 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPVForensics: Jointing Non-critical Phonemes and Visemes for Deepfake Detection
Jun 12, 2023Deepfake technologies empowered by deep learning are rapidly evolving, creating new security concerns for society. Existing multimodal detection methods usually capture audio-visual inconsistencies to expose Deepfake videos. More seriously, the advanced Deepfake technology realizes the audio-visual calibration of the critical phoneme-viseme regions, achieving a more realistic tampering effect, which brings new challenges. To address this problem, we propose a novel Deepfake detection method to mine the correlation between Non-critical Phonemes and Visemes, termed NPVForensics. Firstly, we propose the Local Feature Aggregation block with Swin Transformer (LFA-ST) to construct non-critical phoneme-viseme and corresponding facial feature streams effectively. Secondly, we design a loss function for the fine-grained motion of the talking face to measure the evolutionary consistency of non-critical phoneme-viseme. Next, we design a phoneme-viseme awareness module for cross-modal feature fusion and representation alignment, so that the modality gap can be reduced and the intrinsic complementarity of the two modalities can be better explored. Finally, a self-supervised pre-training strategy is leveraged to thoroughly learn the audio-visual correspondences in natural videos. In this manner, our model can be easily adapted to the downstream Deepfake datasets with fine-tuning. Extensive experiments on existing benchmarks demonstrate that the proposed approach outperforms state-of-the-art methods.
Image Splicing Detection, Localization and Attribution via JPEG Primary Quantization Matrix Estimation and Clustering
Feb 02, 2021
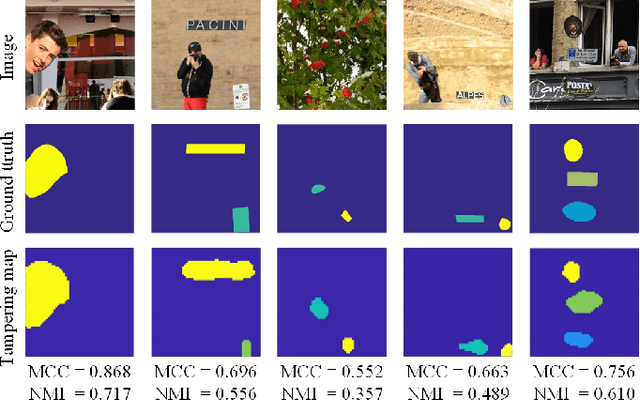
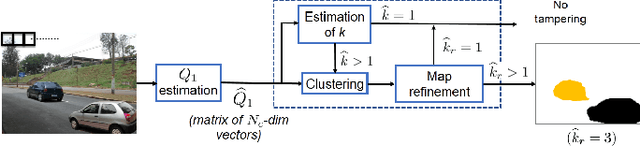
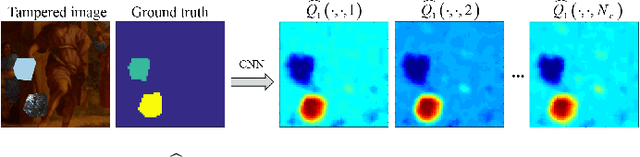
Detection of inconsistencies of double JPEG artefacts across different image regions is often used to detect local image manipulations, like image splicing, and to localize them. In this paper, we move one step further, proposing an end-to-end system that, in addition to detecting and localizing spliced regions, can also distinguish regions coming from different donor images. We assume that both the spliced regions and the background image have undergone a double JPEG compression, and use a local estimate of the primary quantization matrix to distinguish between spliced regions taken from different sources. To do so, we cluster the image blocks according to the estimated primary quantization matrix and refine the result by means of morphological reconstruction. The proposed method can work in a wide variety of settings including aligned and non-aligned double JPEG compression, and regardless of whether the second compression is stronger or weaker than the first one. We validated the proposed approach by means of extensive experiments showing its superior performance with respect to baseline methods working in similar conditions.
Efficient video integrity analysis through container characterization
Jan 26, 2021
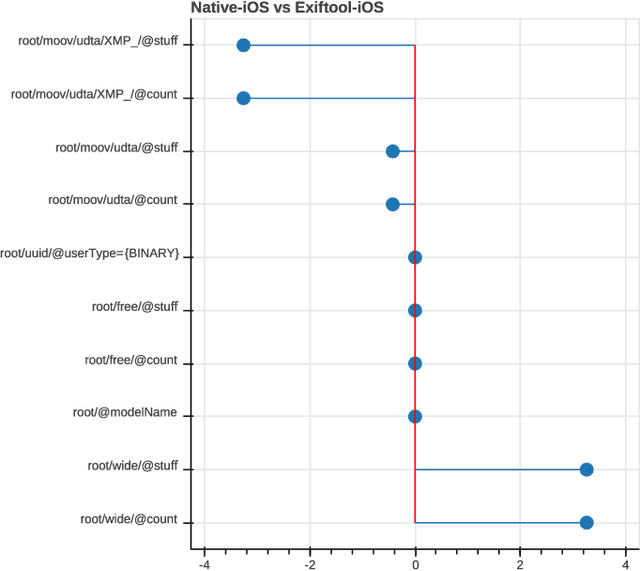
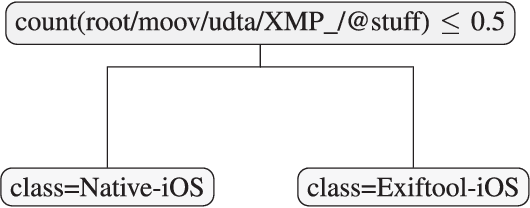
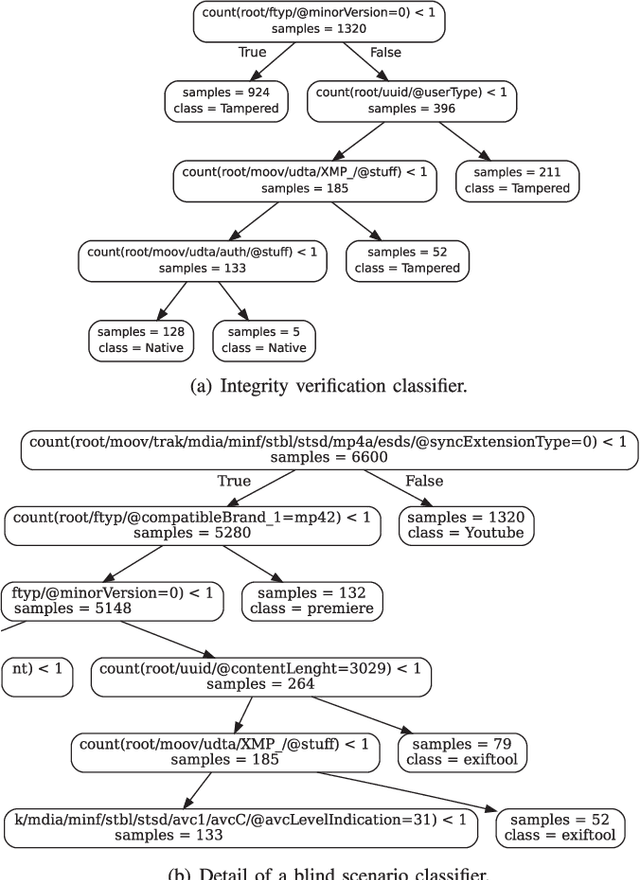
Most video forensic techniques look for traces within the data stream that are, however, mostly ineffective when dealing with strongly compressed or low resolution videos. Recent research highlighted that useful forensic traces are also left in the video container structure, thus offering the opportunity to understand the life-cycle of a video file without looking at the media stream itself. In this paper we introduce a container-based method to identify the software used to perform a video manipulation and, in most cases, the operating system of the source device. As opposed to the state of the art, the proposed method is both efficient and effective and can also provide a simple explanation for its decisions. This is achieved by using a decision-tree-based classifier applied to a vectorial representation of the video container structure. We conducted an extensive validation on a dataset of 7000 video files including both software manipulated contents (ffmpeg, Exiftool, Adobe Premiere, Avidemux, and Kdenlive), and videos exchanged through social media platforms (Facebook, TikTok, Weibo and YouTube). This dataset has been made available to the research community. The proposed method achieves an accuracy of 97.6% in distinguishing pristine from tampered videos and classifying the editing software, even when the video is cut without re-encoding or when it is downscaled to the size of a thumbnail. Furthermore, it is capable of correctly identifying the operating system of the source device for most of the tampered videos.
* Accepted by IEEE Journal of Selected Topics in Signal Processing
Mining Generalized Features for Detecting AI-Manipulated Fake Faces
Oct 27, 2020Recently, AI-manipulated face techniques have developed rapidly and constantly, which has raised new security issues in society. Although existing detection methods consider different categories of fake faces, the performance on detecting the fake faces with "unseen" manipulation techniques is still poor due to the distribution bias among cross-manipulation techniques. To solve this problem, we propose a novel framework that focuses on mining intrinsic features and further eliminating the distribution bias to improve the generalization ability. Firstly, we focus on mining the intrinsic clues in the channel difference image (CDI) and spectrum image (SI) from the camera imaging process and the indispensable step in AI manipulation process. Then, we introduce the Octave Convolution (OctConv) and an attention-based fusion module to effectively and adaptively mine intrinsic features from CDI and SI. Finally, we design an alignment module to eliminate the bias of manipulation techniques to obtain a more generalized detection framework. We evaluate the proposed framework on four categories of fake faces datasets with the most popular and state-of-the-art manipulation techniques, and achieve very competitive performances. To further verify the generalization ability of the proposed framework, we conduct experiments on cross-manipulation techniques, and the results show the advantages of our method.
Increased-confidence adversarial examples for improved transferability of Counter-Forensic attacks
May 12, 2020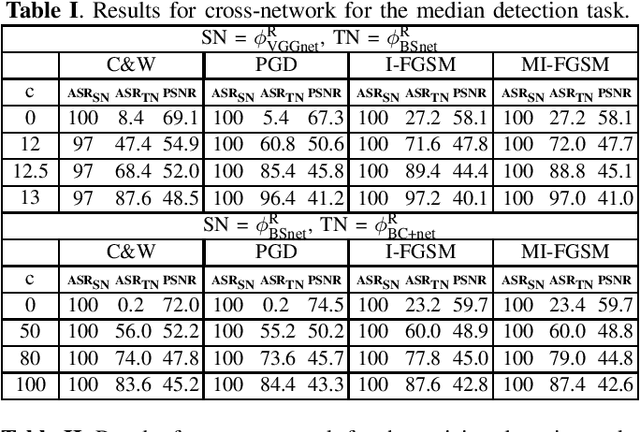


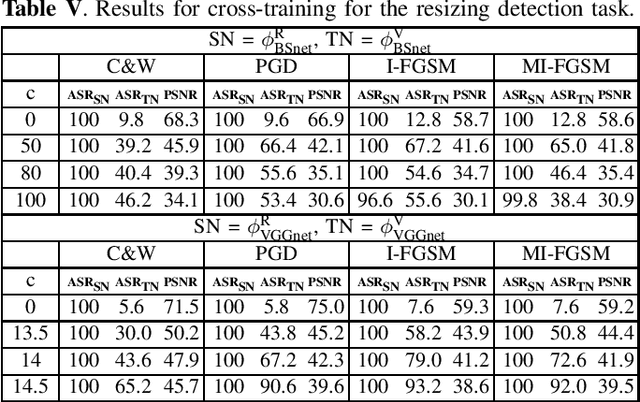
Transferability of adversarial examples is a key issue to study the security of multimedia forensics (MMF) techniques relying on Deep Learning (DL). The transferability of the attacks, in fact, would open the way to the deployment of successful counter forensics attacks also in cases where the attacker does not have a full knowledge of the to-be-attacked system. Some preliminary works have shown that adversarial examples against CNN-based image forensics detectors are in general non-transferrable, at least when the basic versions of the attacks implemented in the most popular attack packages are adopted. In this paper, we introduce a general strategy to increase the strength of the attacks and evaluate the transferability of the adversarial examples when such a strength varies. We experimentally show that, in this way, attack transferability can be improved to a large extent, at the expense of a larger distortion. Our research confirms the security threats posed by the existence of adversarial examples even in multimedia forensics scenarios, thus calling for new defense strategies to improve the security of DL-based MMF techniques.
Security Consideration For Deep Learning-Based Image Forensics
Apr 03, 2018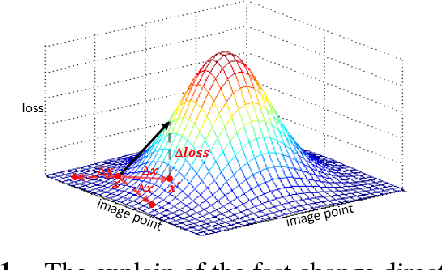

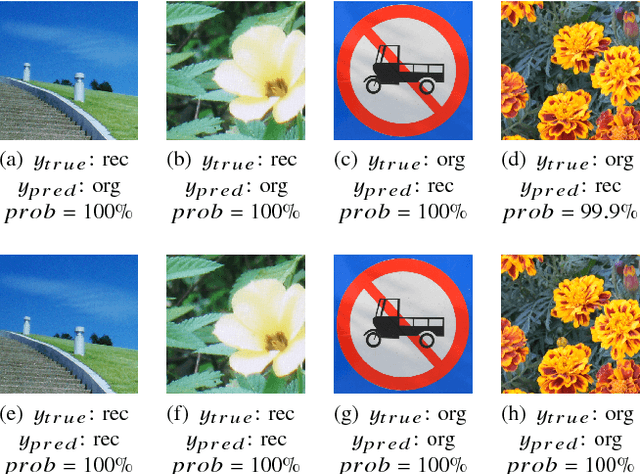
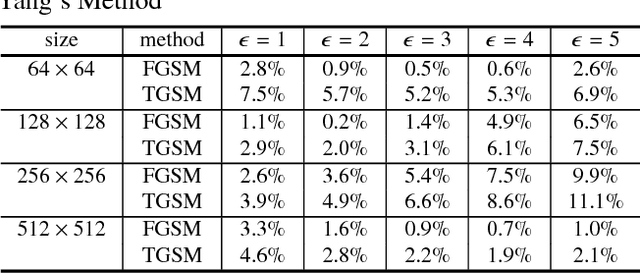
Recently, image forensics community has paied attention to the research on the design of effective algorithms based on deep learning technology and facts proved that combining the domain knowledge of image forensics and deep learning would achieve more robust and better performance than the traditional schemes. Instead of improving it, in this paper, the safety of deep learning based methods in the field of image forensics is taken into account. To the best of our knowledge, this is a first work focusing on this topic. Specifically, we experimentally find that the method using deep learning would fail when adding the slight noise into the images (adversarial images). Furthermore, two kinds of strategys are proposed to enforce security of deep learning-based method. Firstly, an extra penalty term to the loss function is added, which is referred to the 2-norm of the gradient of the loss with respect to the input images, and then an novel training method are adopt to train the model by fusing the normal and adversarial images. Experimental results show that the proposed algorithm can achieve good performance even in the case of adversarial images and provide a safety consideration for deep learning-based image forensics
Non-Local Graph-Based Prediction For Reversible Data Hiding In Images
Feb 20, 2018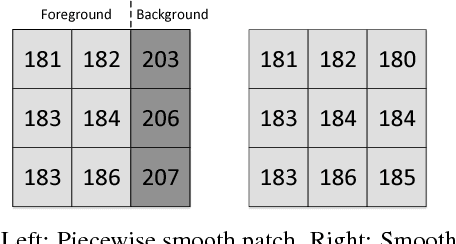



Reversible data hiding (RDH) is desirable in applications where both the hidden message and the cover medium need to be recovered without loss. Among many RDH approaches is prediction-error expansion (PEE), containing two steps: i) prediction of a target pixel value, and ii) embedding according to the value of prediction-error. In general, higher prediction performance leads to larger embedding capacity and/or lower signal distortion. Leveraging on recent advances in graph signal processing (GSP), we pose pixel prediction as a graph-signal restoration problem, where the appropriate edge weights of the underlying graph are computed using a similar patch searched in a semi-local neighborhood. Specifically, for each candidate patch, we first examine eigenvalues of its structure tensor to estimate its local smoothness. If sufficiently smooth, we pose a maximum a posteriori (MAP) problem using either a quadratic Laplacian regularizer or a graph total variation (GTV) term as signal prior. While the MAP problem using the first prior has a closed-form solution, we design an efficient algorithm for the second prior using alternating direction method of multipliers (ADMM) with nested proximal gradient descent. Experimental results show that with better quality GSP-based prediction, at low capacity the visual quality of the embedded image exceeds state-of-the-art methods noticeably.
Source Camera Identification Based On Content-Adaptive Fusion Network
Mar 15, 2017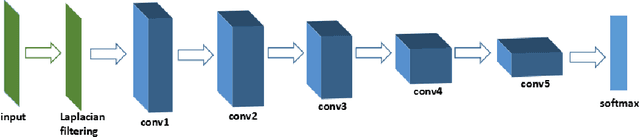

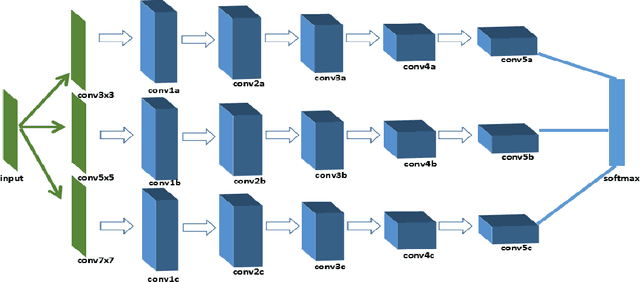
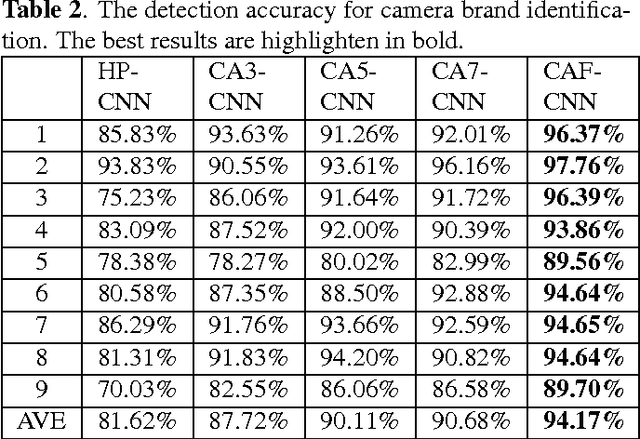
Source camera identification is still a hard task in forensics community, especially for the case of the small query image size. In this paper, we propose a solution to identify the source camera of the small-size images: content-adaptive fusion network. In order to learn better feature representation from the input data, content-adaptive convolutional neural networks(CA-CNN) are constructed. We add a convolutional layer in preprocessing stage. Moreover, with the purpose of capturing more comprehensive information, we parallel three CA-CNNs: CA3-CNN, CA5-CNN, CA7-CNN to get the content-adaptive fusion network. The difference of three CA-CNNs lies in the convolutional kernel size of pre-processing layer. The experimental results show that the proposed method is practicable and satisfactory.