 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Network for RGB-D Saliency Detection
Paper and Code
Dec 01, 2021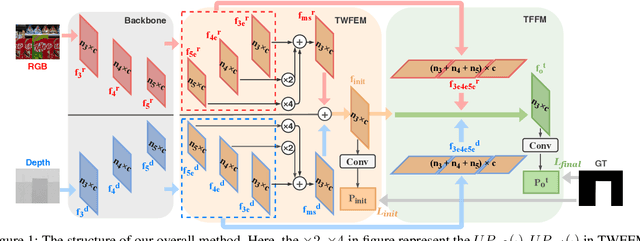
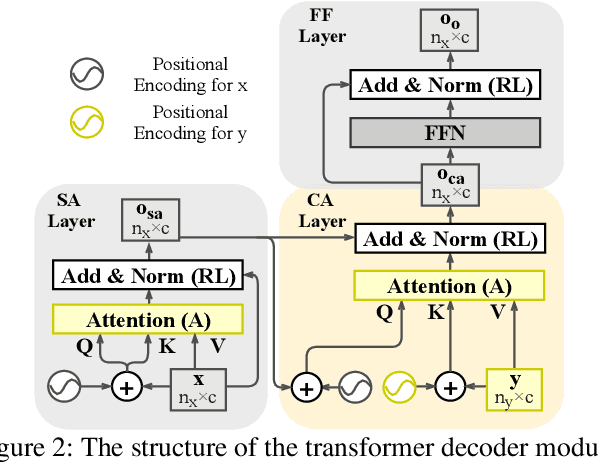

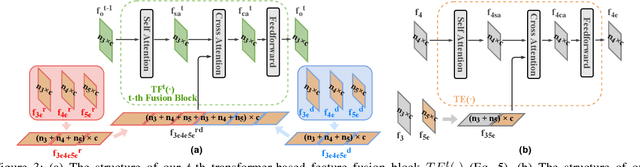
RGB-D saliency detection integrates information from both RGB images and depth maps to improve prediction of salient regions under challenging conditions. The key to RGB-D saliency detection is to fully mine and fuse information at multiple scales across the two modalities. Previous approaches tend to apply the multi-scale and multi-modal fusion separately via local operations, which fails to capture long-range dependencies. Here we propose a transformer-based network to address this issue. Our proposed architecture is composed of two modules: a transformer-based within-modality feature enhancement module (TWFEM) and a transformer-based feature fusion module (TFFM). TFFM conducts a sufficient feature fusion by integrating features from multiple scales and two modalities over all positions simultaneously. TWFEM enhances feature on each scale by selecting and integrating complementary information from other scales within the same modality before TFFM. We show that transformer is a uniform operation which presents great efficacy in both feature fusion and feature enhancement, and simplifies the model design. Extensive experimental results on six benchmark datasets demonstrate that our proposed network performs favorably against state-of-the-art RGB-D saliency detection methods.