modality-relevant features are used to compensate for the features of the other modality. Furthermore, to better disentangle the modality-relevant features and the modality-irrelevant features, we propose a novel Center-Quadruplet Causal (CQC) loss to encourage the network to effectively learn the modality-relevant features and the modality-irrelevant features. Extensive experiments are conducted to validate the superiority of our method on the challenging SYSU-MM01 and RegDB datasets. More remarkably, our method achieves 95.1% in terms of Rank-1 and 89.2% in terms of mAP on the RegDB dataset.
Diverse Embedding Expansion Network and Low-Light Cross-Modality Benchmark for Visible-Infrared Person Re-identification
Mar 25, 2023



For the visible-infrared person re-identification (VIReID) task, one of the major challenges is the modality gaps between visible (VIS) and infrared (IR) images. However, the training samples are usually limited, while the modality gaps are too large, which leads that the existing methods cannot effectively mine diverse cross-modality clues. To handle this limitation, we propose a novel augmentation network in the embedding space, called diverse embedding expansion network (DEEN). The proposed DEEN can effectively generate diverse embeddings to learn the informative feature representations and reduce the modality discrepancy between the VIS and IR images. Moreover, the VIReID model may be seriously affected by drastic illumination changes, while all the existing VIReID datasets are captured under sufficient illumination without significant light changes. Thus, we provide a low-light cross-modality (LLCM) dataset, which contains 46,767 bounding boxes of 1,064 identities captured by 9 RGB/IR cameras. Extensive experiments on the SYSU-MM01, RegDB and LLCM datasets show the superiority of the proposed DEEN over several other state-of-the-art methods. The code and dataset are released at: https://github.com/ZYK100/LLCM
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
Exploring Invariant Representation for Visible-Infrared Person Re-Identification
Feb 02, 2023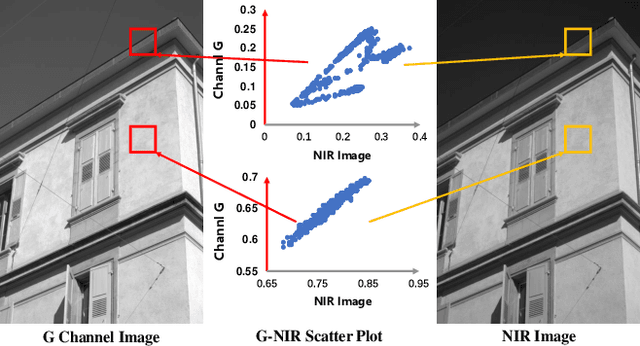

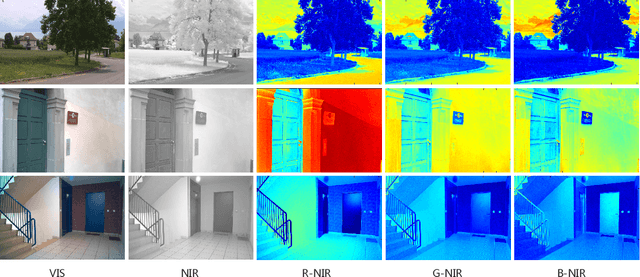

Cross-spectral person re-identification, which aims to associate identities to pedestrians across different spectra, faces a main challenge of the modality discrepancy. In this paper, we address the problem from both image-level and feature-level in an end-to-end hybrid learning framework named robust feature mining network (RFM). In particular, we observe that the reflective intensity of the same surface in photos shot in different wavelengths could be transformed using a linear model. Besides, we show the variable linear factor across the different surfaces is the main culprit which initiates the modality discrepancy. We integrate such a reflection observation into an image-level data augmentation by proposing the linear transformation generator (LTG). Moreover, at the feature level, we introduce a cross-center loss to explore a more compact intra-class distribution and modality-aware spatial attention to take advantage of textured regions more efficiently. Experiment results on two standard cross-spectral person re-identification datasets, i.e., RegDB and SYSU-MM01, have demonstrated state-of-the-art performance.