 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreased-confidence adversarial examples for improved transferability of Counter-Forensic attacks
Paper and Code
May 12, 2020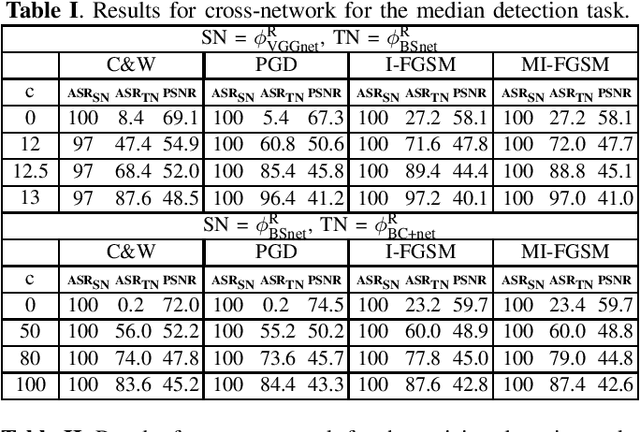


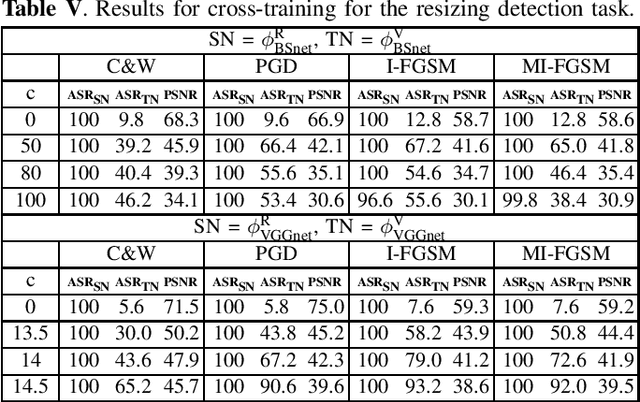
Transferability of adversarial examples is a key issue to study the security of multimedia forensics (MMF) techniques relying on Deep Learning (DL). The transferability of the attacks, in fact, would open the way to the deployment of successful counter forensics attacks also in cases where the attacker does not have a full knowledge of the to-be-attacked system. Some preliminary works have shown that adversarial examples against CNN-based image forensics detectors are in general non-transferrable, at least when the basic versions of the attacks implemented in the most popular attack packages are adopted. In this paper, we introduce a general strategy to increase the strength of the attacks and evaluate the transferability of the adversarial examples when such a strength varies. We experimentally show that, in this way, attack transferability can be improved to a large extent, at the expense of a larger distortion. Our research confirms the security threats posed by the existence of adversarial examples even in multimedia forensics scenarios, thus calling for new defense strategies to improve the security of DL-based MMF techniques.