 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Integration Distillation for Object Detectors
Apr 02, 2024Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
Successive Model-Agnostic Meta-Learning for Few-Shot Fault Time Series Prognosis
Nov 04, 2023



Meta learning is a promising technique for solving few-shot fault prediction problems, which have attracted the attention of many researchers in recent years. Existing meta-learning methods for time series prediction, which predominantly rely on random and similarity matching-based task partitioning, face three major limitations: (1) feature exploitation inefficiency; (2) suboptimal task data allocation; and (3) limited robustness with small samples. To overcome these limitations, we introduce a novel 'pseudo meta-task' partitioning scheme that treats a continuous time period of a time series as a meta-task, composed of multiple successive short time periods. Employing continuous time series as pseudo meta-tasks allows our method to extract more comprehensive features and relationships from the data, resulting in more accurate predictions. Moreover, we introduce a differential algorithm to enhance the robustness of our method across different datasets. Through extensive experiments on several fault and time series prediction datasets, we demonstrate that our approach substantially enhances prediction performance and generalization capability under both few-shot and general conditions.
Steganalysis of Image with Adaptively Parametric Activation
Mar 24, 2022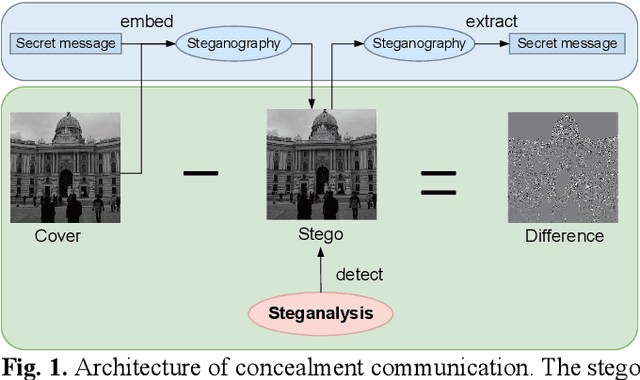
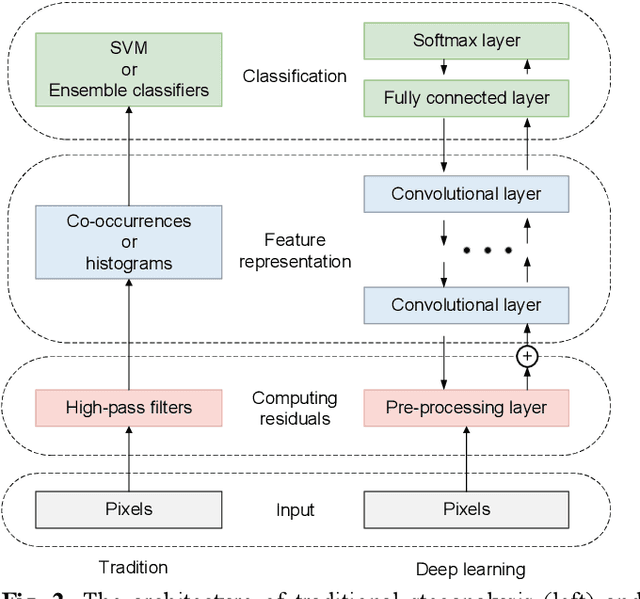
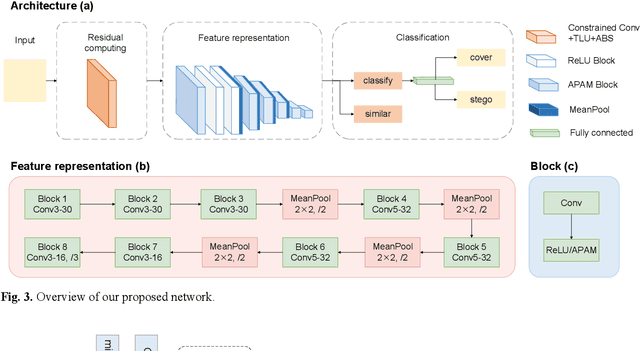
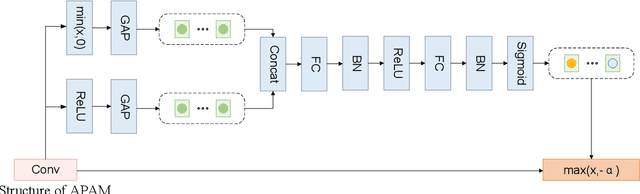
Steganalysis as a method to detect whether image contains se-cret message, is a crucial study avoiding the imperils from abus-ing steganography. The point of steganalysis is to detect the weak embedding signals which is hardly learned by convolution-al layer and easily suppressed. In this paper, to enhance embed-ding signals, we study the insufficiencies of activation function, filters and loss function from the aspects of reduce embedding signal loss and enhance embedding signal capture ability. Adap-tive Parametric Activation Module is designed to reserve nega-tive embedding signal. For embedding signal capture ability enhancement, we add constraints on the high-pass filters to im-prove residual diversity which enables the filters extracts rich embedding signals. Besides, a loss function based on contrastive learning is applied to overcome the limitations of cross-entropy loss by maximum inter-class distance. It helps the network make a distinction between embedding signals and semantic edges. We use images from BOSSbase 1.01 and make stegos by WOW and S-UNIWARD for experiments. Compared to state-of-the-art methods, our method has a competitive performance.
A Color Image Steganography Based on Frequency Sub-band Selection
Dec 29, 2021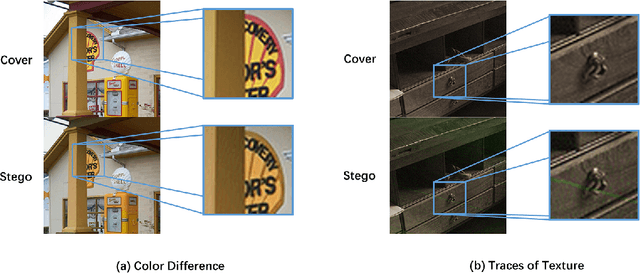
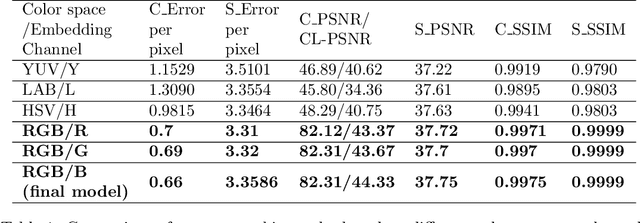

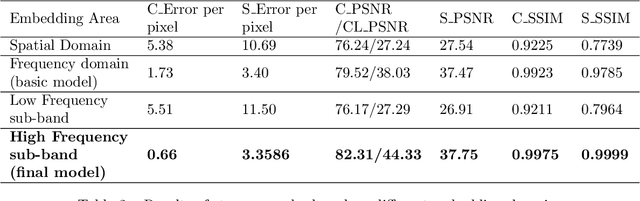
Color image steganography based on deep learning is the art of hiding information in the color image. Among them, image hiding steganography(hiding image with image) has attracted much attention in recent years because of its great steganographic capacity. However, images generated by image hiding steganography may show some obvious color distortion or artificial texture traces. We propose a color image steganographic model based on frequency sub-band selection to solve the above problems. Firstly, we discuss the relationship between the characteristics of different color spaces/frequency sub-bands and the generated image quality. Then, we select the B channel of the RGB image as the embedding channel and the high-frequency sub-band as the embedding domain. DWT(discrete wavelet transformation) transforms B channel information and secret gray image into frequency domain information, and then the secret image is embedded and extracted in the frequency domain. Comprehensive experiments demonstrate that images generated by our model have better image quality, and the imperceptibility is significantly increased.
Hard Example Guided Hashing for Image Retrieval
Dec 27, 2021

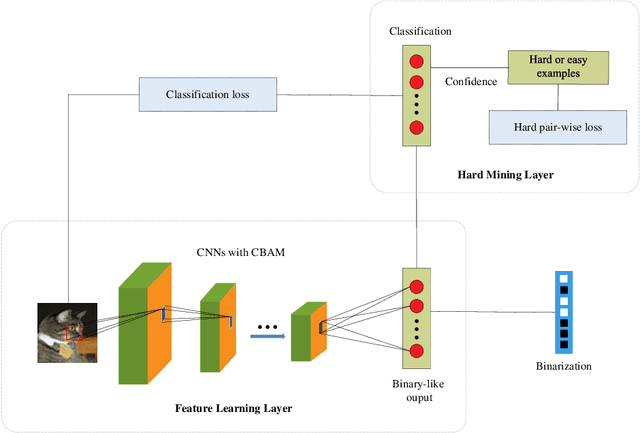

Compared with the traditional hashing methods, deep hashing methods generate hash codes with rich semantic information and greatly improves the performances in the image retrieval field. However, it is unsatisfied for current deep hashing methods to predict the similarity of hard examples. It exists two main factors affecting the ability of learning hard examples, which are weak key features extraction and the shortage of hard examples. In this paper, we give a novel end-to-end model to extract the key feature from hard examples and obtain hash code with the accurate semantic information. In addition, we redesign a hard pair-wise loss function to assess the hard degree and update penalty weights of examples. It effectively alleviates the shortage problem in hard examples. Experimental results on CIFAR-10 and NUS-WIDE demonstrate that our model outperformances the mainstream hashing-based image retrieval methods.
Recent Advances in the Applications of Convolutional Neural Networks to Medical Image Contour Detection
Aug 24, 2017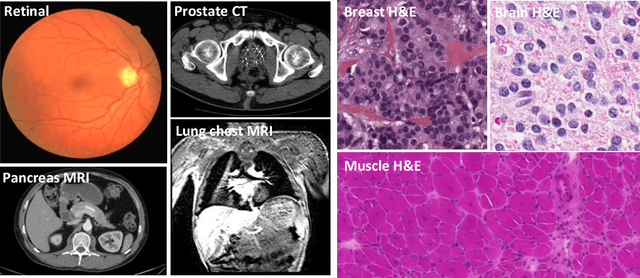
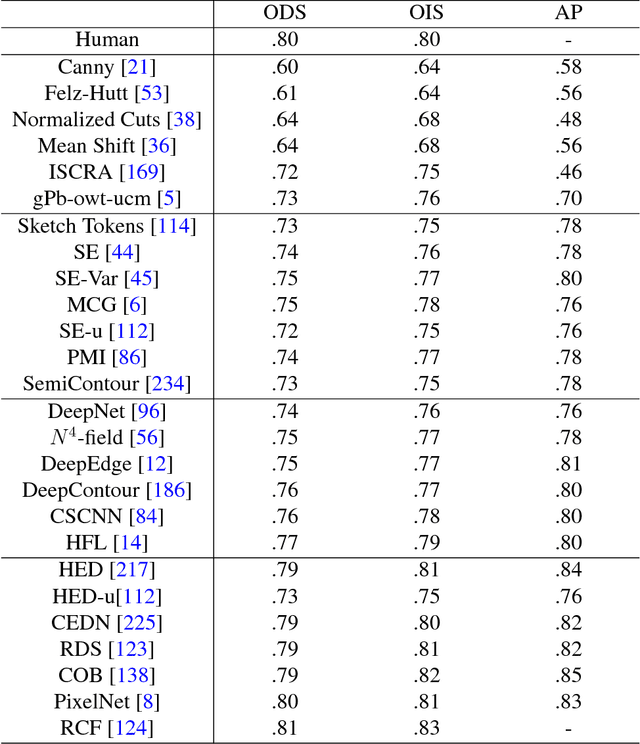
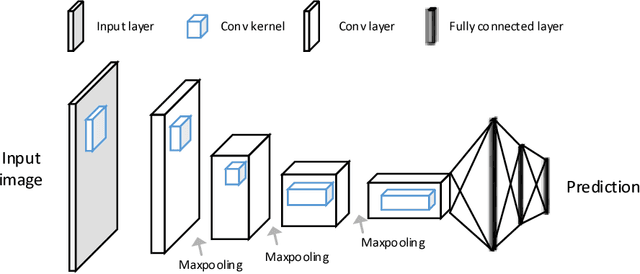
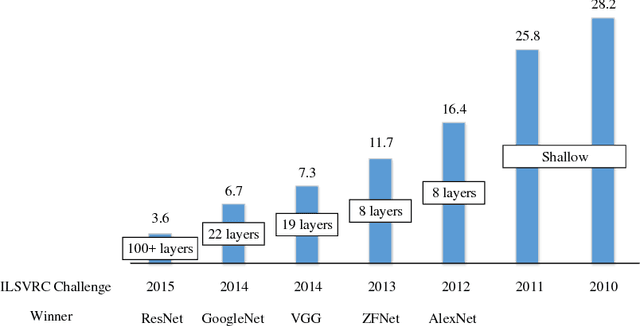
The fast growing deep learning technologies have become the main solution of many machine learning problems for medical image analysis. Deep convolution neural networks (CNNs), as one of the most important branch of the deep learning family, have been widely investigated for various computer-aided diagnosis tasks including long-term problems and continuously emerging new problems. Image contour detection is a fundamental but challenging task that has been studied for more than four decades. Recently, we have witnessed the significantly improved performance of contour detection thanks to the development of CNNs. Beyond purusing performance in existing natural image benchmarks, contour detection plays a particularly important role in medical image analysis. Segmenting various objects from radiology images or pathology images requires accurate detection of contours. However, some problems, such as discontinuity and shape constraints, are insufficiently studied in CNNs. It is necessary to clarify the challenges to encourage further exploration. The performance of CNN based contour detection relies on the state-of-the-art CNN architectures. Careful investigation of their design principles and motivations is critical and beneficial to contour detection. In this paper, we first review recent development of medical image contour detection and point out the current confronting challenges and problems. We discuss the development of general CNNs and their applications in image contours (or edges) detection. We compare those methods in detail, clarify their strengthens and weaknesses. Then we review their recent applications in medical image analysis and point out limitations, with the goal to light some potential directions in medical image analysis. We expect the paper to cover comprehensive technical ingredients of advanced CNNs to enrich the study in the medical image domain.