 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Re-Ranking with Multimodal Fusion and Target-Oriented Auxiliary Tasks in E-Commerce Search
Aug 11, 2024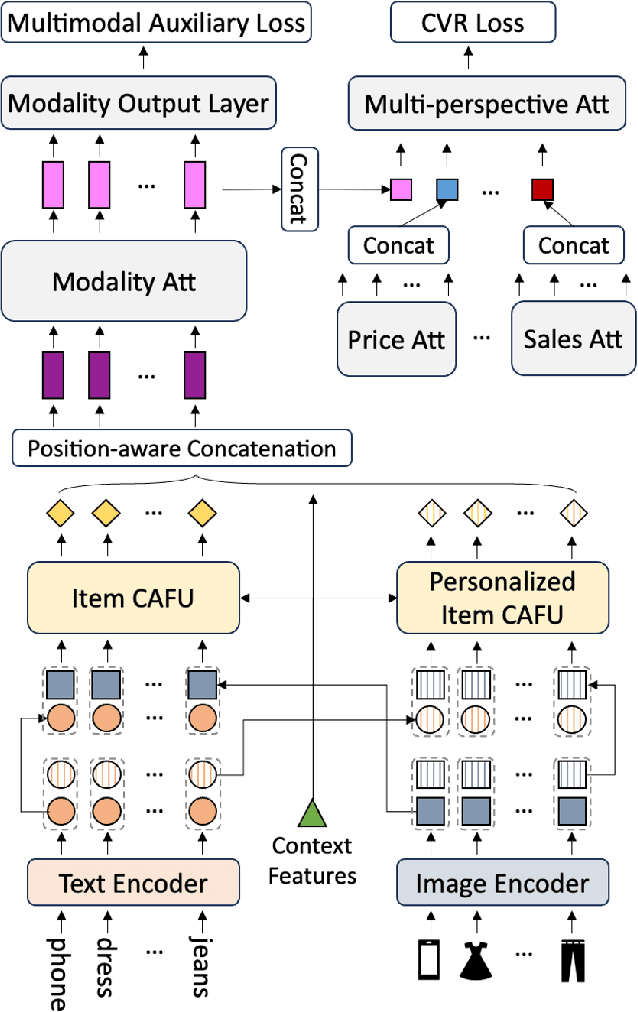
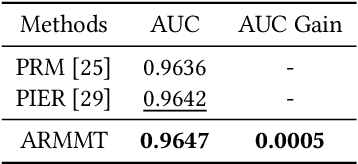

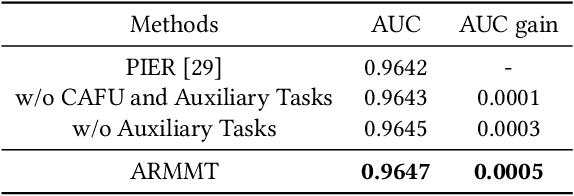
In the rapidly evolving field of e-commerce, the effectiveness of search re-ranking models is crucial for enhancing user experience and driving conversion rates. Despite significant advancements in feature representation and model architecture, the integration of multimodal information remains underexplored. This study addresses this gap by investigating the computation and fusion of textual and visual information in the context of re-ranking. We propose \textbf{A}dvancing \textbf{R}e-Ranking with \textbf{M}ulti\textbf{m}odal Fusion and \textbf{T}arget-Oriented Auxiliary Tasks (ARMMT), which integrates an attention-based multimodal fusion technique and an auxiliary ranking-aligned task to enhance item representation and improve targeting capabilities. This method not only enriches the understanding of product attributes but also enables more precise and personalized recommendations. Experimental evaluations on JD.com's search platform demonstrate that ARMMT achieves state-of-the-art performance in multimodal information integration, evidenced by a 0.22\% increase in the Conversion Rate (CVR), significantly contributing to Gross Merchandise Volume (GMV). This pioneering approach has the potential to revolutionize e-commerce re-ranking, leading to elevated user satisfaction and business growth.
AirPhyNet: Harnessing Physics-Guided Neural Networks for Air Quality Prediction
Feb 07, 2024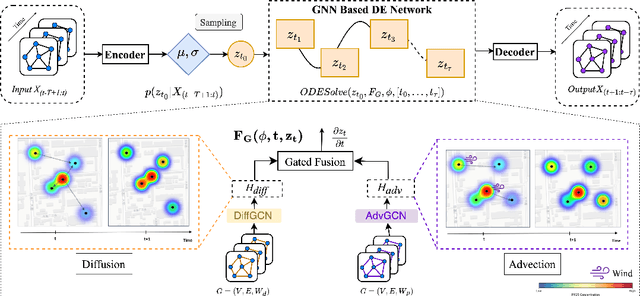
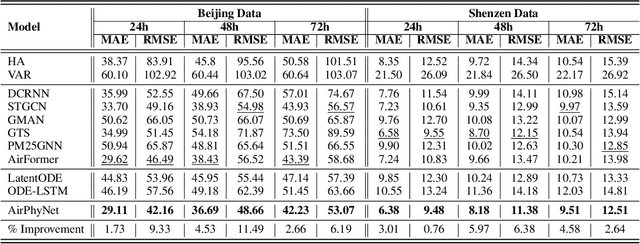
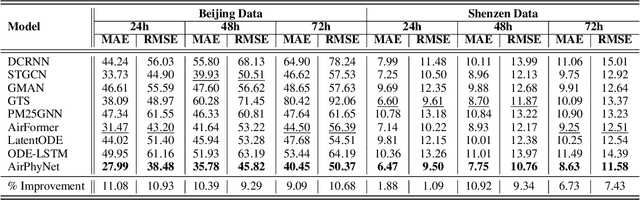
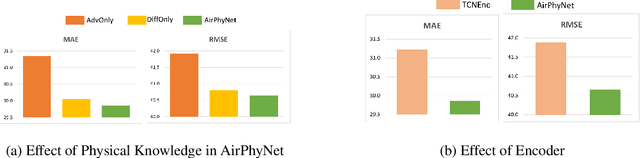
Air quality prediction and modelling plays a pivotal role in public health and environment management, for individuals and authorities to make informed decisions. Although traditional data-driven models have shown promise in this domain, their long-term prediction accuracy can be limited, especially in scenarios with sparse or incomplete data and they often rely on black-box deep learning structures that lack solid physical foundation leading to reduced transparency and interpretability in predictions. To address these limitations, this paper presents a novel approach named Physics guided Neural Network for Air Quality Prediction (AirPhyNet). Specifically, we leverage two well-established physics principles of air particle movement (diffusion and advection) by representing them as differential equation networks. Then, we utilize a graph structure to integrate physics knowledge into a neural network architecture and exploit latent representations to capture spatio-temporal relationships within the air quality data. Experiments on two real-world benchmark datasets demonstrate that AirPhyNet outperforms state-of-the-art models for different testing scenarios including different lead time (24h, 48h, 72h), sparse data and sudden change prediction, achieving reduction in prediction errors up to 10%. Moreover, a case study further validates that our model captures underlying physical processes of particle movement and generates accurate predictions with real physical meaning.
Self-Supervised Deconfounding Against Spatio-Temporal Shifts: Theory and Modeling
Nov 21, 2023



As an important application of spatio-temporal (ST) data, ST traffic forecasting plays a crucial role in improving urban travel efficiency and promoting sustainable development. In practice, the dynamics of traffic data frequently undergo distributional shifts attributed to external factors such as time evolution and spatial differences. This entails forecasting models to handle the out-of-distribution (OOD) issue where test data is distributed differently from training data. In this work, we first formalize the problem by constructing a causal graph of past traffic data, future traffic data, and external ST contexts. We reveal that the failure of prior arts in OOD traffic data is due to ST contexts acting as a confounder, i.e., the common cause for past data and future ones. Then, we propose a theoretical solution named Disentangled Contextual Adjustment (DCA) from a causal lens. It differentiates invariant causal correlations against variant spurious ones and deconfounds the effect of ST contexts. On top of that, we devise a Spatio-Temporal sElf-superVised dEconfounding (STEVE) framework. It first encodes traffic data into two disentangled representations for associating invariant and variant ST contexts. Then, we use representative ST contexts from three conceptually different perspectives (i.e., temporal, spatial, and semantic) as self-supervised signals to inject context information into both representations. In this way, we improve the generalization ability of the learned context-oriented representations to OOD ST traffic forecasting. Comprehensive experiments on four large-scale benchmark datasets demonstrate that our STEVE consistently outperforms the state-of-the-art baselines across various ST OOD scenarios.
Multi-Factor Spatio-Temporal Prediction based on Graph Decomposition Learning
Oct 16, 2023Spatio-temporal (ST) prediction is an important and widely used technique in data mining and analytics, especially for ST data in urban systems such as transportation data. In practice, the ST data generation is usually influenced by various latent factors tied to natural phenomena or human socioeconomic activities, impacting specific spatial areas selectively. However, existing ST prediction methods usually do not refine the impacts of different factors, but directly model the entangled impacts of multiple factors. This amplifies the modeling complexity of ST data and compromises model interpretability. To this end, we propose a multi-factor ST prediction task that predicts partial ST data evolution under different factors, and combines them for a final prediction. We make two contributions to this task: an effective theoretical solution and a portable instantiation framework. Specifically, we first propose a theoretical solution called decomposed prediction strategy and prove its effectiveness from the perspective of information entropy theory. On top of that, we instantiate a novel model-agnostic framework, named spatio-temporal graph decomposition learning (STGDL), for multi-factor ST prediction. The framework consists of two main components: an automatic graph decomposition module that decomposes the original graph structure inherent in ST data into subgraphs corresponding to different factors, and a decomposed learning network that learns the partial ST data on each subgraph separately and integrates them for the final prediction. We conduct extensive experiments on four real-world ST datasets of two types of graphs, i.e., grid graph and network graph. Results show that our framework significantly reduces prediction errors of various ST models by 9.41% on average (35.36% at most). Furthermore, a case study reveals the interpretability potential of our framework.
Spatio-Temporal Self-Supervised Learning for Traffic Flow Prediction
Dec 07, 2022



Robust prediction of citywide traffic flows at different time periods plays a crucial role in intelligent transportation systems. While previous work has made great efforts to model spatio-temporal correlations, existing methods still suffer from two key limitations: i) Most models collectively predict all regions' flows without accounting for spatial heterogeneity, i.e., different regions may have skewed traffic flow distributions. ii) These models fail to capture the temporal heterogeneity induced by time-varying traffic patterns, as they typically model temporal correlations with a shared parameterized space for all time periods. To tackle these challenges, we propose a novel Spatio-Temporal Self-Supervised Learning (ST-SSL) traffic prediction framework which enhances the traffic pattern representations to be reflective of both spatial and temporal heterogeneity, with auxiliary self-supervised learning paradigms. Specifically, our ST-SSL is built over an integrated module with temporal and spatial convolutions for encoding the information across space and time. To achieve the adaptive spatio-temporal self-supervised learning, our ST-SSL first performs the adaptive augmentation over the traffic flow graph data at both attribute- and structure-levels. On top of the augmented traffic graph, two SSL auxiliary tasks are constructed to supplement the main traffic prediction task with spatial and temporal heterogeneity-aware augmentation. Experiments on four benchmark datasets demonstrate that ST-SSL consistently outperforms various state-of-the-art baselines. Since spatio-temporal heterogeneity widely exists in practical datasets, the proposed framework may also cast light on other spatial-temporal applications. Model implementation is available at https://github.com/Echo-Ji/ST-SSL.