 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Adversarial Attacks
Paper and Code
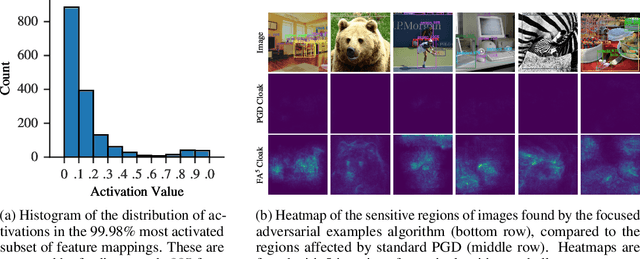

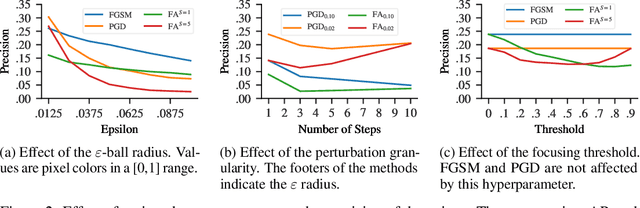

Recent advances in machine learning show that neural models are vulnerable to minimally perturbed inputs, or adversarial examples. Adversarial algorithms are optimization problems that minimize the accuracy of ML models by perturbing inputs, often using a model's loss function to craft such perturbations. State-of-the-art object detection models are characterized by very large output manifolds due to the number of possible locations and sizes of objects in an image. This leads to their outputs being sparse and optimization problems that use them incur a lot of unnecessary computation. We propose to use a very limited subset of a model's learned manifold to compute adversarial examples. Our \textit{Focused Adversarial Attacks} (FA) algorithm identifies a small subset of sensitive regions to perform gradient-based adversarial attacks. FA is significantly faster than other gradient-based attacks when a model's manifold is sparsely activated. Also, its perturbations are more efficient than other methods under the same perturbation constraints. We evaluate FA on the COCO 2017 and Pascal VOC 2007 detection datasets.