 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Confidence Calibration for Large Language Models
Paper and Code
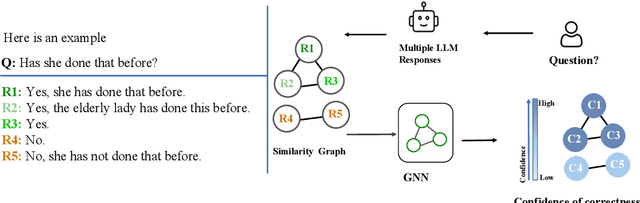
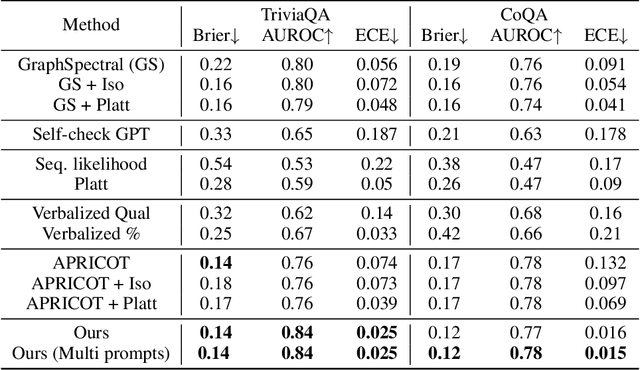
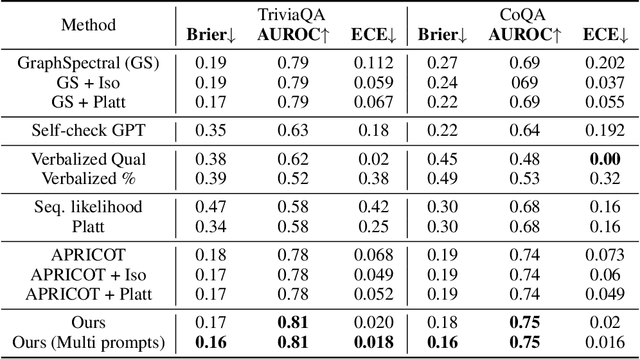
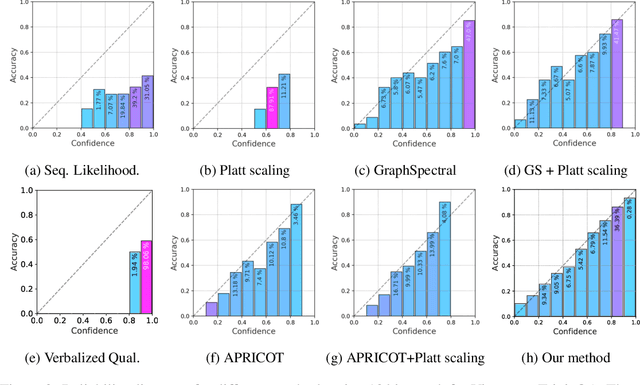
One important approach to improving the reliability of large language models (LLMs) is to provide accurate confidence estimations regarding the correctness of their answers. However, developing a well-calibrated confidence estimation model is challenging, as mistakes made by LLMs can be difficult to detect. We propose a novel method combining the LLM's self-consistency with labeled data and training an auxiliary model to estimate the correctness of its responses to questions. This auxiliary model predicts the correctness of responses based solely on their consistent information. To set up the learning problem, we use a weighted graph to represent the consistency among the LLM's multiple responses to a question. Correctness labels are assigned to these responses based on their similarity to the correct answer. We then train a graph neural network to estimate the probability of correct responses. Experiments demonstrate that the proposed approach substantially outperforms several of the most recent methods in confidence calibration across multiple widely adopted benchmark datasets. Furthermore, the proposed approach significantly improves the generalization capability of confidence calibration on out-of-domain (OOD) data.