 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient video integrity analysis through container characterization
Jan 26, 2021
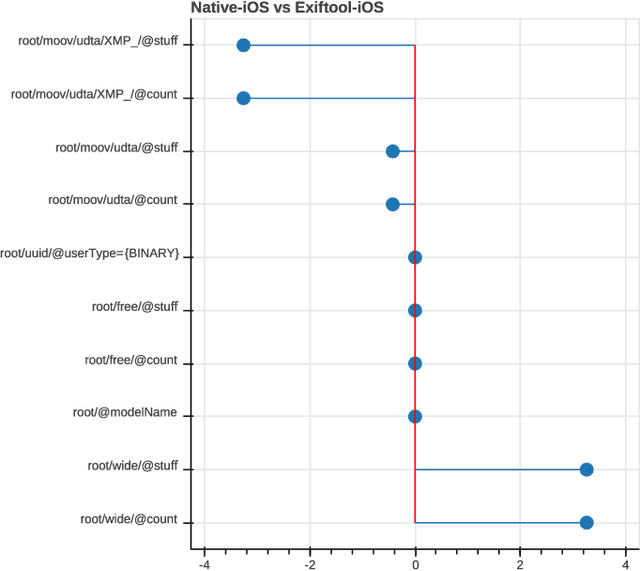
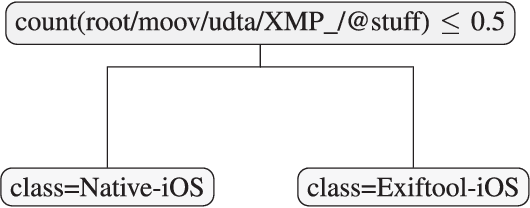
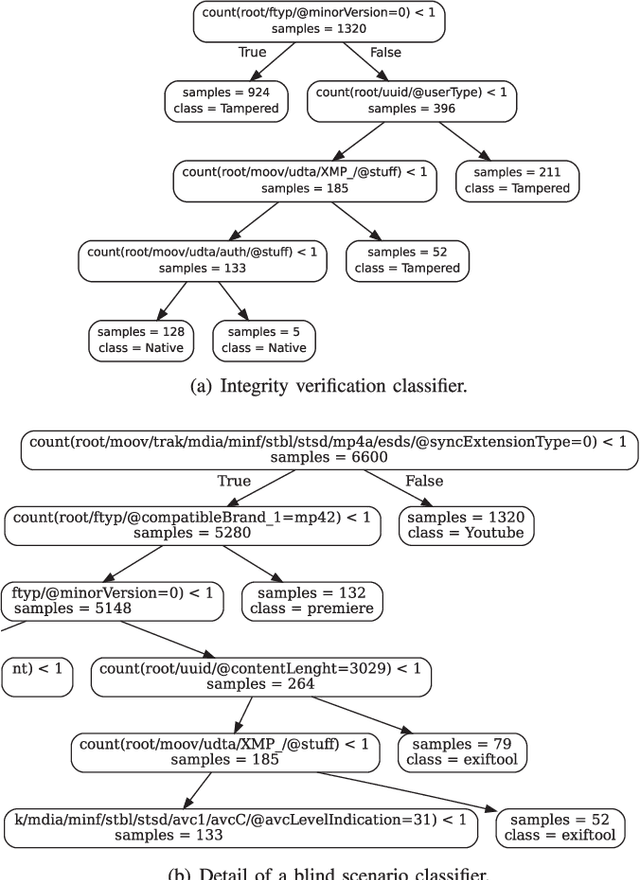
Most video forensic techniques look for traces within the data stream that are, however, mostly ineffective when dealing with strongly compressed or low resolution videos. Recent research highlighted that useful forensic traces are also left in the video container structure, thus offering the opportunity to understand the life-cycle of a video file without looking at the media stream itself. In this paper we introduce a container-based method to identify the software used to perform a video manipulation and, in most cases, the operating system of the source device. As opposed to the state of the art, the proposed method is both efficient and effective and can also provide a simple explanation for its decisions. This is achieved by using a decision-tree-based classifier applied to a vectorial representation of the video container structure. We conducted an extensive validation on a dataset of 7000 video files including both software manipulated contents (ffmpeg, Exiftool, Adobe Premiere, Avidemux, and Kdenlive), and videos exchanged through social media platforms (Facebook, TikTok, Weibo and YouTube). This dataset has been made available to the research community. The proposed method achieves an accuracy of 97.6% in distinguishing pristine from tampered videos and classifying the editing software, even when the video is cut without re-encoding or when it is downscaled to the size of a thumbnail. Furthermore, it is capable of correctly identifying the operating system of the source device for most of the tampered videos.
* Accepted by IEEE Journal of Selected Topics in Signal Processing
Security Consideration For Deep Learning-Based Image Forensics
Apr 03, 2018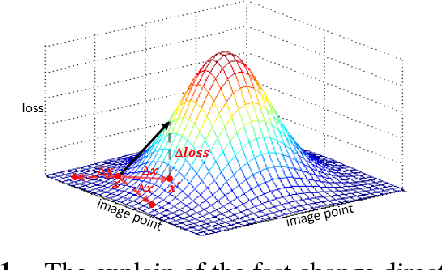

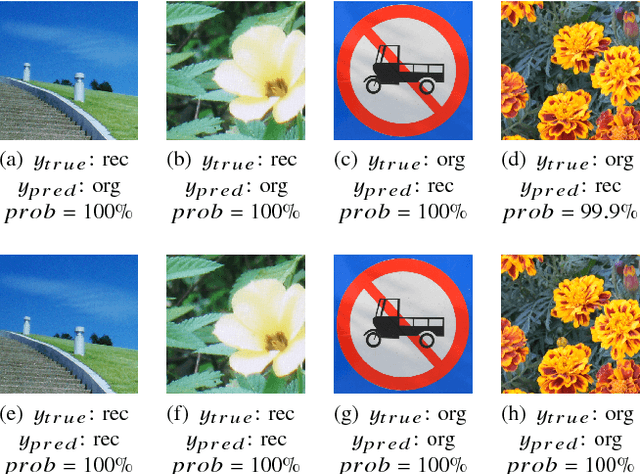
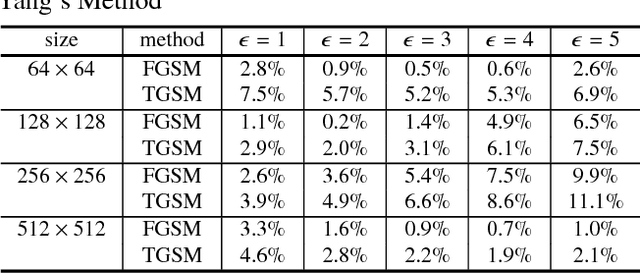
Recently, image forensics community has paied attention to the research on the design of effective algorithms based on deep learning technology and facts proved that combining the domain knowledge of image forensics and deep learning would achieve more robust and better performance than the traditional schemes. Instead of improving it, in this paper, the safety of deep learning based methods in the field of image forensics is taken into account. To the best of our knowledge, this is a first work focusing on this topic. Specifically, we experimentally find that the method using deep learning would fail when adding the slight noise into the images (adversarial images). Furthermore, two kinds of strategys are proposed to enforce security of deep learning-based method. Firstly, an extra penalty term to the loss function is added, which is referred to the 2-norm of the gradient of the loss with respect to the input images, and then an novel training method are adopt to train the model by fusing the normal and adversarial images. Experimental results show that the proposed algorithm can achieve good performance even in the case of adversarial images and provide a safety consideration for deep learning-based image forensics
Source Camera Identification Based On Content-Adaptive Fusion Network
Mar 15, 2017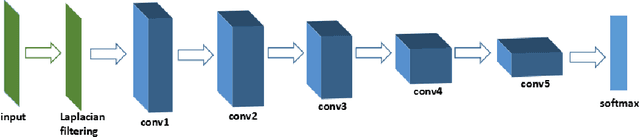

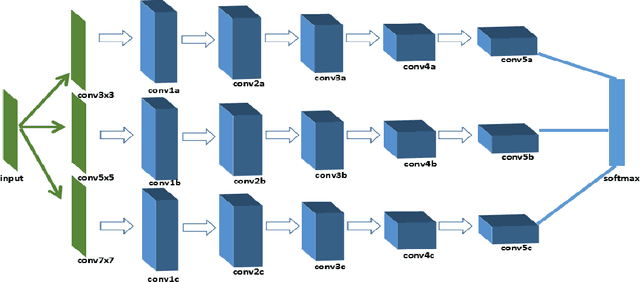
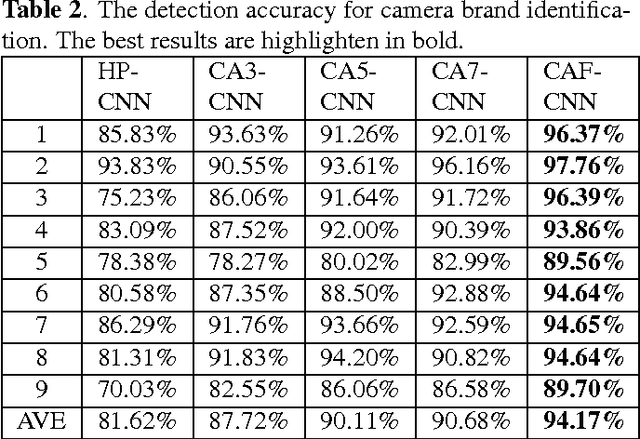
Source camera identification is still a hard task in forensics community, especially for the case of the small query image size. In this paper, we propose a solution to identify the source camera of the small-size images: content-adaptive fusion network. In order to learn better feature representation from the input data, content-adaptive convolutional neural networks(CA-CNN) are constructed. We add a convolutional layer in preprocessing stage. Moreover, with the purpose of capturing more comprehensive information, we parallel three CA-CNNs: CA3-CNN, CA5-CNN, CA7-CNN to get the content-adaptive fusion network. The difference of three CA-CNNs lies in the convolutional kernel size of pre-processing layer. The experimental results show that the proposed method is practicable and satisfactory.