 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Threats in Stable Diffusion Models
Nov 15, 2023This paper introduces a novel approach to membership inference attacks (MIA) targeting stable diffusion computer vision models, specifically focusing on the highly sophisticated Stable Diffusion V2 by StabilityAI. MIAs aim to extract sensitive information about a model's training data, posing significant privacy concerns. Despite its advancements in image synthesis, our research reveals privacy vulnerabilities in the stable diffusion models' outputs. Exploiting this information, we devise a black-box MIA that only needs to query the victim model repeatedly. Our methodology involves observing the output of a stable diffusion model at different generative epochs and training a classification model to distinguish when a series of intermediates originated from a training sample or not. We propose numerous ways to measure the membership features and discuss what works best. The attack's efficacy is assessed using the ROC AUC method, demonstrating a 60\% success rate in inferring membership information. This paper contributes to the growing body of research on privacy and security in machine learning, highlighting the need for robust defenses against MIAs. Our findings prompt a reevaluation of the privacy implications of stable diffusion models, urging practitioners and developers to implement enhanced security measures to safeguard against such attacks.
Focused Adversarial Attacks
May 19, 2022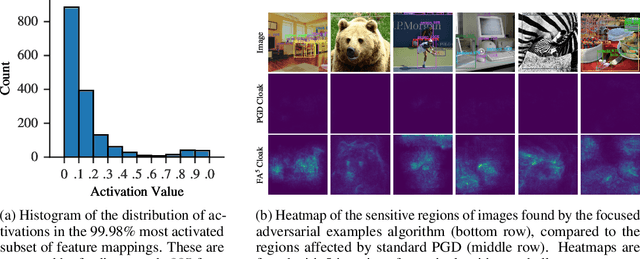

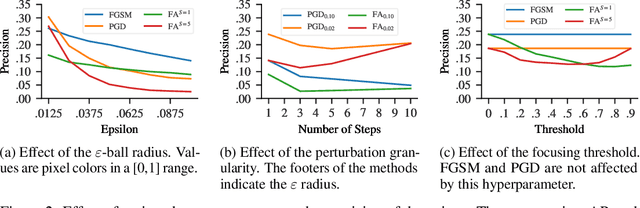

Recent advances in machine learning show that neural models are vulnerable to minimally perturbed inputs, or adversarial examples. Adversarial algorithms are optimization problems that minimize the accuracy of ML models by perturbing inputs, often using a model's loss function to craft such perturbations. State-of-the-art object detection models are characterized by very large output manifolds due to the number of possible locations and sizes of objects in an image. This leads to their outputs being sparse and optimization problems that use them incur a lot of unnecessary computation. We propose to use a very limited subset of a model's learned manifold to compute adversarial examples. Our \textit{Focused Adversarial Attacks} (FA) algorithm identifies a small subset of sensitive regions to perform gradient-based adversarial attacks. FA is significantly faster than other gradient-based attacks when a model's manifold is sparsely activated. Also, its perturbations are more efficient than other methods under the same perturbation constraints. We evaluate FA on the COCO 2017 and Pascal VOC 2007 detection datasets.
Preventing Personal Data Theft in Images with Adversarial ML
Oct 20, 2020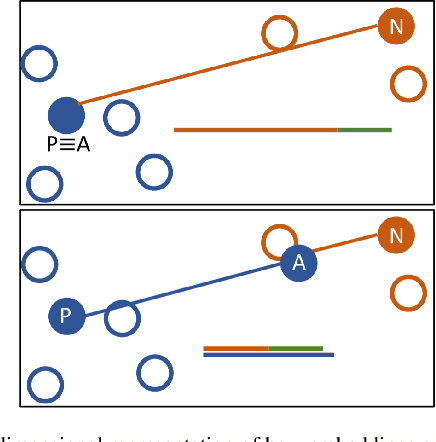
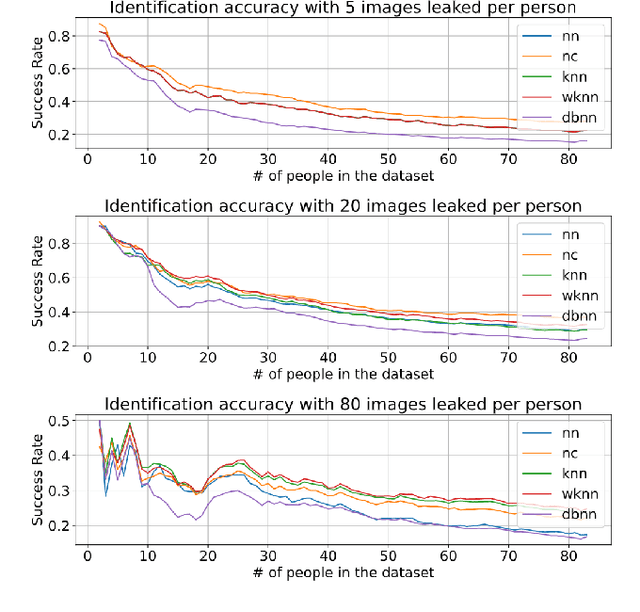
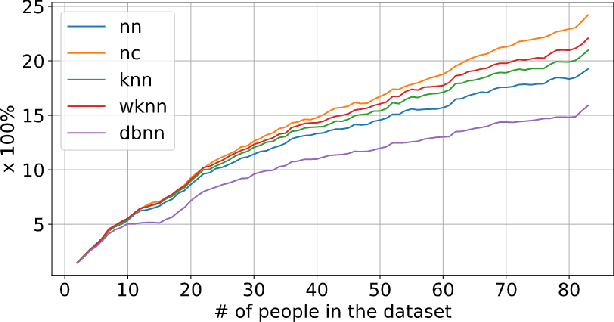

Facial recognition tools are becoming exceptionally accurate in identifying people from images. However, this comes at the cost of privacy for users of online services with photo management (e.g. social media platforms). Particularly troubling is the ability to leverage unsupervised learning to recognize faces even when the user has not labeled their images. This is made simpler by modern facial recognition tools, such as FaceNet, that use encoders to generate low dimensional embeddings that can be clustered to learn previously unknown faces. In this paper, we propose a strategy to generate non-invasive noise masks to apply to facial images for a newly introduced user, yielding adversarial examples and preventing the formation of identifiable clusters in the embedding space. We demonstrate the effectiveness of our method by showing that various classification and clustering methods cannot reliably cluster the adversarial examples we generate.