 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Semantic Hegemony: Decoupling Principal and Residual Subspaces for Generalized OOD Detection
Feb 05, 2026While feature-based post-hoc methods have made significant strides in Out-of-Distribution (OOD) detection, we uncover a counter-intuitive Simplicity Paradox in existing state-of-the-art (SOTA) models: these models exhibit keen sensitivity in distinguishing semantically subtle OOD samples but suffer from severe Geometric Blindness when confronting structurally distinct yet semantically simple samples or high-frequency sensor noise. We attribute this phenomenon to Semantic Hegemony within the deep feature space and reveal its mathematical essence through the lens of Neural Collapse. Theoretical analysis demonstrates that the spectral concentration bias, induced by the high variance of the principal subspace, numerically masks the structural distribution shift signals that should be significant in the residual subspace. To address this issue, we propose D-KNN, a training-free, plug-and-play geometric decoupling framework. This method utilizes orthogonal decomposition to explicitly separate semantic components from structural residuals and introduces a dual-space calibration mechanism to reactivate the model's sensitivity to weak residual signals. Extensive experiments demonstrate that D-KNN effectively breaks Semantic Hegemony, establishing new SOTA performance on both CIFAR and ImageNet benchmarks. Notably, in resolving the Simplicity Paradox, it reduces the FPR95 from 31.3% to 2.3%; when addressing sensor failures such as Gaussian noise, it boosts the detection performance (AUROC) from a baseline of 79.7% to 94.9%.
DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
Nov 24, 2020
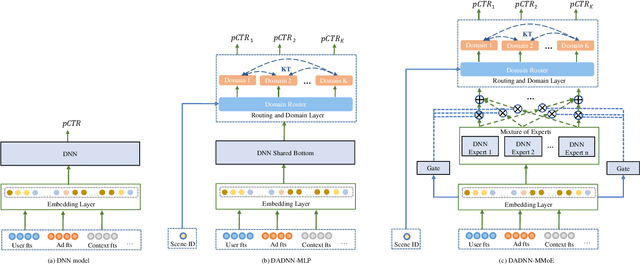
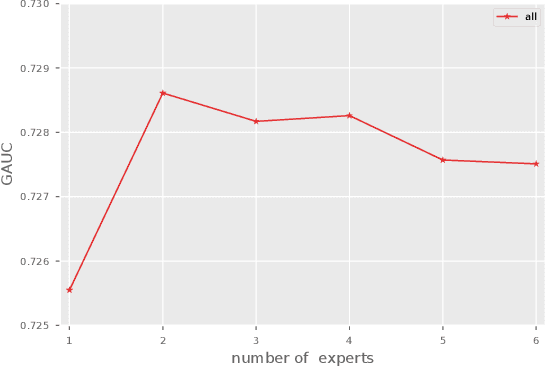
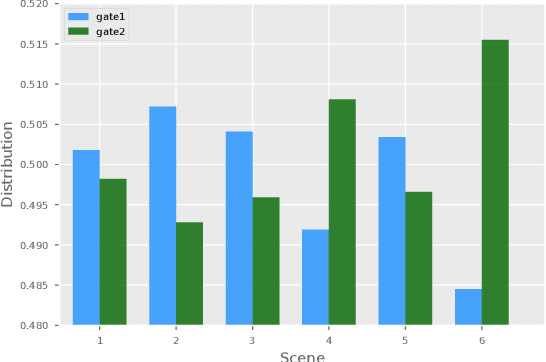
Click through rate(CTR) prediction is a core task in advertising systems. The booming e-commerce business in our company, results in a growing number of scenes. Most of them are so-called long-tail scenes, which means that the traffic of a single scene is limited, but the overall traffic is considerable. Typical studies mainly focus on serving a single scene with a well designed model. However, this method brings excessive resource consumption both on offline training and online serving. Besides, simply training a single model with data from multiple scenes ignores the characteristics of their own. To address these challenges, we propose a novel but practical model named Domain-Aware Deep Neural Network(DADNN) by serving multiple scenes with only one model. Specifically, shared bottom block among all scenes is applied to learn a common representation, while domain-specific heads maintain the characteristics of every scene. Besides, knowledge transfer is introduced to enhance the opportunity of knowledge sharing among different scenes. In this paper, we study two instances of DADNN where its shared bottom block is multilayer perceptron(MLP) and Multi-gate Mixture-of-Experts(MMoE) respectively, for which we denote as DADNN-MLP and DADNN-MMoE.Comprehensive offline experiments on a real production dataset from our company show that DADNN outperforms several state-of-the-art methods for multi-scene CTR prediction. Extensive online A/B tests reveal that DADNN-MLP contributes up to 6.7% CTR and 3.0% CPM(Cost Per Mille) promotion compared with a well-engineered DCN model. Furthermore, DADNN-MMoE outperforms DADNN-MLP with a relative improvement of 2.2% and 2.7% on CTR and CPM respectively. More importantly, DADNN utilizes a single model for multiple scenes which saves a lot of offline training and online serving resources.